


数仓的最终输出产物就是回答“看什么数据,怎么看”,其中看什么就是指标,怎么看就是维度。指标在整个数仓建模过程中通常都是固定的,关乎口径的问题不轻易变动,但维度则是随时变化,不同业务、不同场景看同一个指标的维度都是不同的,这也就衍生出“即席查询”的一个应用场景。在离线场景一种比较流行的解决方案就是 kylin,通过预聚合+cube的方式。而 cube 则是本文的主题,

在 hive 的实现方式就是计算不同的分组情况并将所有的结果 union all 返回即可,从一个简单的例子开始。
一、数据准备&需求
小蒋是一家综合性公司的大数据分析工程师,王老板是这家公司的财务总管。这天王老板在大数据平台建了下面的表并填充了若干数据(场景强行合理)
create table dwd_employee_salary
(
department string comment '部门',
team string comment '团队',
post string comment '岗位',
name string comment '员工姓名',
salary bigint comment '薪水'
) comment '员工薪资明细表'
stored as parquet;
insert into dwd_employee_salary
values ('财务部', '运营组', '运营', '小蒋', 30000),
('研发部', '大数据组', '研发', '小王', 30000),
('研发部', '产品组', '产品经理', '张三', 15000),
('研发部', '视觉组', 'UI', '李四', 15000),
('研发部', '视觉组', 'UI', '王五', 10000),
('研发部', '后端组', '研发', '赵六', 25000),
('研发部', '后端组', '研发', '田七', 20000),
('财务部', '财务组', '运营', '孙八', 10000),
('财务部', '财务组', '财务', '钱九', 10000),
('财务部', '财务组', '财务', '周十', 10000);
王老板给小蒋提出了五点数据需求,如下:
- 不同岗位的平均薪资
- 不同团队的平均薪资
- 不同部门的平均薪资
- 不同部门不同岗位的平均薪资
- 整个公司的平均薪资
并且整理成一张表格给到我。
二、常规实现&聚合
小蒋拿到需求简单分析一下发现指标相同,只是五个维度不同罢了,对于 sql 的实现只是 group by 的列表不同,于是写下了如下 sql
select null as department, null as team, post, round(avg(salary)) as avg_salarg, '不同岗位的平均薪资' as type
from dwd_employee_salary
group by post
union all
select null as department, team, null as post, round(avg(salary)) as avg_salarg, '不同团队的平均薪资' as type
from dwd_employee_salary
group by team
union all
select department, null as team, null as post, round(avg(salary)) as avg_salarg, '不同部门的平均薪资' as type
from dwd_employee_salary
group by department
union all
select department, null as team, post, round(avg(salary)) as avg_salarg, '不同部门不同岗位的平均薪资' as type
from dwd_employee_salary
group by department, post
union all
select null as department, null as team, null as post, round(avg(salary)) as avg_salarg, '整个公司的平均薪资' as type
from dwd_employee_salary;
最终的执行结果如下,耗时 2m 4s:
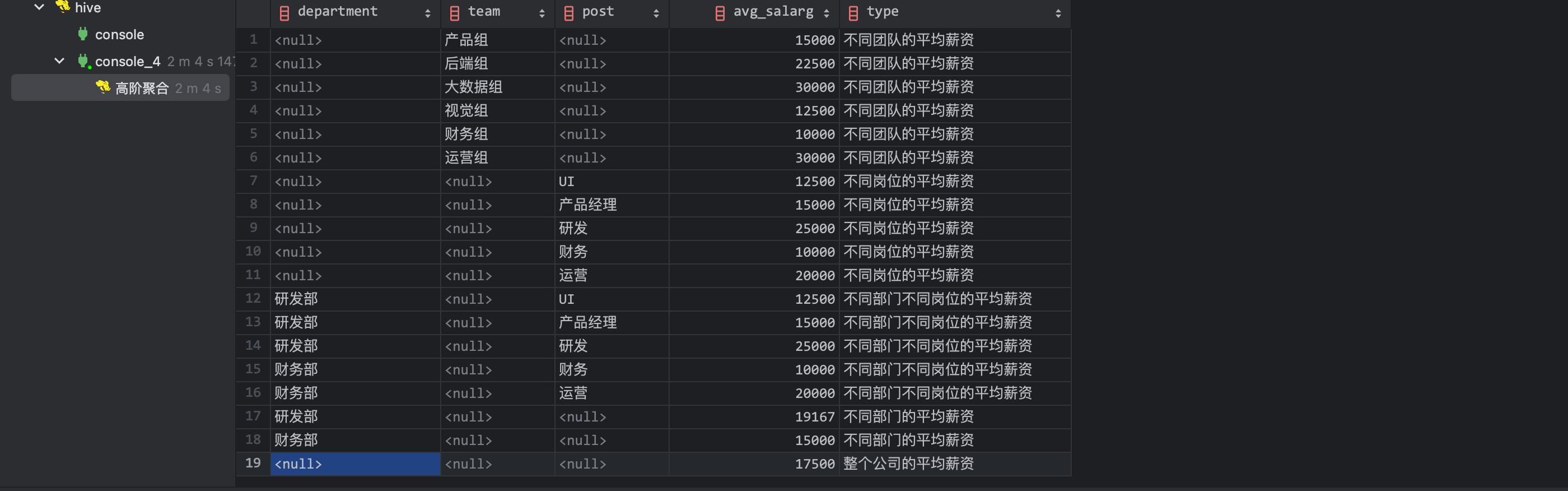
小蒋满心欢喜的把 sql 和结果拿给王老板。
三、高阶聚合&优化
王老板对结果没有异议但是对任务耗时和 sql 复杂度提出了质疑,希望小蒋可以让任务运行的更快且 sql 看起来尽可能简洁。小蒋回来后分析了任务日志发现居然启动了 7 个 job,最终确认时间主要都耗在任务的启动上,且重复多次读表、计算中间数据没有合理利用。正在小蒋一筹莫展时看到了 hive 官方文档的高阶聚合其主要的应用场景正是简化 union all,于是上面的 sql 就可以简化成下面这种形式
select department, team, post, round(avg(salary)) as avg_salarg
from dwd_employee_salary
group by department, team, post
grouping sets (
( post), -- 不同岗位的平均薪资
( team), -- 不同团队的平均薪资
( department), -- 不同部门的平均薪资
( department, post), -- 不同部门不同岗位的平均薪资
() -- 整个公司的平均薪资
);
这就是 hive 的高阶聚合,与普通聚合的区别是在 group by 后面追加 grouping sets,提供 group by 字段的若干排列组合,hive 会将不同组合计算出来后 union all 返回,从 sql 语义上看两者是等价的,但高阶聚合可以充分利用聚合中间值效率会更高且 sql 更加直观。
结果如下(耗时 18s)
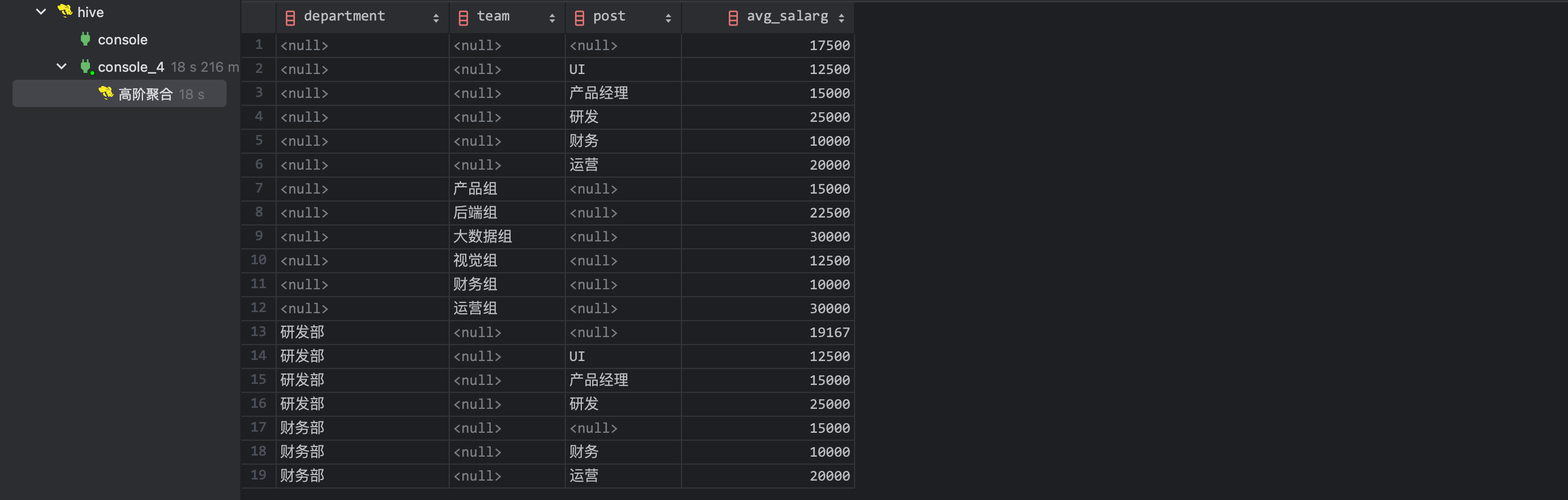
小蒋同步分析了日志和执行情况,上述任务只需要启动一个 job 只不过单个 job 会比原先 job 资源消耗略高一点。优化已经完成了 90%,小蒋此时需要考虑每行数据如何分配 type 类型。恰好 hive 提供了虚拟字段 grouping__id 来划分不同
select department, team, post, round(avg(salary)) as avg_salarg, grouping__id
from dwd_employee_salary
group by department, team, post
grouping sets (
( post), -- 不同岗位的平均薪资
( team), -- 不同团队的平均薪资
( department), -- 不同部门的平均薪资
( department, post), -- 不同部门不同岗位的平均薪资
() -- 整个公司的平均薪资
);
结果如下
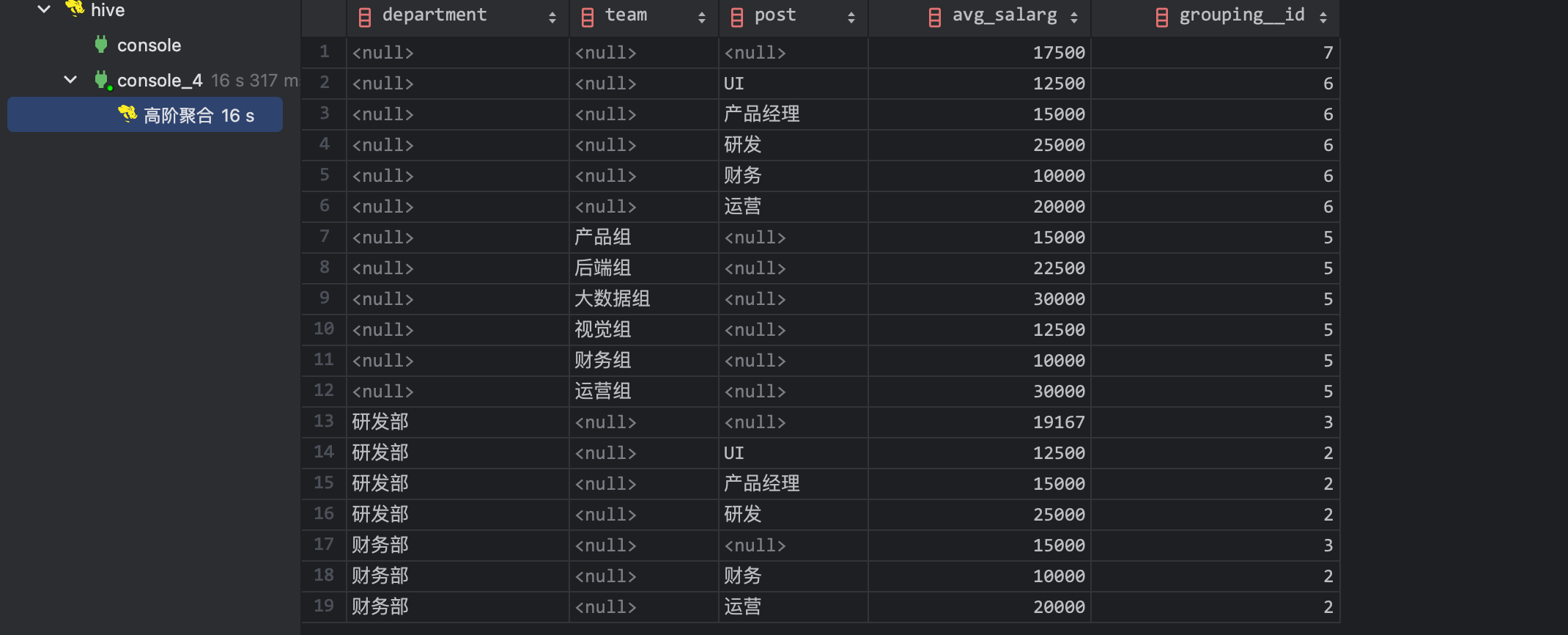
聪明的小蒋一眼就看出来 grouping__id 的算法。首先 grouping sets 中的组合一定是 group by 的子集,小蒋给出了下面的表格并规定
- 首行为 group by 按顺序排列的字段名
- 首列为 grouping sets 所有组合
- 单元格填充 0 或 1,若字段存在填 0 不存在填 1
- 得到的二进制后转为十进制
| department | team | post | 二进制 | 十进制 | |
|---|---|---|---|---|---|
| (post) | 1 | 0 | 110 | 6 | |
| (team) | 1 | 0 | 1 | ||
| (department) | 0 | 1 | 011 | 3 | |
| (department, post) | 0 | 1 | 0 | 010 | 2 |
| () | 1 | 1 | 111 | 7 |
那么就可以根据十进制的数字来判断本行是哪个 type 了,最终 sql 如下
select department,
team,
post,
round(avg(salary)) as avg_salarg,
case grouping__id
when 6 then '不同岗位的平均薪资'
when 5 then '不同团队的平均薪资'
when 3 then '不同部门的平均薪资'
when 2 then '不同部门不同岗位的平均薪资'
when 7 then '整个公司的平均薪资' end type
from dwd_employee_salary
group by department, team, post
grouping sets (
( post), -- 不同岗位的平均薪资
( team), -- 不同团队的平均薪资
( department), -- 不同部门的平均薪资
( department, post), -- 不同部门不同岗位的平均薪资
() -- 整个公司的平均薪资
);
王老板看到后表示非常满意!!!并希望在所有的 hive 版本都可以兼容,小蒋随后部署一套 hive 2.1.1 的版本测试发现 grouping__id 居然不一样,原来 hive 在 2.3.0 修改了 grouping__id 的逻辑,聪明的小蒋很快就总结出了 2.3.0 之前的算法
- 首行为 group by 按顺序排列的字段名
- 首列为 grouping sets 所有组合
- 单元格填充 0 或 1,若字段存在填 1 不存在填 0
- 得到的二进制进行反转后转为十进制
上面的表格就变成了
| department | team | post | 二进制 | 反转 | 十进制 | |
|---|---|---|---|---|---|---|
| (post) | 0 | 0 | 1 | 100 | ||
| (team) | 0 | 1 | 0 | 010 | 2 | |
| (department) | 0 | 0 | 100 | 001 | 1 | |
| (department, post) | 1 | 0 | 1 | 101 | 101 | 5 |
| () | 0 | 0 | 000 | 000 | 0 |
四、拓展&总结
在随后的 sql review 中小蒋发现一个特殊的 grouping sets 集合在业务上有特殊的含义,例如对于一个 group by a, b, c 三个的聚合
第一种情况是所有维度的排列组合,业务上称为 cube 立方体的概念,这样的立方体可以在指定维度下能够满足所有情况的数据角度,而 kylin 的实现就是这样;第二种情况则是维度递减或递增,一步一步的抽出多余的维度从而看到每个层级的数据,业务上成为 rollup 上卷或下钻。
对于这两类特殊情况 hive 进一步简化 sql,不需要手动指定 grouping sets 了,只需要在 group by 后面追加 with cube 或 with rollup 即可,同时虚拟字段 grouping__id 依然使用,因此可以理解为 with cube/rollup 是对 grouping sets 的简写。
select a, b, c, count(1)
from xxx
group by a, b, c
with cube;
---- 等价 ----
select a, b, c, count(1)
from xxx
group by a, b, c
grouping sets (
(), (a), (b), (c), (a, b), (a, c), (b, c), (a, b, c)
);
--------------------------------------------------------------------
select a, b, c, count(1)
from xxx
group by a, b, c
with rollup;
---- 等价 ----
select a, b, c, count(1)
from xxx
group by a, b, c
grouping sets (
( a, b, c), ( a, b), ( a), ()
);
评论区