


基于 Milvus 构建音频相似性检索,其逻辑与上一篇以图搜图逻辑基本一致,区别在于音频数据的 embedding 方式
一、embedding
1.1 数据集
这里使用的数据集是:Mozilla Common Voice,最早2017年发布,持续更新,该基金会表示,通过 Common Voice 网站和移动应用,他们正在积极开展 70 种语言的数据收集工作。
Mozilla 宣称其拥有可供使用的最大的人类语音数据集,当前数据集有包括 29 种不同的语言,其中包括汉语,从 4万多名贡献者那里收集了近 2454 小时(其中1965小时已验证)的录音语音数据。并且做出了开放的承诺:向初创公司、研究人员以及对语音技术感兴趣的任何人公开我们收集到的高质量语音数据。
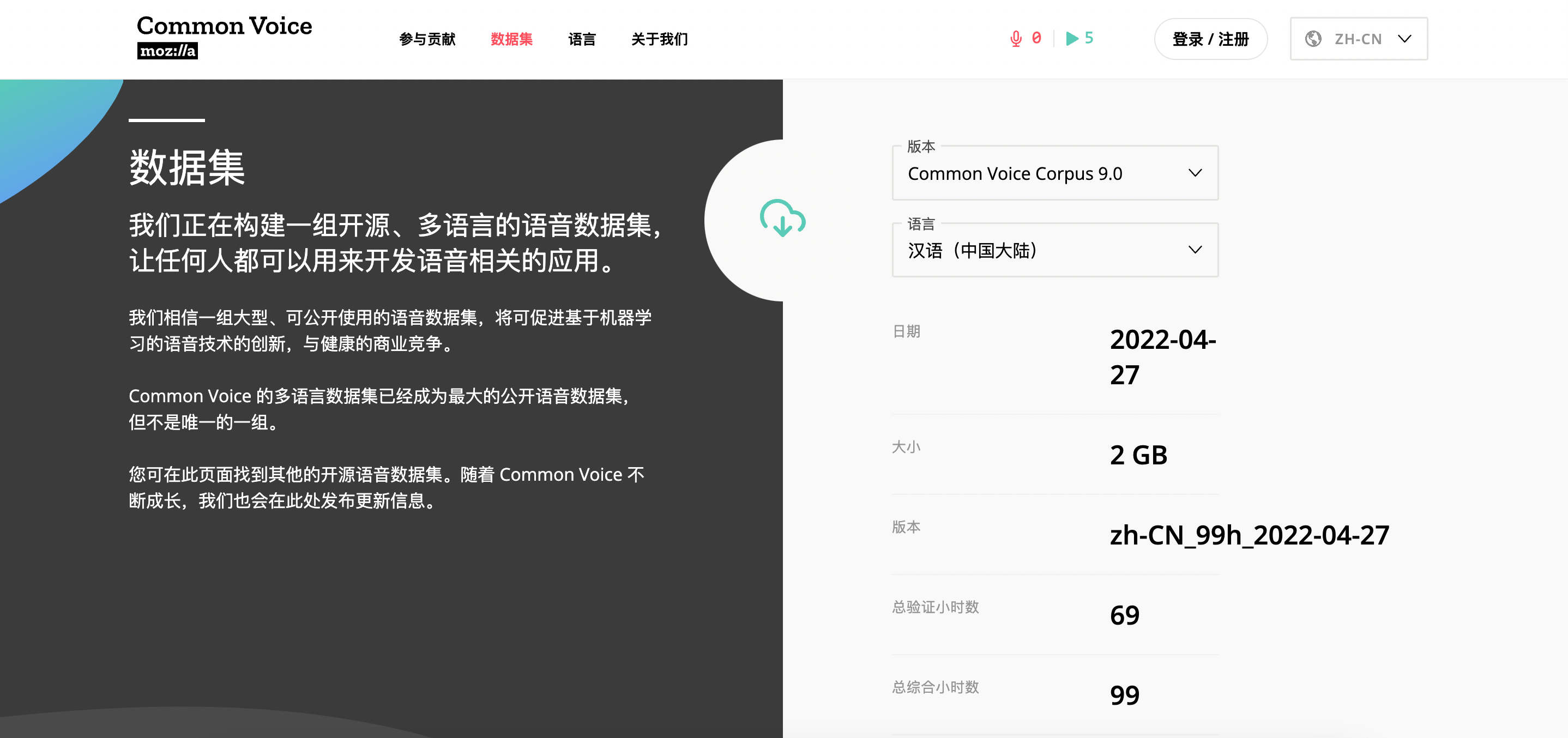
无需注册官网直接下载,也可以下载本次案例的数据集
1.2 panns
这里使用 panns(大规模预训练音频神经网络)将上述音频文件转换成向量数据。
Python 安装 panns 模块
pip install panns-inference
embedding 代码
# 提前下载好的训练模型
checkpoint_path = '../data/audio/Cnn14_mAP=0.431.pth'
def get_audio_embedding(path):
# Use panns_inference model to generate feature vector of audio
try:
RESAMPLE_RATE = 32000
audio, _ = librosa.core.load(path, sr=RESAMPLE_RATE, mono=True)
if audio.size < RESAMPLE_RATE:
audio = np.pad(audio, (0, RESAMPLE_RATE - audio.size), 'constant', constant_values=(0, 0))
audio = audio[None, :]
at = AudioTagging(checkpoint_path=checkpoint_path, device='cuda')
_, embedding = at.inference(audio)
embedding = embedding / np.linalg.norm(embedding)
embedding = embedding.tolist()[0]
return embedding
except Exception as e:
print(f"Error with embedding:{e}")
return None
首次运行会校验用户根目录下有没有 panns_data 目录,没有的话会自动下载训练好的模型,源码如下:
if not checkpoint_path:
checkpoint_path='{}/panns_data/Cnn14_mAP=0.431.pth'.format(str(Path.home()))
print('Checkpoint path: {}'.format(checkpoint_path))
if not os.path.exists(checkpoint_path) or os.path.getsize(checkpoint_path) < 3e8:
create_folder(os.path.dirname(checkpoint_path))
zenodo_path = 'https://zenodo.org/record/3987831/files/Cnn14_mAP%3D0.431.pth?download=1'
os.system('wget -O "{}" "{}"'.format(checkpoint_path, zenodo_path))
注:相信自己的网速可以在首次运行的时候让程序自动下载,否则可以挂梯子提前下载好,或者联系作者
这里 embedding 的逻辑和上一篇以图搜图的逻辑一样,将 embedding 的结果进行序列化,最终代码如下:
import librosa
from panns_inference import AudioTagging
import numpy as np
import os
import pickle
checkpoint_path = '../data/audio/Cnn14_mAP=0.431.pth'
audio_path = '../data/audio/clips'
def get_audio_embedding(path):
# Use panns_inference model to generate feature vector of audio
try:
RESAMPLE_RATE = 32000
audio, _ = librosa.core.load(path, sr=RESAMPLE_RATE, mono=True)
if audio.size < RESAMPLE_RATE:
audio = np.pad(audio, (0, RESAMPLE_RATE - audio.size), 'constant', constant_values=(0, 0))
audio = audio[None, :]
at = AudioTagging(checkpoint_path=checkpoint_path, device='cuda')
_, embedding = at.inference(audio)
embedding = embedding / np.linalg.norm(embedding)
embedding = embedding.tolist()[0]
return embedding
except Exception as e:
print(f"Error with embedding:{e}")
return None
def get_audio_path():
return [audio_path + "/" + _tmp1 for _tmp1 in os.listdir(audio_path)]
if __name__ == '__main__':
# [get_audio_embedding(audio_path + "/" + _tmp) for _tmp in os.listdir(audio_path)]
listdir = os.listdir(audio_path)
_sum = len(listdir)
_count = 0
result = []
for _tmp in listdir:
_embedding = get_audio_embedding(audio_path + "/" + _tmp)
result.append(_embedding)
_count += 1
print(f"进度:{_count}/{_sum}")
# 序列化
print("开始序列化 embedding")
# 序列化 embedding 结果
f = open("audio_vector.pkl", "wb")
pickle.dump(result, f)
f.flush()
f.close()
运行中可能会遇到:OSError: cannot load library xxx/xxx/_soundfile_data/xxx
解决方案:根据报错的提示手动创建 _soundfile_data,然后去 https://github.com/bastibe/libsndfile-binaries 中下载对应版本的文件拷贝到 _soundfile_data 即可
二、server
将基于 panns embedding 的向量存储到 Milvus 中,Milvus 会自动为每一个向量分配唯一 id,将 id 与音频文件路径存储到 mysql 中即可。代码如下:
from pymilvus import CollectionSchema, FieldSchema, DataType, utility, connections, Collection
import pymysql
import pickle
import logging
import os
# ----------------------------------------------------------------------------------------------------------------------
# 构建日志
logging.getLogger(__name__).addHandler(logging.NullHandler())
logger = logging.getLogger()
handler = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s [%(levelname)-5s] %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# ----------------------------------------------------------------------------------------------------------------------
# 反序列化
file = open('audio_vector.pkl', 'rb')
vectors = pickle.load(file)
file.close()
logger.info(f"序列化完成,加载数据量:{len(vectors)}")
# 获取一下音频文件路径
listdir = os.listdir('../data/audio/clips')
# ----------------------------------------------------------------------------------------------------------------------
# collection name
collection_name = 'search_audio'
# 维度
dim = len(vectors[0])
# 构建 collection 的 schema 信息
# 主键字段
audio_id = FieldSchema(name='audio_id', dtype=DataType.INT64, auto_id=True, is_primary=True, description='音频id')
# 向量字段
audio_vector = FieldSchema(name='audio_vector', dtype=DataType.FLOAT_VECTOR, dim=dim, description='音频向量')
# 构建 Collection
schema = CollectionSchema(fields=[audio_id, audio_vector], description='音频相似搜索')
# ----------------------------------------------------------------------------------------------------------------------
# milvus 别名
alias = "default"
# milvus ip
host = "192.168.0.98"
# milvus port
port = "19530"
# 连接 milvus
connections.connect(host=host, port=port, alias=alias)
logger.info("连接 milvus")
# 判断待构建的 collection 是否存在,不存在创建
if utility.has_collection(collection_name):
logger.info(f"集合 {collection_name} 已存在")
else:
logger.info(f"集合 {collection_name} 不存在,开始创建", )
Collection(name=collection_name, schema=schema, consistency_level='Strong')
collection = Collection(collection_name)
# ----------------------------------------------------------------------------------------------------------------------
# 连接 mysql
host = '127.0.0.1'
port = 3306
user = 'root'
password = '980729'
connect = pymysql.connect(host=host, port=port, user=user, password=password)
logger.info("连接 mysql")
cursor = connect.cursor()
insert_sql = "insert into milvus_search.audio_meta(id,path) values('%s','%s')"
for index in range(len(vectors)):
try:
mr = collection.insert([[vectors[index]]])
cursor.execute(insert_sql % (mr.primary_keys[0], listdir[index]))
logger.info(f"进度:{index}/{len(vectors)}")
connect.commit()
except Exception as e:
logger.error(f"执行错误{e}")
# 关闭连接
connections.disconnect(alias=alias)
logger.info("关闭 milvus 连接")
connect.close()
logger.info("关闭 mysql 连接")
logger.info("服务端构建完成")
可通过 attu 查看 collection 状态
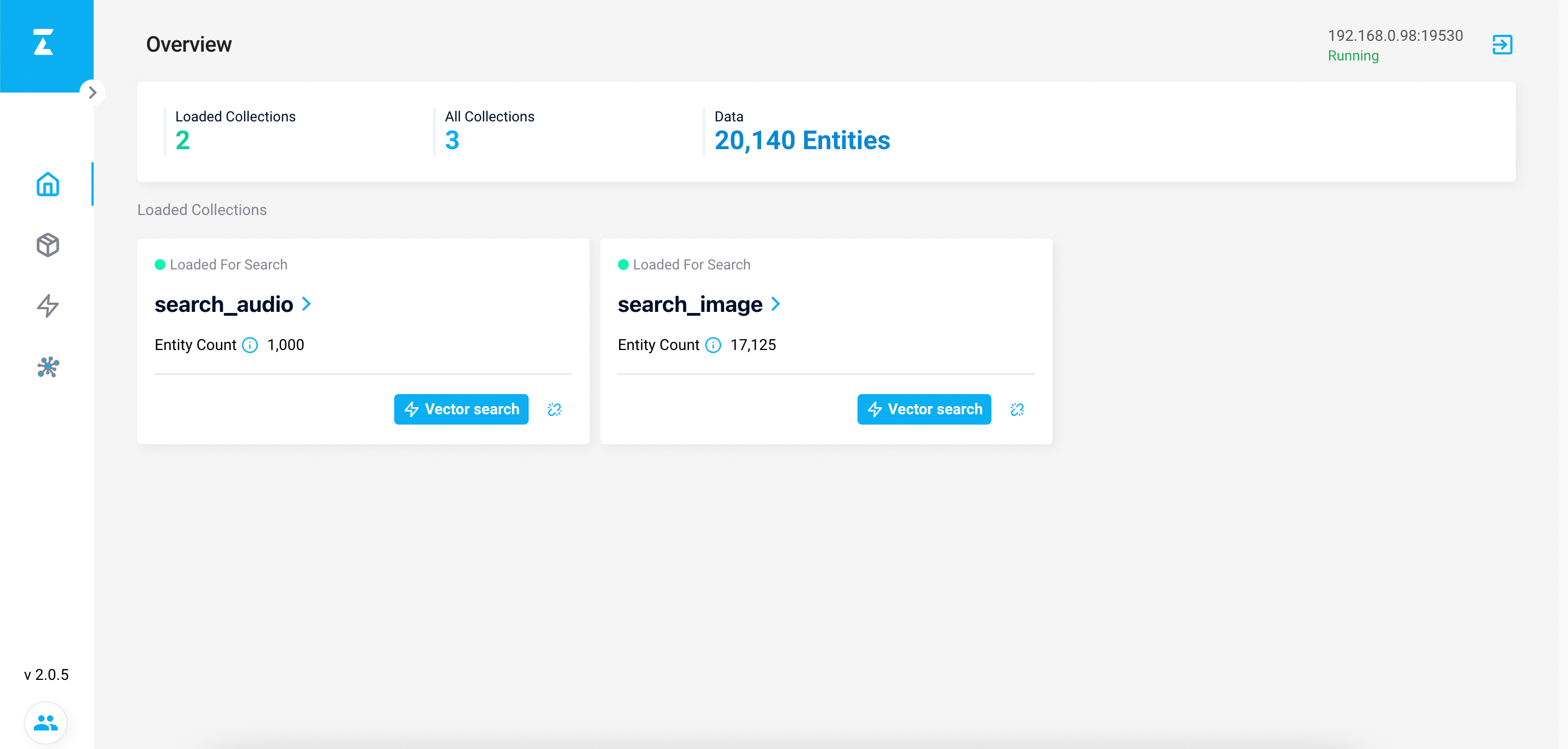
collection 一定要处于 load 状态,不然无法提供查询功能
三、client
客户端上传音频文件,通过 panns embedding 成向量后通过与 Milvus 存储的向量进行检索返回若干个 ids,并通过 id 从 mysql 中获取音频文件的存储路径,代码如下:
import playsound
from pymilvus import connections, Collection
import pymysql
from audio_embedding import get_audio_embedding
audio_path = '../data/audio/clips/common_voice_zh-CN_18531660.mp3'
vector = get_audio_embedding(audio_path)
# milvus 别名
alias = "default"
# milvus ip
host = "192.168.0.98"
# milvus port
port = "19530"
collection_name = 'search_audio'
# 连接 milvus
connections.connect(host=host, port=port, alias=alias)
# 连接 mysql
host = '127.0.0.1'
port = 3306
user = 'root'
password = '980729'
connect = pymysql.connect(host=host, port=port, user=user, password=password)
collection = Collection(collection_name)
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
result = collection.search(data=[list(vector)], anns_field='audio_vector', param=search_params, limit=5,
consistency_level='Strong')
cursor = connect.cursor()
sql = ""
if len(result[0].ids) == 0:
print("没有匹配项")
exit(0)
elif len(result[0].ids) == 1:
sql = "select path from milvus_search.audio_meta where id = '%s'" % str(result[0].ids[0])
else:
sql = "select path from milvus_search.audio_meta where id in %s" % str(tuple([f"{_id}" for _id in result[0].ids]))
cursor.execute(sql)
# 播放原始音频
playsound.playsound(audio_path)
for audio_id in cursor.fetchall():
print(f'播放匹配的音频:{audio_id[0]}')
playsound.playsound(f'../data/audio/clips/{audio_id[0]}')
其最终的检索出来的结果跟偏向于音色的相似度,至于音频中所表述的意思 embedding 的效果似乎不是很好,希望后续可以找到基于语音语义的 embedding 算法
这里通过 playsound 模块进行 mp3 音频的播放,直接 pip install playsound 安装即可,但遇到 no modules Appkit 错误(环境:mac for m1)
解决方案:不要视图通过 pip install Appkit 来安装都是坑,直接 pip install --upgrade --force-reinstall PyObjC PyObjC-core 等待安装完成即可

至此任务进度 2/8
评论区