


Milvus 致力于存储、索引和管理由深度神经网络学习与其他机器学习模型生成的海量 Embedding 向量,并专门为向量查询与检索设计,能够为万亿级向量数据建立索引。与现有的主要用作处理结构化数据的关系型数据库不同,Milvus 在底层设计上就是为了处理由各种非结构化数据转换而来的 Embedding 向量而生
摘自中文官方文档
本文主要分为两章,分别为 Milvus 入门篇和 Milvus 实战篇,其中入门篇你可以学到:Milvus 基本架构、安装部署、简单使用;实战篇为:采集近 2w 张实景图片以 python 为基础结合 towhee、opencv、mysql 构建以图搜图案例。祝你快速入门 Milvus 并付诸生产
一、入门篇
1.1 几个重要概念
1.1.1 Milvus
首先 Milvus 是一款云原生的数据库产品;其次 Milvus 主要存储的数据为 embedding vector,不同于传统数据库存储结构化数据,Milvus 主要存储诸如:图片、视频、语音等非结构化数据,但 Milvus 并不是直接将非结构化的数据存储起来,而是需要借助机器学习、深度学习将非结构化数据 embedding 成向量后再存储;最后 Milvus 负责对给定的向量去检索存储在 Milvus 中与给定向量距离最近的若干个向量。
因此 Milvus 是一款存储向量,并提供计算两个向量之间相似性(距离)的数据库产品
架构如下:
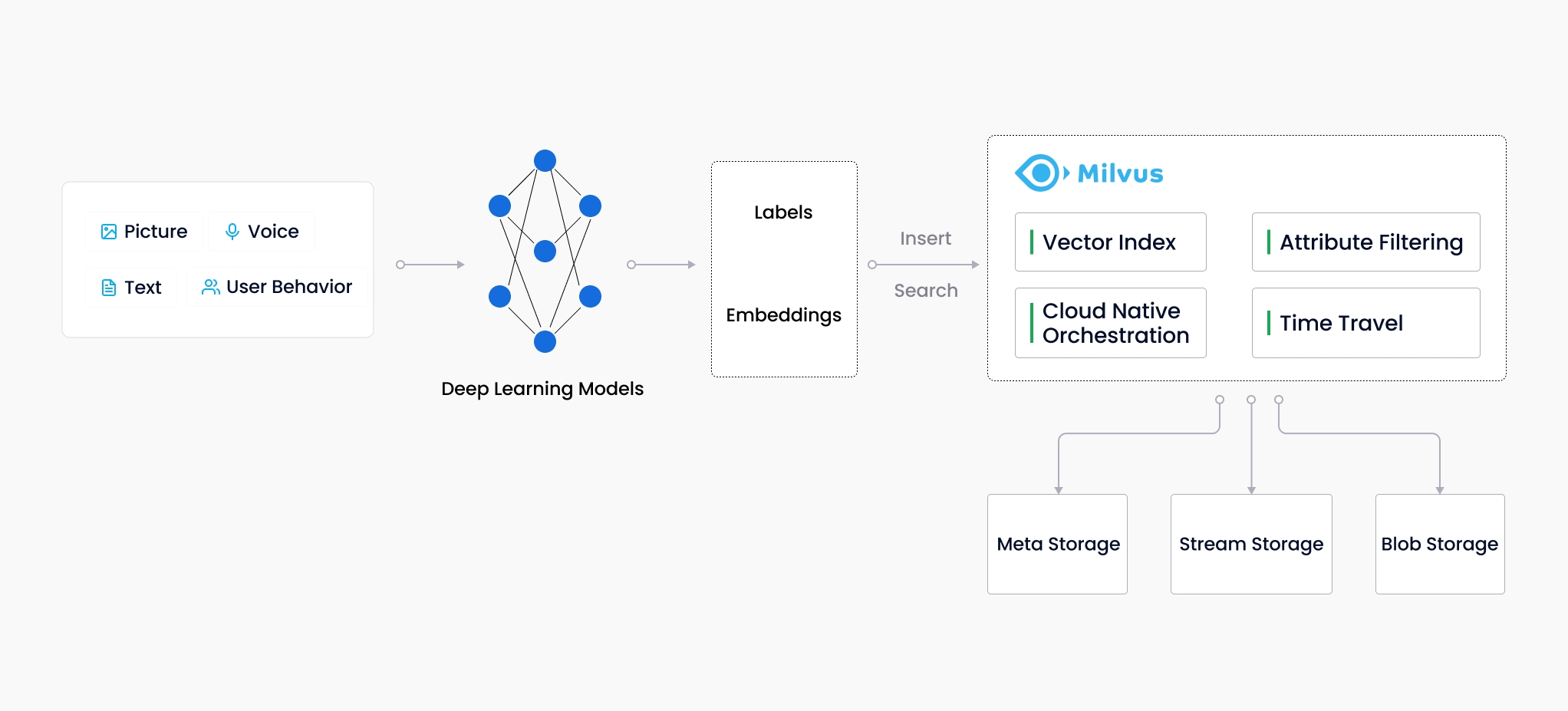
总结下来 Milvus 并不是特别复杂的数据库,只做了两件事:储存向量、计算向量距离
这里的向量就是数学意义上的向量
1.1.2 Collection
包含一组 Entity,对标传统数据库的表
1.1.3 Entity
包含一组 Field,对标传统数据库的行
1.1.4 Field
与实际对象相对应。field 可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。primary key 是用于指代一个 entity 的唯一值。Entity 的组成部分,Field 可以是结构化数据,例如数字和字符串,也可以是向量。对标传统数据库的列、字段
1.1.5 Partition
Milvus 允许将大量的向量数据划分成一定数量的 Partition,可以将搜索和其他操作限制在特定的 Partition 上来提高性能,一个 Collection 由一个或多个 Partition 构成,默认一个 Partition
1.1.6 Schema
定义数据类型和数据属性的元信息,每个 Collection 在创建时都需要定义 Schema
1.1.7 Sharding
将数据写入操作分散到不同节点上,使 Milvus 能充分利用集群的并行计算能力进行写入。默认情况下单个 collection 包含 2 个分片,并采用主键 hash 方式。
Partition 的意义在于通过划定分区减少数据读取,而 sharding 的意义在于多台机器上并行写入操作。
1.2 系统架构
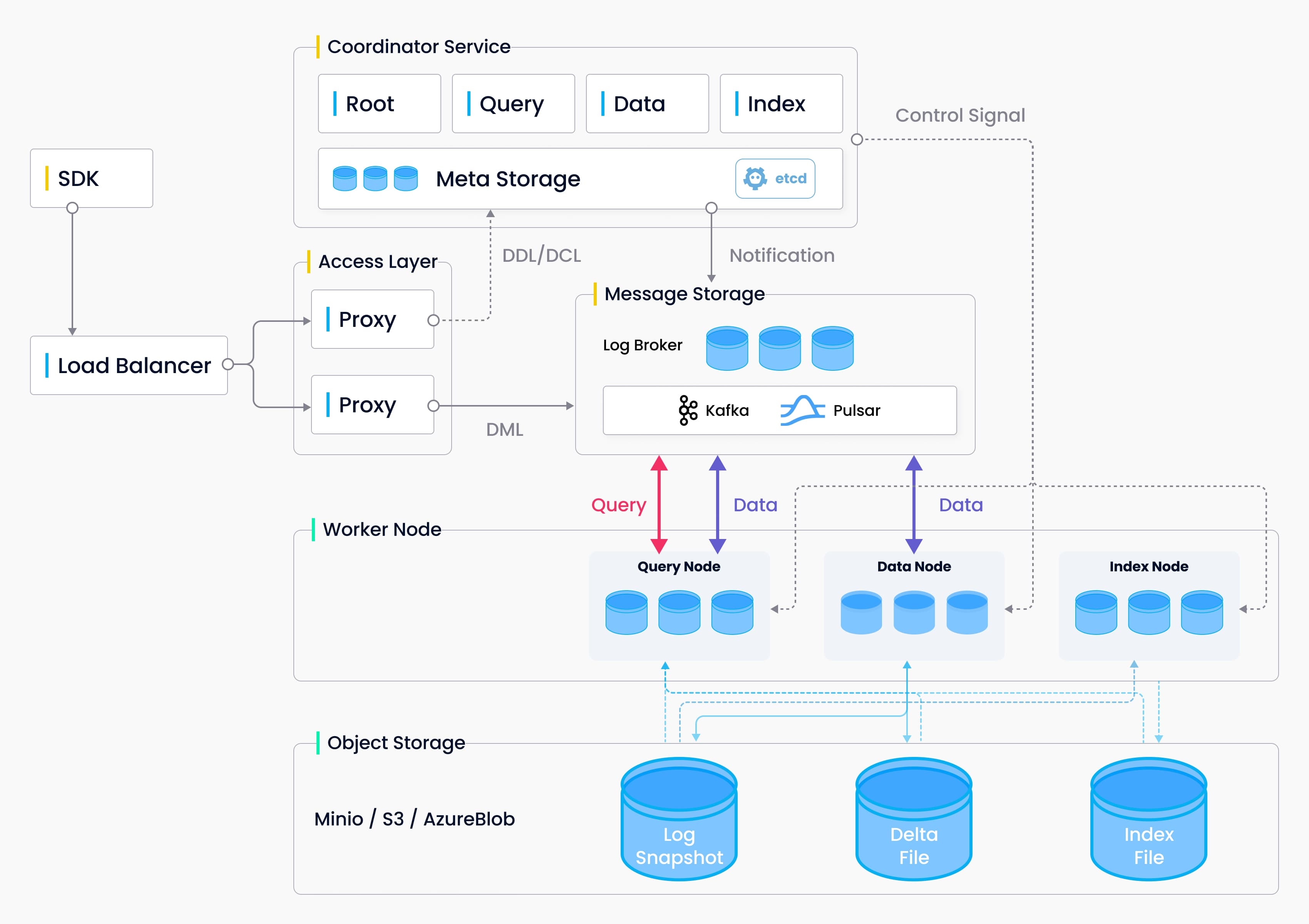
Milvus 采用存算分离的架构,所有组件均是无状态组件,整个系统分为四个层面
- Access Layer:接入层,由一组无状态的 proxy 组成,对外提供客户端的连接终端,负责验证客户端请求和返回请求结果
- Coordinator Service:协调服务层,负责分配任务给执行节点,目前有四个角色:root coord、data coord、query coord 和 index coord
- Worker Node:计算层,执行节点负责完成 Coordinator Service 下发的指令,目前有三个角色:data node、query node 和 index node
- Storage:存储层,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分
架构图如下:
1.3 距离公式
Milvus 基于不同的距离计算方式比较向量间的距离。根据插入数据的形式,选择合适的距离计算方式能极大地提高数据分类和聚类性能,Milvus 支持存储浮点型向量和二进制向量,其中:
浮点型向量支持的距离公式
| 距离公式 | 备注 | 描述 |
|---|---|---|
| L2 | 欧式距离 | 主要运用于计算机视觉领域 |
| IP | 内积 | 主要运用于自然语言处理领域 |
二进制向量支持的距离公式
| 距离公式 | 描述 |
|---|---|
| Hamming | 主要运用于自然语言处理领域 |
| Jaccard | 主要运用于化学分子式检索领域 |
| Tanimoto | 主要运用于化学分子式检索领域 |
| Superstructure | 主要运用于检索化学分子式的相似超结构 |
| Substructure | 主要运用于检索化学分子式的相似子结构 |
1.4 安装部署
前提条件
- CPU:8 核起步,暂不支持 AMD 和 Apple M1
- CPU指令集:SSE4.2、AVX、AVX2、AVX-512,至少包含一个
- 内存:取决于数据量
- 硬盘:取决于数据量
- Docker >= 19.03
- Docker Compose >= 1.25.1
Milvus 采用 Docker Compose 方式安装部署,因此单机版和分布式版的安装部署只是 docker-compose.yml 不同
单机版下载地址:
分布式下载地址:
注:下载完记得修改文件名称为 docker-compose.yml
启动方式
docker-compose up -d
停止方式
docker-compose down
1.5 SDK
支持 python、java、go、node.js,建议使用 python
pip install pymilvus
Mac m1 需要通过如下方式安装
通过 brew 安装 openssl
brew install openssl
再安装 pymilvus
CFLAGS="-I/opt/homebrew/opt/openssl/include" LDFLAGS="-L/opt/homebrew/opt/openssl/lib" GRPC_PYTHON_BUILD_SYSTEM_OPENSSL=1 GRPC_PYTHON_BUILD_SYSTEM_ZLIB=1 pip install pymilvus
1.6 客户端
Attu 是 Milvus 的高效开源管理工具. 它具有直观的图形用户界面 (GUI),可让您轻松与数据库进行交互。 只需点击几下,您就可以可视化集群状态、管理元数据、执行数据查询等等。
下载地址:
1.7 简单使用
1.7.1 连接 Milvus
from pymilvus import connections
# milvus 别名
alias = "default"
# milvus ip
host = "121.199.45.82"
# milvus port
port = "19530"
# 连接 milvus
connections.connect(host=host, port=port, alias=alias)
# 关闭连接
connections.disconnect(alias=alias)
注:alias 默认值为 default,可以不指定,若指定 alias 不为 default 则后续所有的操作都需要加上 alias 参数
1.7.2 创建 Collection
构建 Collection 信息
from pymilvus import CollectionSchema, FieldSchema, DataType
book_id = FieldSchema(
name="book_id",
dtype=DataType.INT64,
is_primary=True
)
word_count = FieldSchema(
name="word_count",
dtype=DataType.INT64
)
book_intro = FieldSchema(
name="book_intro",
dtype=DataType.FLOAT_VECTOR,
dim=2
)
schema = CollectionSchema(
fields=[book_id, word_count, book_intro],
description="Test book search"
)
collection_name = "book"
参数解释如下:
| 参数 | 描述 | 解释 |
|---|---|---|
| FieldSchema | Field 的 schema 信息 | N/A |
| name | Field 的名字 | N/A |
| dtype | Field 的数据类型 | 对于主键字段:Datatype.INT64 对于标量字段:Datatype.BOOL,Datatype.INT64,Datatype.FLOAT,Datatype.DOUBLE 对于向量字段:BINARY_VECTOR,FLOAT_VECTOR |
| is_primary | 是否是主键 | TRUE、FALSE(主键字段必填) |
| dim | 维度 | 1~32768(向量字段必填) |
| description | 描述 | 可选 |
| CollectionSchema | Collection 的 schema 信息 | N/A |
| fields | 约定 Collection 的 Field | N/A |
| collection_name | Collection 名称 | N/A |
创建 Collection
from pymilvus import Collection
collection = Collection(
name=collection_name,
schema=schema,
using='default',
shards_num=2,
consistency_level="Strong"
)
consistency_level:指定一致性级别
1.7.3 插入数据
例如,上述创建了一个名为 book 的 Collection,一个主键字段(Milvus不会对主键字段做校验),一个标量字段,一个二维的浮点型向量。首先构建数据
import random
data = [
[i for i in range(2000)],
[i for i in range(10000, 12000)],
[[random.random() for _ in range(2)] for _ in range(2000)],
]
插入数据
from pymilvus import Collection
collection = Collection("book")
mr = collection.insert(data)
1.7.4 查询数据
Milvus 中的所有搜索和结构化匹配操作都在内存中执行。在执行向量相似性搜索之前将 collection 加载到内存中
加载 Collection 到内存
from pymilvus import Collection
collection = Collection("book")
collection.load()
准备搜索参数,即指定使用哪种距离公式,例如这里使用 L2
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
metric_type:指定距离公式
params:指定的距离公式中特有的参数
进行数据查询
results = collection.search(
data=[[0.1, 0.2]],
anns_field="book_intro",
param=search_params,
limit=10,
expr=None,
consistency_level="Strong"
)
data:给定的的向量
anns_field:向量字段名
limit:返回的数据量
expr:混合查询,如 word_count < 10
最终的结果
# 主键id
results[0].ids
# 与给定向量的距离
results[0].distances
搜索完成时释放 Milvus 中加载的 collection 以减少内存消耗
collection.release()
二、实战篇
2.1 项目架构
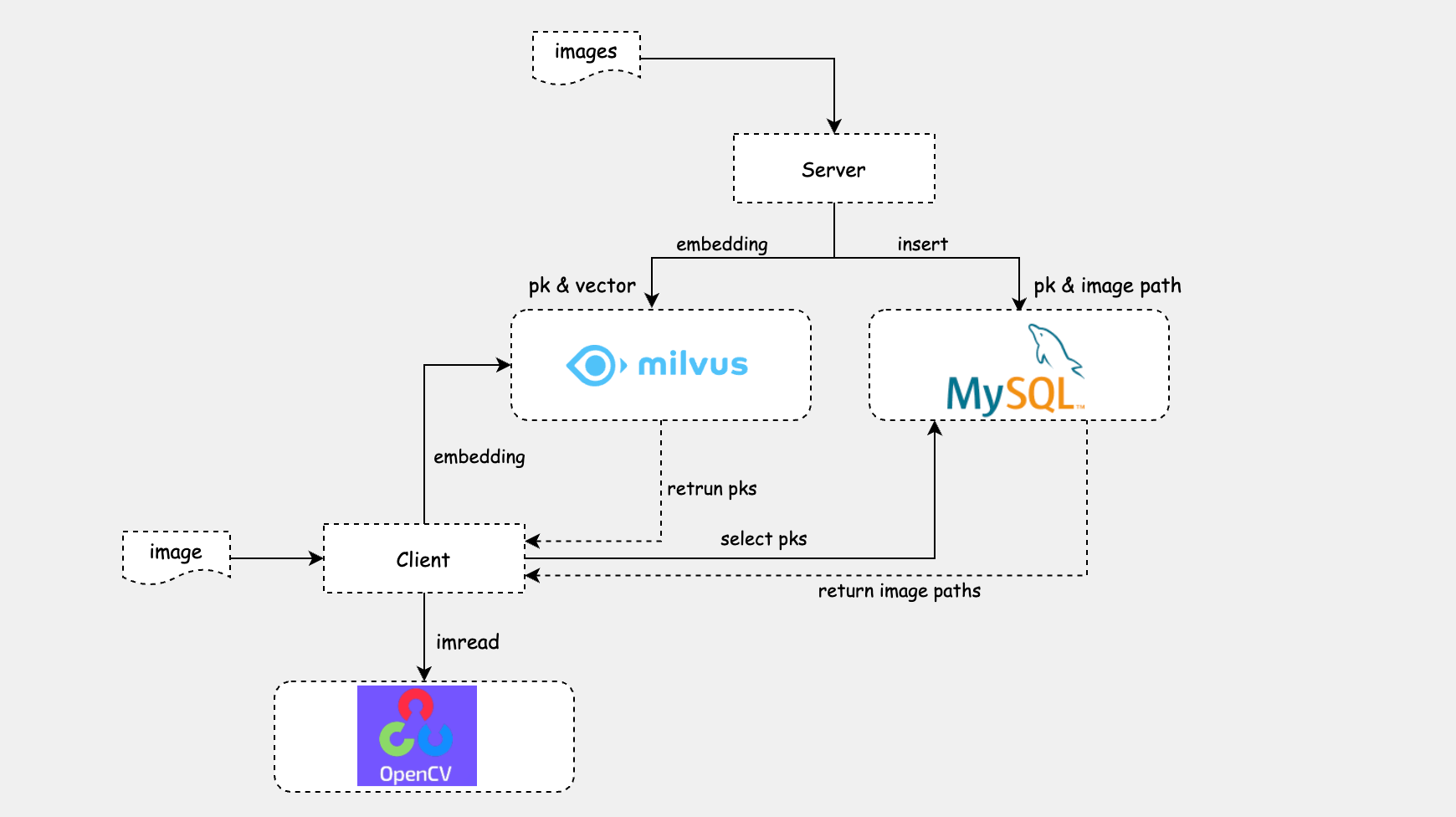
基于 Milvus 实现以图搜图的案例,其基本原理为:
服务端:借助于机器学习将图片进行 embedding 转换成向量并为其生成一个主键,将主键和源图片地址存储到 mysql 中,将主键和图片向量存储到 Milvus 中完成服务端构建
客户端:客户端提供一张图片并将其 embedding 成向量,客户端执行 Milvus 数据查询获取返回的主键 id,根据主键 id 从 mysql 中获取源图片的地址,基于 opencv 进行展示
架构图如下:
2.2 代码实现
2.2.1 embedding
Towhee 是一个灵活的、面向应用程序的框架,用于通过 ML 模型和其他操作的管道生成嵌入向量。它旨在使 x2vec 民主化,让每个人从初学者开发人员到大型组织——只用几行代码就可以生成密集的嵌入。
python 安装 towhee
pip install towhee
准备图片
图片批量 embedding 代码实现,基于算法:ResNet-50
from towhee import pipeline
from rich.progress import track
import os
import pickle
base_path = '/Users/wjun/Downloads/学习资料/JPEGImages/'
# 构建 embedding 模型
pipline = pipeline('image-embedding')
# 获取图片的本地路径
img_path = [base_path + path for path in os.listdir(base_path)]
# 控制台构建一个进度条用于观察进度
vector = [pipline(path) for path in track(img_path, description="Embedding...")]
print("图片 embedding 完成")
# 序列化 embedding 结果
f = open("vector.pkl", "wb")
pickle.dump(vector, f)
f.flush()
f.close()
track:主要用于生成进度条,除此之外没有任何意义
pickle:序列化与反序列化,保存 embedding 得到的向量数组,因为此过程相当耗时
注:towhee 首次运行会相当耗时同时下载大量依赖和算法模型保存到本地,注意与 github 的连通性;towhee 最终将图片 embedding 成一个 2048 维的向量
2.2.2 向量的存储
服务端
step-0.构建日志
import logging
# ----------------------------------------------------------------------------------------------------------------------
# 构建日志
logging.getLogger(__name__).addHandler(logging.NullHandler())
logger = logging.getLogger()
handler = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s [%(levelname)-5s] %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
step-1.将 embedding 的结果进行反序列化
# ----------------------------------------------------------------------------------------------------------------------
# 反序列化
file = open('vector.pkl', 'rb')
vectors = pickle.load(file)
file.close()
logger.info("序列化完成,加载数据量:%d", len(vectors))
step-2.构建主键id(increase-localPath)
# ----------------------------------------------------------------------------------------------------------------------
# 给数据添加主键id
base_path = '/Users/wjun/Downloads/学习资料/JPEGImages/'
img_path = [base_path + path for path in os.listdir(base_path)]
pk = [str(i) + "-" + img_path[i] for i in range(len(vectors))]
# 将主键与向量进行zip
data = dict(zip(pk, vectors))
logger.info("为向量生成主键id")
step-3.构建 Milvus 的 Collection
# ----------------------------------------------------------------------------------------------------------------------
# collection name
collection_name = 'search_image'
# 维度
dim = vectors[0].shape[0]
# 构建 collection 的 schema 信息
# 主键字段
image_id = FieldSchema(name='image_id', dtype=DataType.INT64, is_primary=True, description='图片id')
# 向量字段
image_vector = FieldSchema(name='image_vector', dtype=DataType.FLOAT_VECTOR, dim=dim, description='图片向量')
# 构建 Collection
schema = CollectionSchema(fields=[image_id, image_vector], description='以图搜图')
step-4.创建 Collection
# ----------------------------------------------------------------------------------------------------------------------
# milvus 别名
alias = "default"
# milvus ip
host = "127.0.0.1"
# milvus port
port = "19530"
# 连接 milvus
connections.connect(host=host, port=port, alias=alias)
logger.info("连接 milvus")
# 判断待构建的 collection 是否存在,不存在创建
if utility.has_collection(collection_name):
logger.info("集合 %s 已存在", collection_name)
else:
logger.info("集合 %s 不存在,开始创建", collection_name)
Collection(name=collection_name, schema=schema, consistency_level='Strong')
collection = Collection(collection_name)
step-5.连接 mysql
# ----------------------------------------------------------------------------------------------------------------------
# 连接 mysql
host = '127.0.0.1'
port = 3306
user = 'root'
password = '980729'
connect = pymysql.connect(host=host, port=port, user=user, password=password)
logger.info("连接 mysql")
cursor = connect.cursor()
insert_sql = "insert into milvus_search.meta(id,path) values('%s','%s')"
step-6.数据写入 Milvus 和 MySQL
# ----------------------------------------------------------------------------------------------------------------------
# 插入数据,同时插入mysql和milvus
try:
for key, value in track(data.items(), description="Insert..."):
pk, path = key.split("-")
# 元数据写入 mysql
cursor.execute(insert_sql % (pk, path))
collection.insert([
[int(pk)],
[list(value)]
])
# 向量数据写入 milvus
# logger.info("insert milvus")
# 批量插入
# collection.insert([
# [int(keys.split("-")[0]) for keys in data.keys()][1:1000],
# list(data.values())[1:1000]])
connect.commit()
except Exception as e:
logger.error("错误回滚:" + str(e))
connect.rollback()
step-7.关闭连接
# 关闭连接
connections.disconnect(alias=alias)
logger.info("关闭 milvus 连接")
connect.close()
logger.info("关闭 mysql 连接")
logger.info("服务端构建完成")
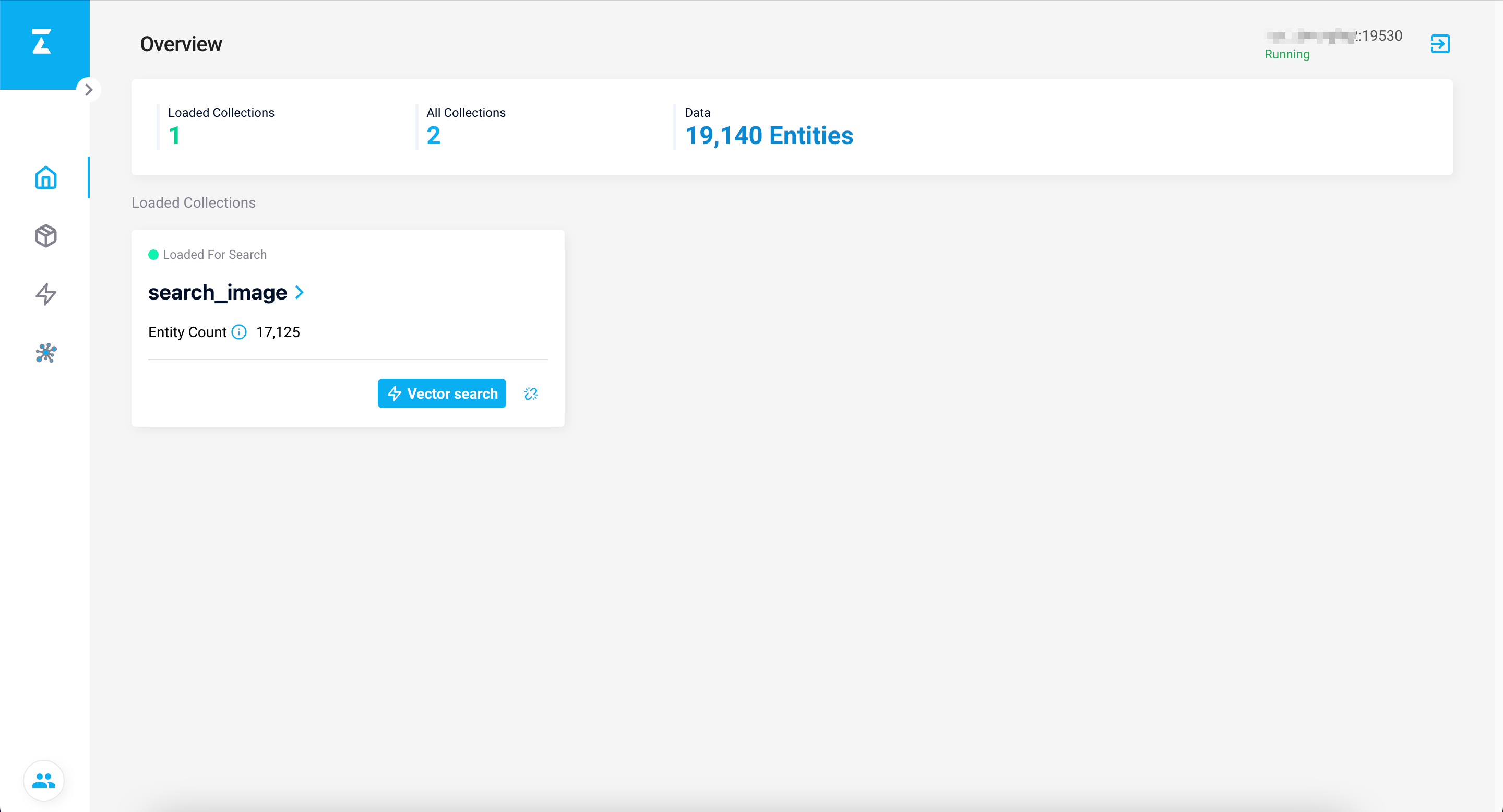
最终运行结果如下(耗时:1h):

Attu 结果如下:
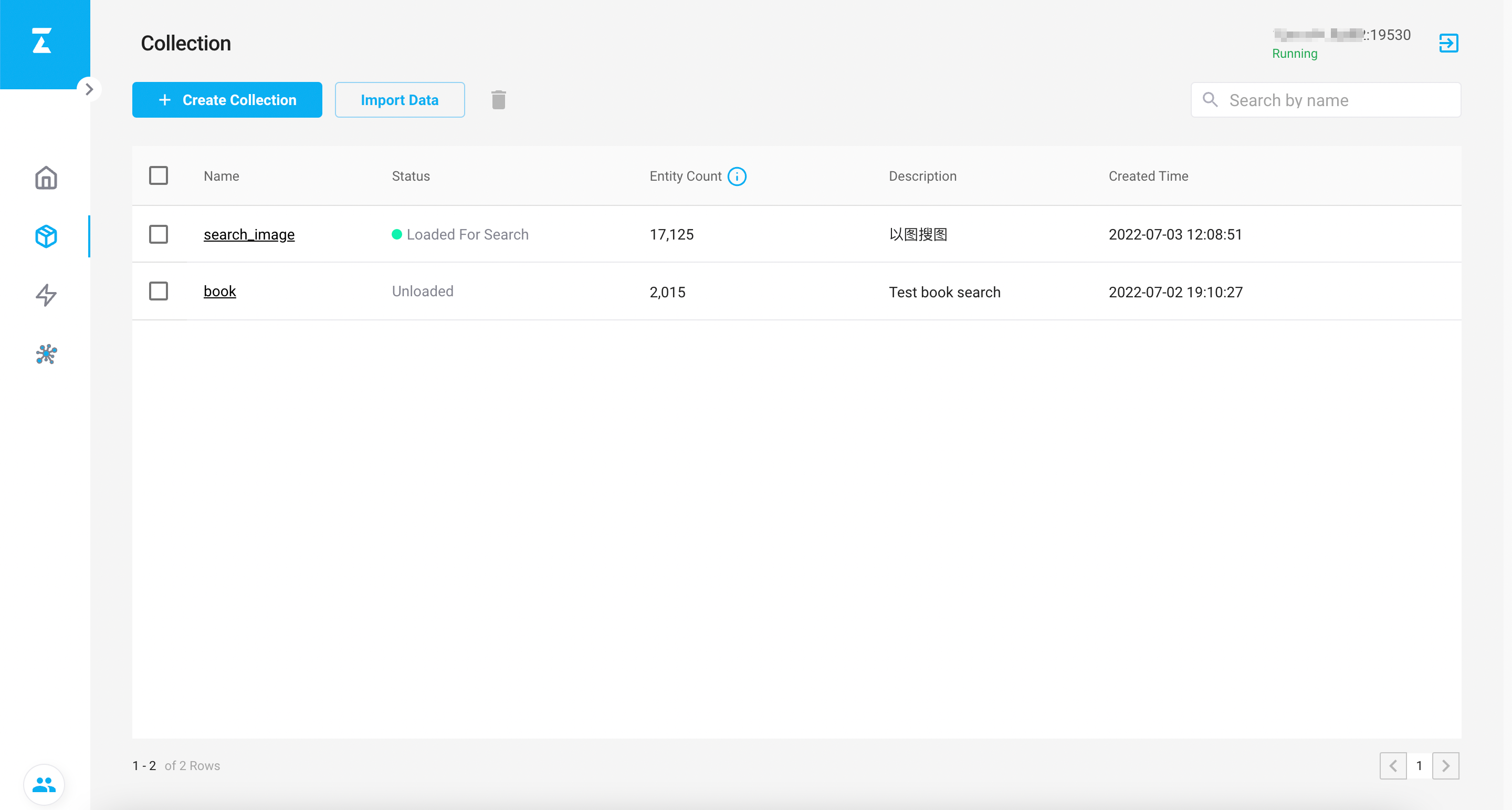
可以顺手点一下 load,将 collection 加载到内存中
客户端
客户端的逻辑只需要选择一张照片,将其 embedding 后构建 Milvus 查询,获取结果的 id,并基于 id 从 MySQL 中获取图片本地路径用 opencv 进行展示即可,因此客户端的代码就不做分解直接给出全部代码
from towhee import pipeline
from pymilvus import connections, Collection
import pymysql
import cv2
your_image = '/Users/wjun/Downloads/学习资料/JPEGImages/2007_000648.jpg'
pipline = pipeline('image-embedding')
vector = pipline(your_image)
# milvus 别名
alias = "default"
# milvus ip
host = "121.199.45.82"
# milvus port
port = "19530"
collection_name = 'search_image'
# 连接 milvus
connections.connect(host=host, port=port, alias=alias)
# 连接 mysql
host = '127.0.0.1'
port = 3306
user = 'root'
password = '980729'
connect = pymysql.connect(host=host, port=port, user=user, password=password)
collection = Collection(collection_name)
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
result = collection.search(data=[list(vector)], anns_field='image_vector', param=search_params, limit=5, consistency_level='Strong')
cursor = connect.cursor()
sql = ""
if len(result[0].ids) == 0:
print("没有匹配项")
exit(0)
elif len(result[0].ids) == 1:
sql = "select path from milvus_search.meta where id = %s" % str(result[0].ids[0])
else:
sql = "select path from milvus_search.meta where id in %s" % str(tuple(result[0].ids))
cursor.execute(sql)
imread = cv2.imread(your_image)
cv2.imshow('your image', imread)
image_id = 0
for img in cursor.fetchall():
imread = cv2.imread(img[0])
cv2.imshow(str(image_id), imread)
image_id += 1
cv2.waitKey(0)
cv2.destroyAllWindows()
最终执行结果

上述代码已上传 github
评论区