


上一篇:Hive源码系列二分析 Hive 如何将一个 SQL 转换成 AST;本节将基于上节的 AST 做进一步操作直到提交任务为止
本节从 Driver 类的sem.analyze(tree, ctx);开始,快速进入核心代码
public void analyze(ASTNode ast, Context ctx) throws SemanticException {
//空方法,什么都没干
initCtx(ctx);
init(true);
//核心代码,是一个抽象方法
analyzeInternal(ast);
}
找到具体的实现

这里将进行 Hive 的词法语法解析、优化是最核心的部分,一共 11 步,但核心归纳起来的大致流程为:Parser -> Semantic Analyzer -> Logical Plan Gen. -> Logical Optimizer -> Physical Plan Gen. -> Physical Optimizer,从中 SQL 的变化为:SQL -> AST -> QueryBlock -> Operator Tree -> Task Tree。其中 Parser 为上一节的内容,本节直接从 Semantic Analyzer 开始,随着下面这一串代码我们正式开始
LOG.info("Starting Semantic Analysis");
Semantic Analyzer(QB)
// 1. Generate Resolved Parse tree from syntax tree
// todo AST -> QB 把一个个 tok_tabname 转换成 QB,同时读取元数据进行替换
if (!genResolvedParseTree(ast, plannerCtx)) {
return;
}
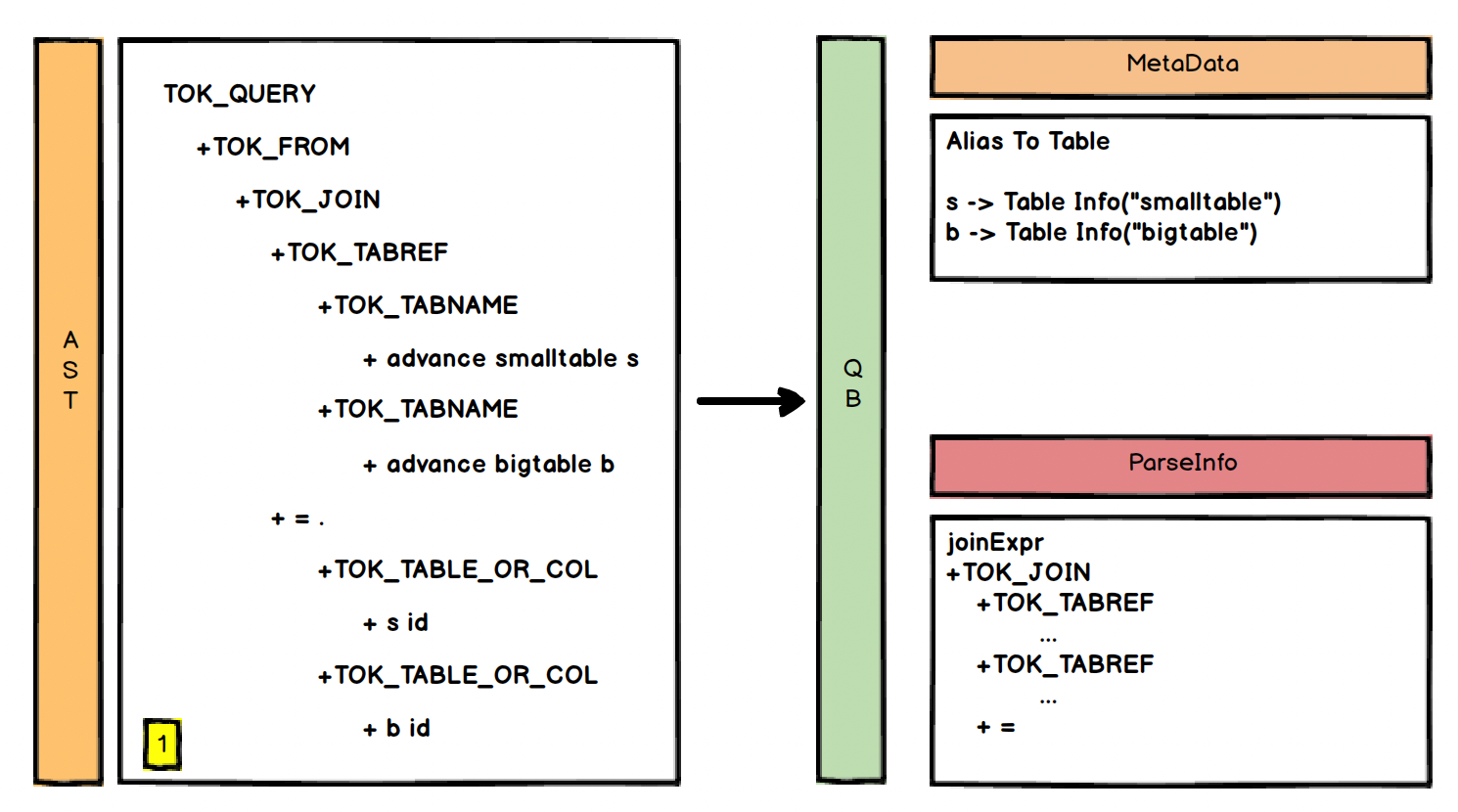
从抽象语法树中获取解析树,即 AST -> QB,这里主要是将 AST 替换成 QueryBlock(QB),QB 可以理解为最小的语法单元,将 AST 每一个节点单独取出来并封装成一个个 QB,同时在这里替换元数据里的信息,看源码几个关键步骤的注释
// 1. analyze and process the position alias
// 2. analyze create table command
// 3. analyze create view command
// 4. continue analyzing from the child ASTNode.
// todo 生成 QB
if (!doPhase1(child, qb, ctx_1, plannerCtx)) {
// if phase1Result false return
return false;
}
生成 QB 的关键方法
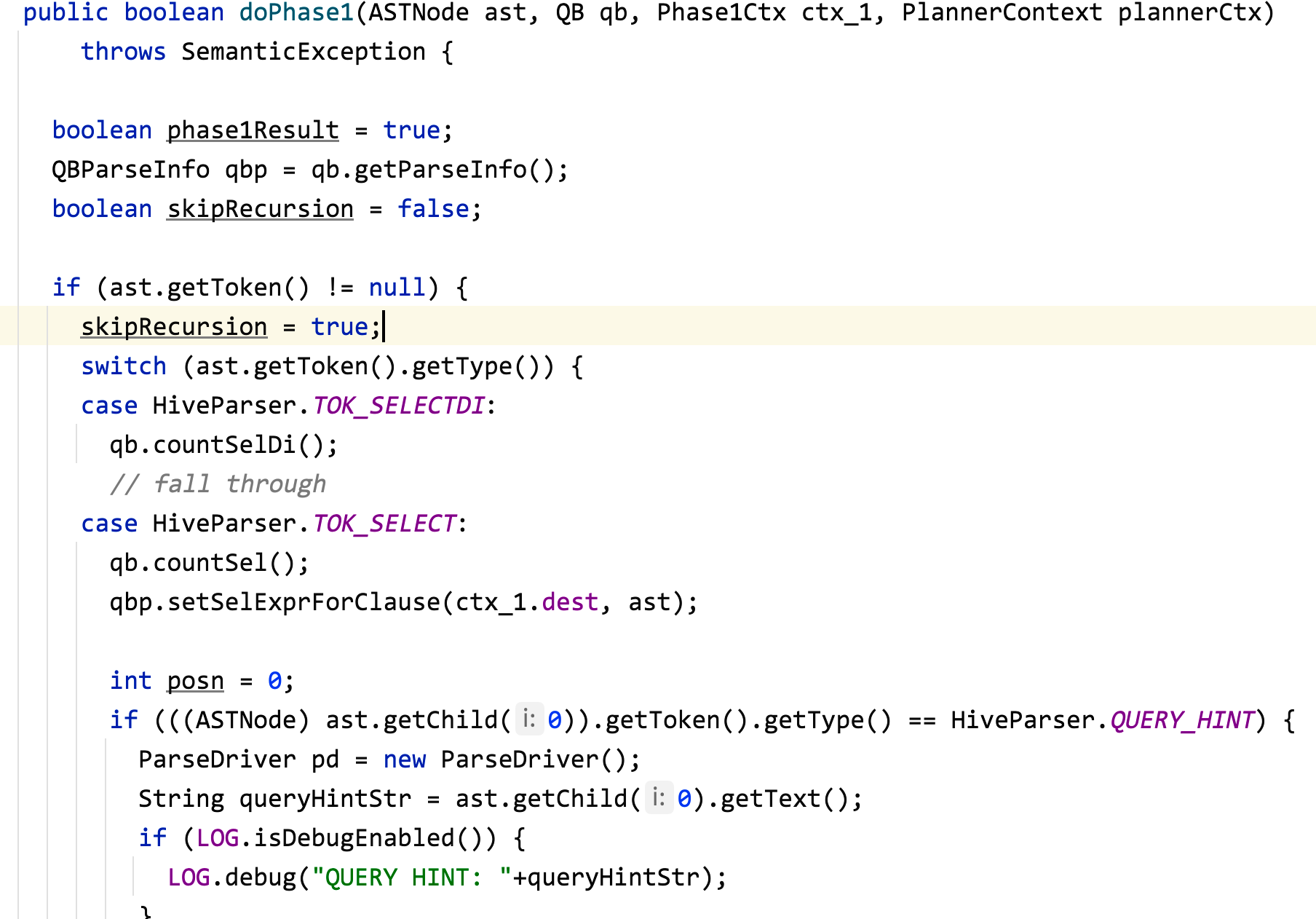
可以看出就是一个超大的 switch case 方法,去匹配 AST 里面的一个个节点做对应的 QB 操作
// 5. Resolve Parse Tree
// Materialization is allowed if it is not a view definition
// todo 获取元数据
getMetaData(qb, createVwDesc == null);
LOG.info("Completed getting MetaData in Semantic Analysis");
plannerCtx.setParseTreeAttr(child, ctx_1);
这里与元数据进行交互,并获取如:表数据在 HDFS 的路径最终封装到 QB 中
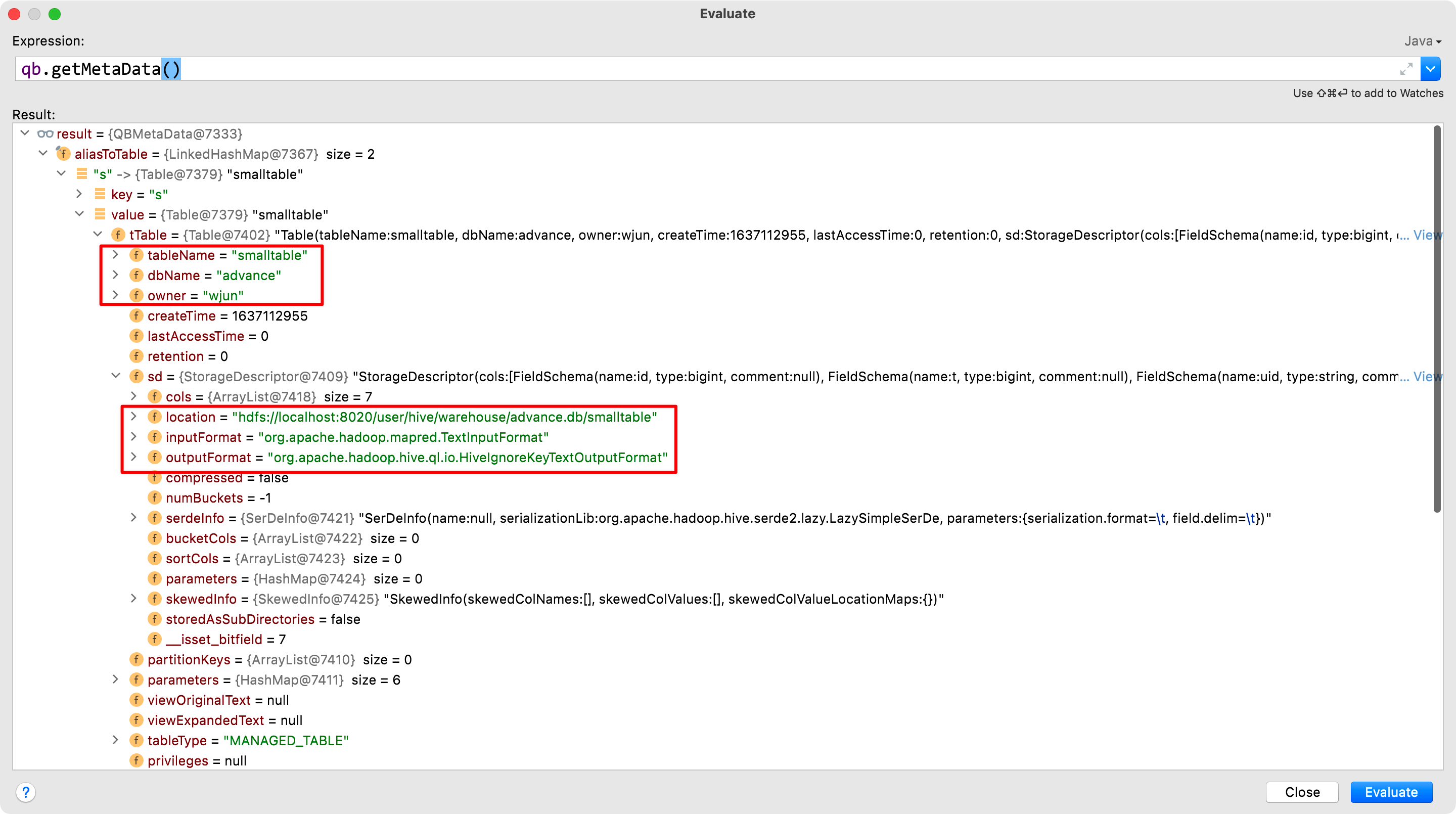
来一个真实的 SQL
insert overwrite table advance.jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from advance.smalltable s
join advance.bigtable b
on s.id = b.id;
从上一节我们知道这个 SQL 被解析成 AST 可以分为三块
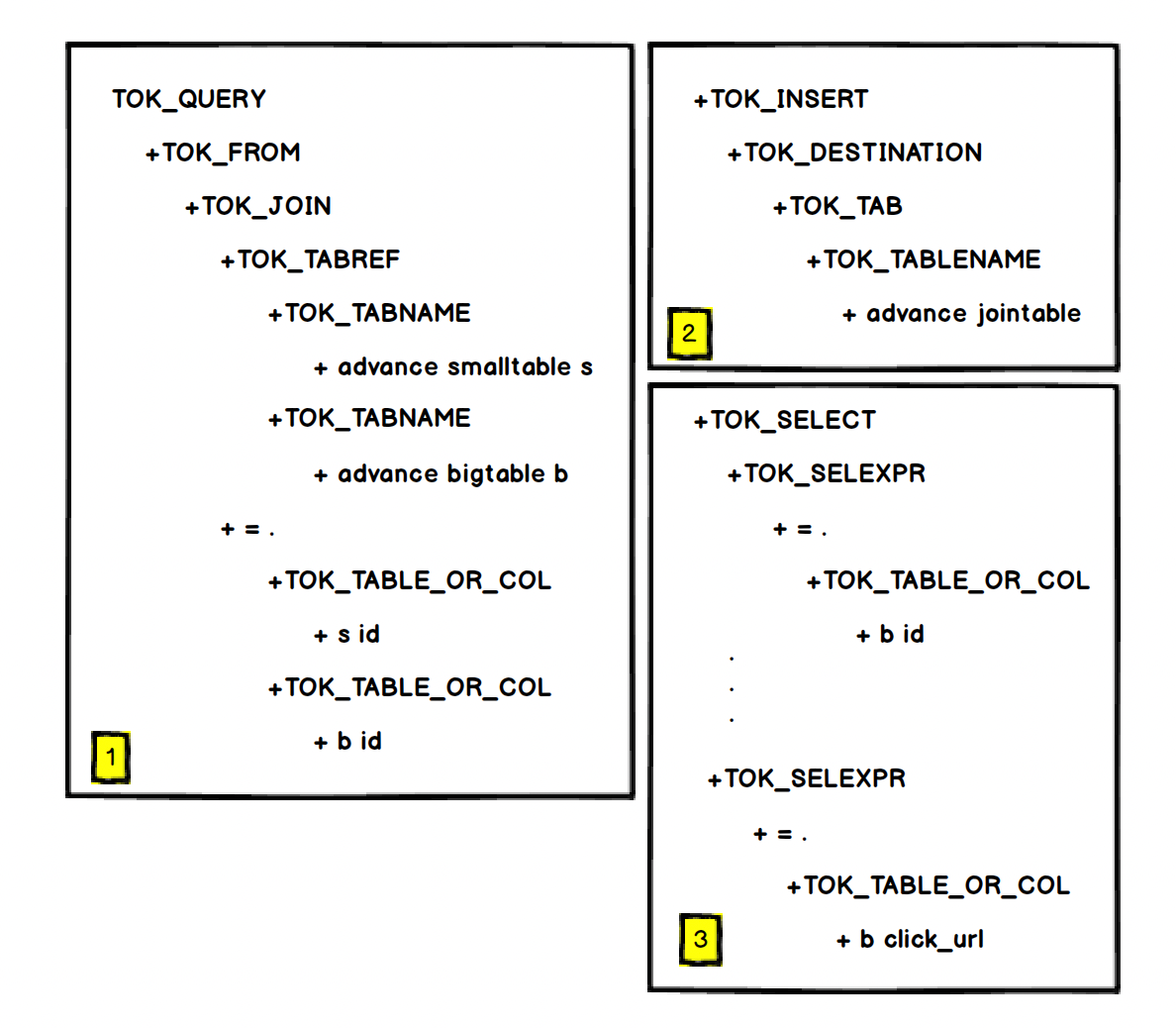
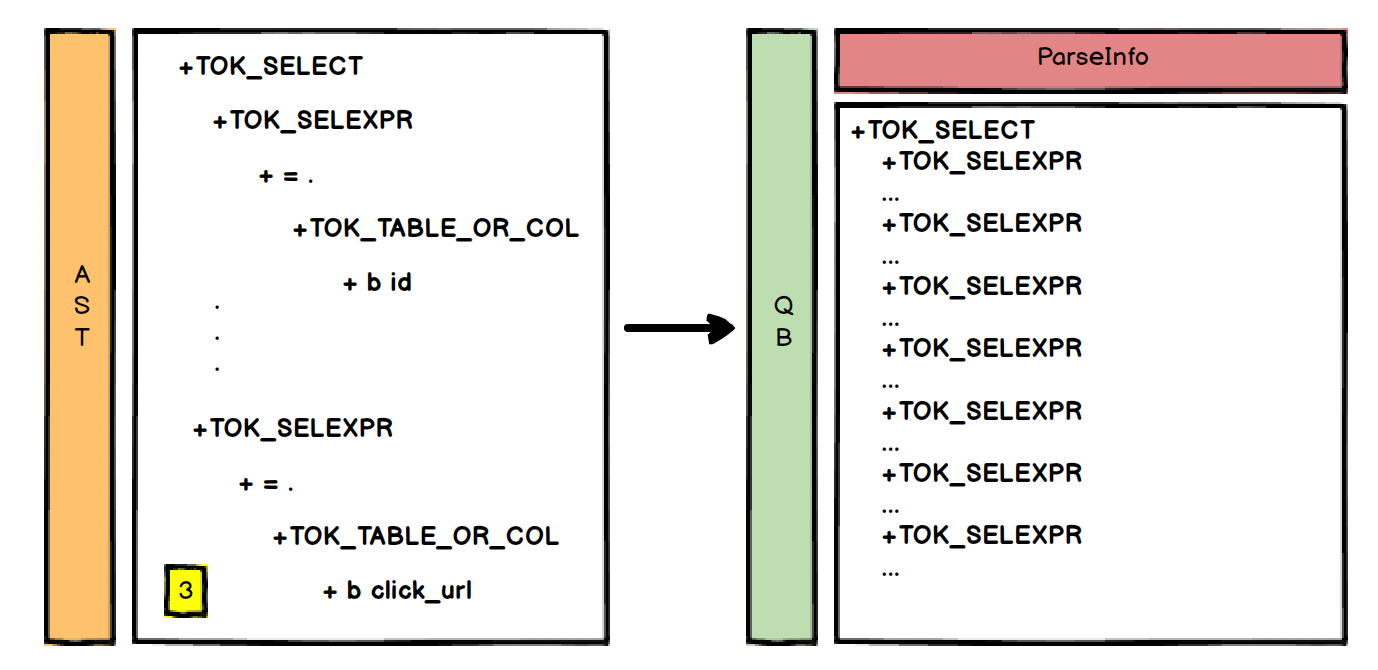
对于 AST 来说上面这个图其实是一个整体,但对于 QB 来说他们是分开的,可以看一下 QB 对象的属性结构
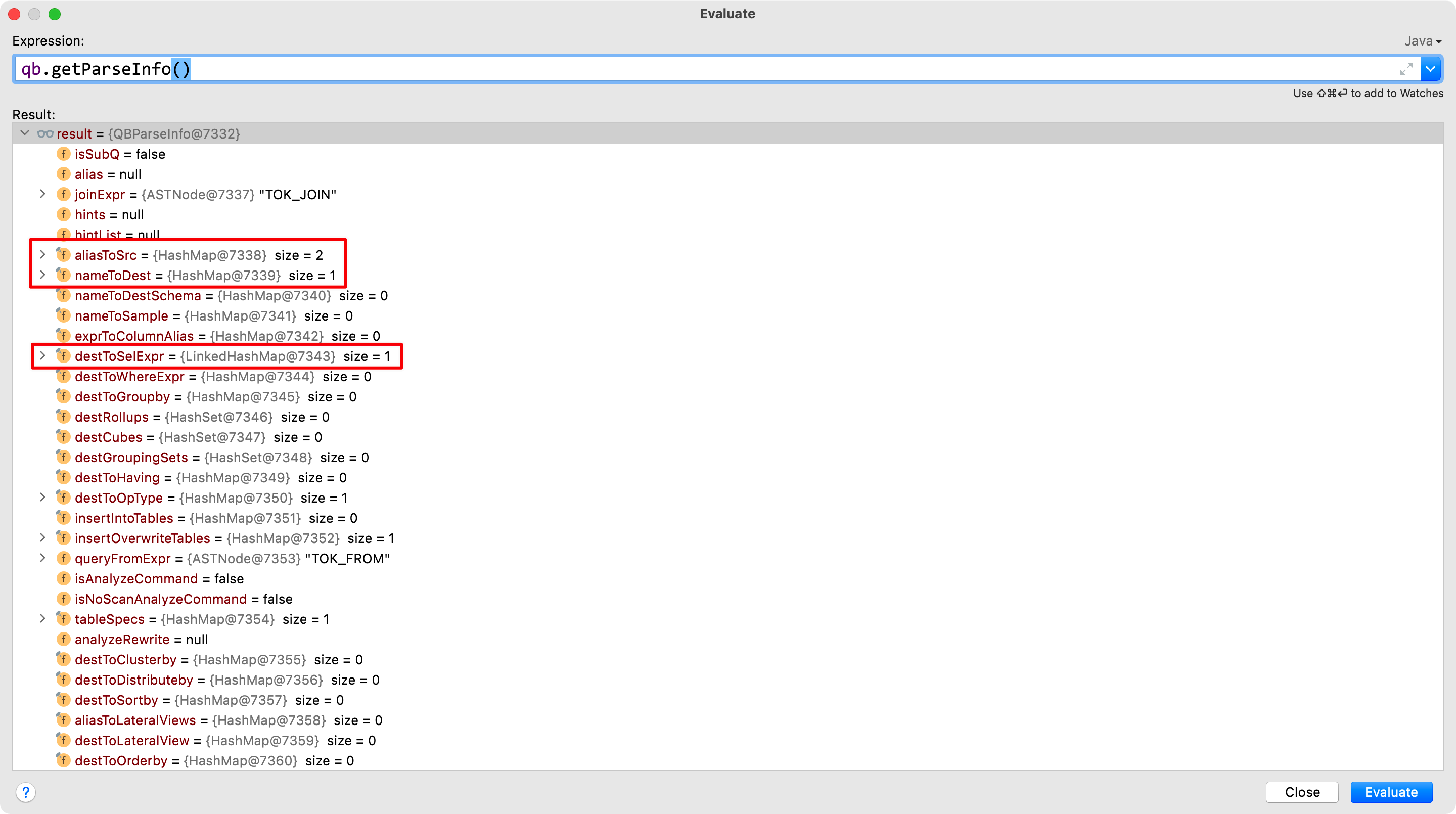
实际上图的1 2 3 块分别对应 QB 的一些属性如 joinExpr、nameToDest、destToSelExpr,因此对应的 QB 是这样的
Semantic Analyzer (1/3)
Semantic Analyzer (2/3)

Semantic Analyzer (3/3)
Logical Plan Gen.(OP)
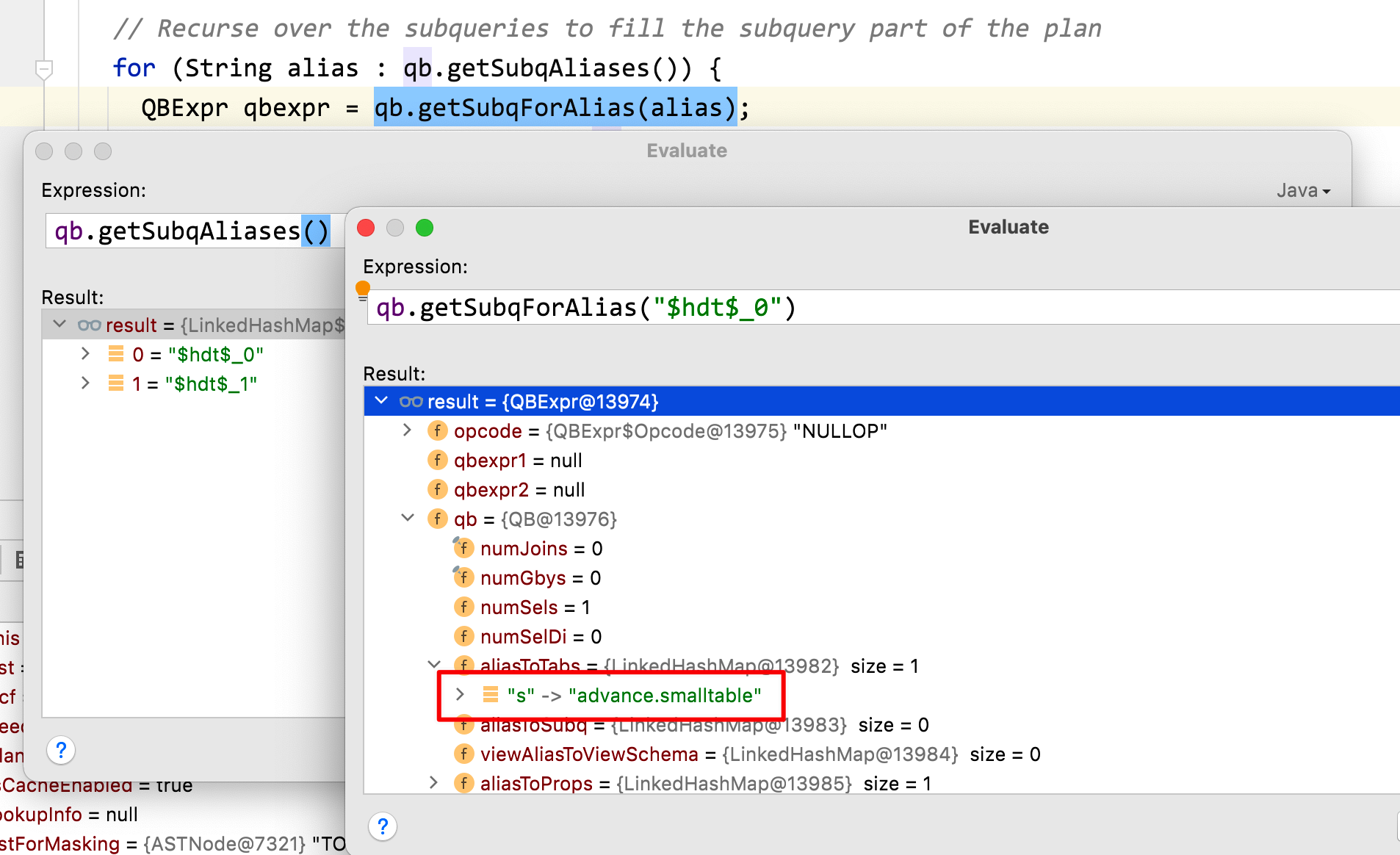
从解析树生成操作树,即:QB -> OP
// 2. Gen OP Tree from resolved Parse Tree
// todo OP Tree 就是执行计划里面的 xxxOperator
Operator sinkOp = genOPTree(ast, plannerCtx);
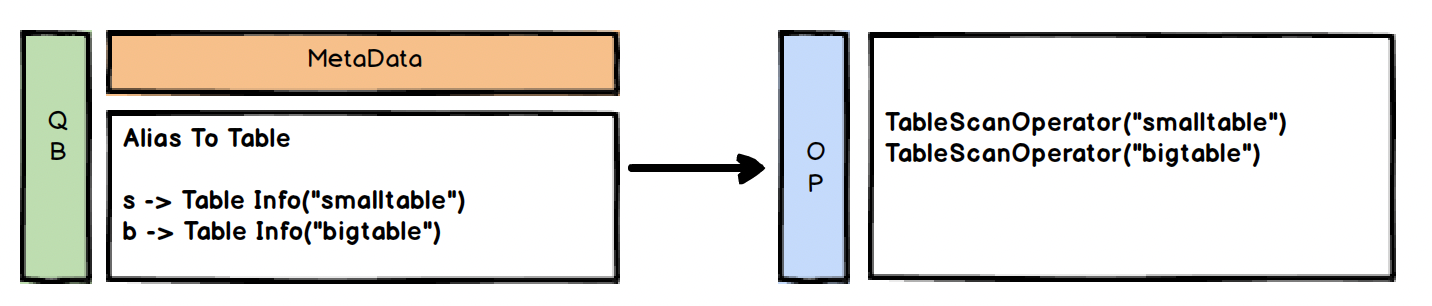
这里将生成操作树,也就是我们通过 explain 打印出来的信息,也就是所谓的逻辑执行计划。这部分的操作主要逻辑就是根据 QB 的一些标记来匹配对应的 Operator 对象
每块的 QB 会找到对应的 Operator 对象如
Logical Plan Generator (1/4)
Logical Plan Generator (2/4)
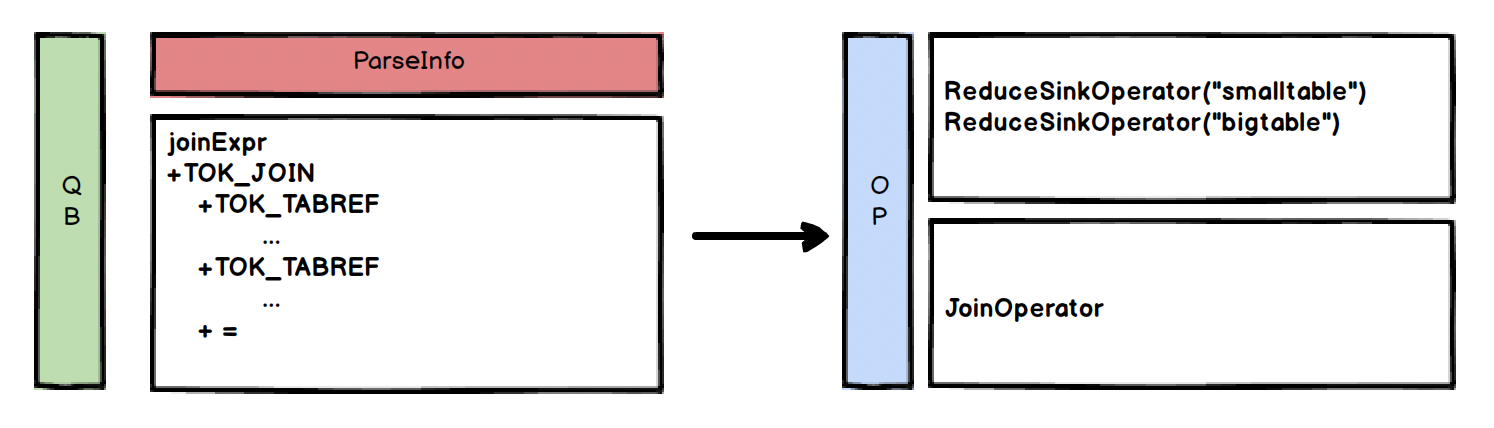
Logical Plan Generator (3/4)
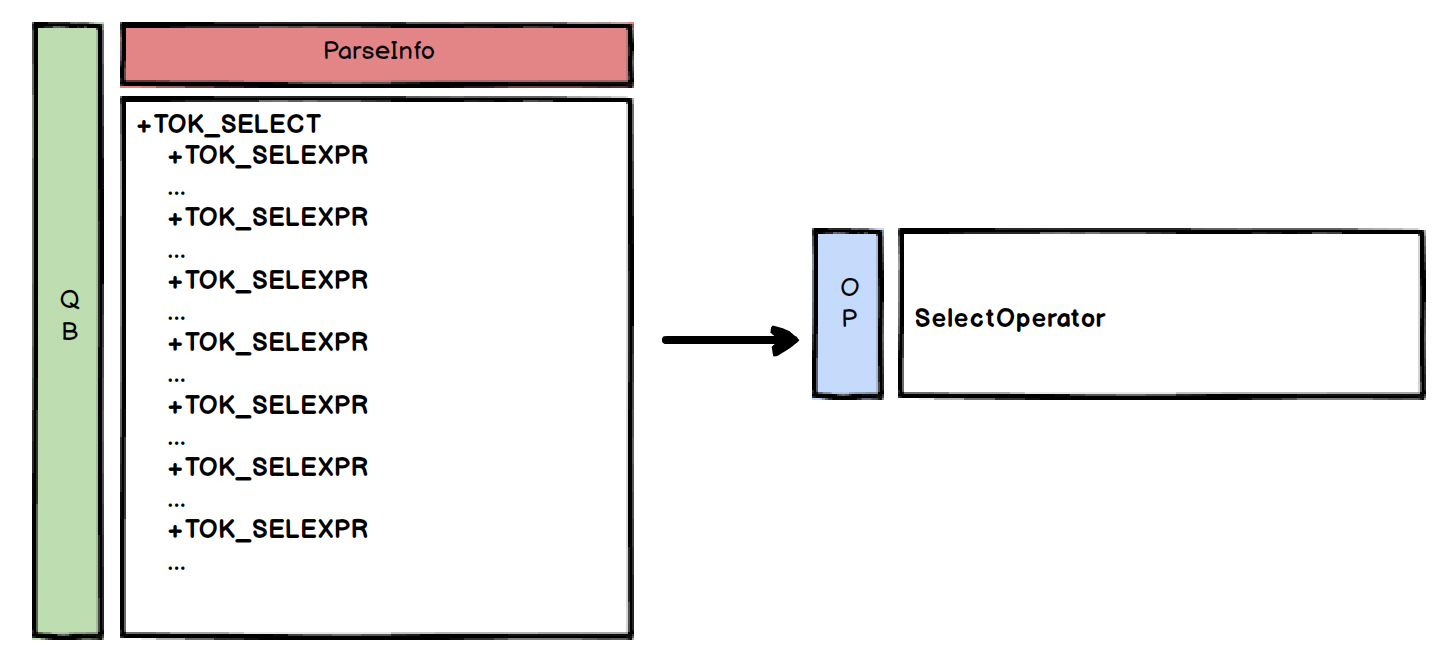
Logical Plan Generator (4/4)
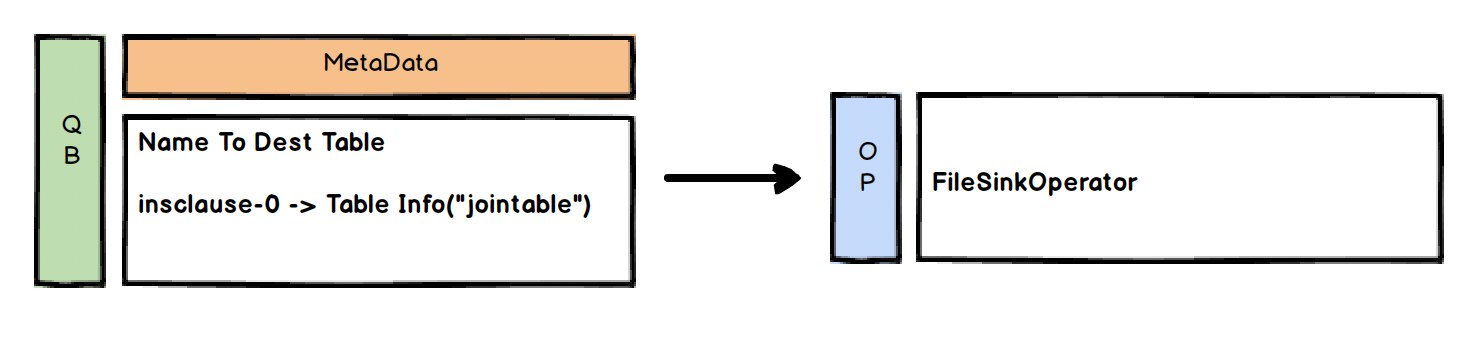
因此最终的逻辑计划为:
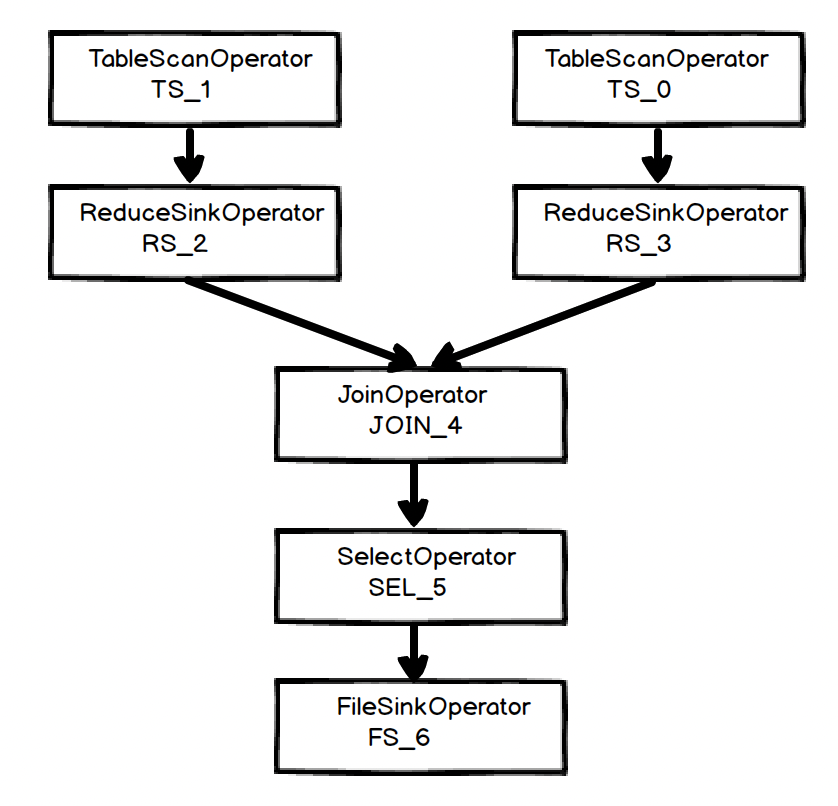
实际上此时的逻辑执行计划是不止上面这些,具体可以通过如下方式来整理真正的逻辑执行计划

通过 sinkOp.getParentOperators()一步步找当前 OP 的父 OP(parentOperators)或子 OP(childOperator)来构建全部的逻辑执行计划
Logical Optimizer(OP)
// 3. Deduce Resultset Schema
if (createVwDesc != null && !this.ctx.isCboSucceeded()) {
resultSchema = convertRowSchemaToViewSchema(opParseCtx.get(sinkOp).getRowResolver());
} else {
// resultSchema will be null if
// (1) cbo is disabled;
// (2) or cbo is enabled with AST return path (whether succeeded or not,
// resultSchema will be re-initialized)
// It will only be not null if cbo is enabled with new return path and it
// succeeds.
if (resultSchema == null) {
resultSchema = convertRowSchemaToResultSetSchema(opParseCtx.get(sinkOp).getRowResolver(),
HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_RESULTSET_USE_UNIQUE_COLUMN_NAMES));
}
}
第三步将查询字段封装为一个个 FieldSchema (值+类型),最终放到 ReadEntries 中,不是关键步骤
// 4. Generate Parse Context for Optimizer & Physical compiler
// todo 创建 逻辑优化器和物理执行计划生成器 上下文对象
// 5. Take care of view creation
// todo 处理视图相关操作
// 6. Generate table access stats if required
// todo 表的统计信息生成
第四步创建逻辑执行计划优化器和物理执行计划优化器、处理视图、生成表的统计信息
// 7. Perform Logical optimization
// todo 优化逻辑执行计划
if (LOG.isDebugEnabled()) {
LOG.debug("Before logical optimization\n" + Operator.toString(pCtx.getTopOps().values()));
}
// todo 优化器
Optimizer optm = new Optimizer();
optm.setPctx(pCtx);
// todo 构造 transformations
optm.initialize(conf);
// todo 遍历所有的优化器执行优化
pCtx = optm.optimize();
这里开始对逻辑执行计划进行优化,我们熟知的列裁剪、分区裁剪、MapJoin等操作都是在这里完成的,所有的优化操作都对应一个 Transform 对象,并被放置在 Optimizer 的一个 List 中
transformations = new ArrayList<Transform>();
// Add the additional postprocessing transformations needed if
// we are translating Calcite operators into Hive operators.
transformations.add(new HiveOpConverterPostProc());
当获取到全部的优化手段后,在 optm.optimize() 中开始遍历 Transform 来执行优化,其本质就是修改 Operator 对象将 Operator 子类 A,修改为子类 B。
public ParseContext optimize() throws SemanticException {
// 遍历优化手段
for (Transform t : transformations) {
t.beginPerfLogging();
pctx = t.transform(pctx);
t.endPerfLogging(t.toString());
}
return pctx;
}
常用的 Logical Optimizer 有
| Logical Optimizer | Description |
|---|---|
| LineageGenerator | 表与表的血缘关系生成器 |
| ColumnPruner | 列裁剪 |
| PredicatePushDown | 谓词下推 |
| PartitionPruner | 分区裁剪 |
| PartitionConditionRemover | 在分区裁剪前, 将一些无关的条件谓词去除 |
| GroupByOptimizer | Group By优化 |
| SamplePruner | 采样裁剪 |
| MapJoinProcessor | MapJoin优化,将ReduceSinkOperator转换成MapSinkOperator |
| BucketMapJoinOptimizer | 分桶MapJoin优化 |
| SortedMergeBucketMapJoinOptimizer | Sort Merge Join |
| UnionProcessor | 目前只在两个子查询都是map-only Task时作个标记 |
| JoinReorder | /*+ STREAMTABLE(A) */ |
| ReduceSinkDeDuplication | 如果两个reduce sink operator共享同一个分区/排序列, 则需要对它们进行合并 |
评论区