


一、概述
1.1 需求分析
Spark Streaming实现两个流的join操作,如:一个流是订单数据,另一个流是订单详情数据,现需要将两个流按照某个公共字段连接进行join操作,同时订单数据和订单详情数据理论上是同时产生的,但考虑到实际情况即:延迟,结合Spark Streaming的批次处理实时数据的理念,这两个流的数据不一定是同时到达的,意思就是订单一的数据已经过来了,可能订单详情一的一系列数据早到或者迟到,这就导致直接做join时会join不上,且数据会丢失。
1.2 需求实现
为了保证早到的数据或者迟到的数据在某个时间点能够被join上,因此需要对数据做缓存处理。前提是两个流的批次大小必须一样。首先需要明白订单数据和订单详情数据是一对多的关系,即一个订单数据可能对应多个订单详情数据(一个订单买了很多商品)。
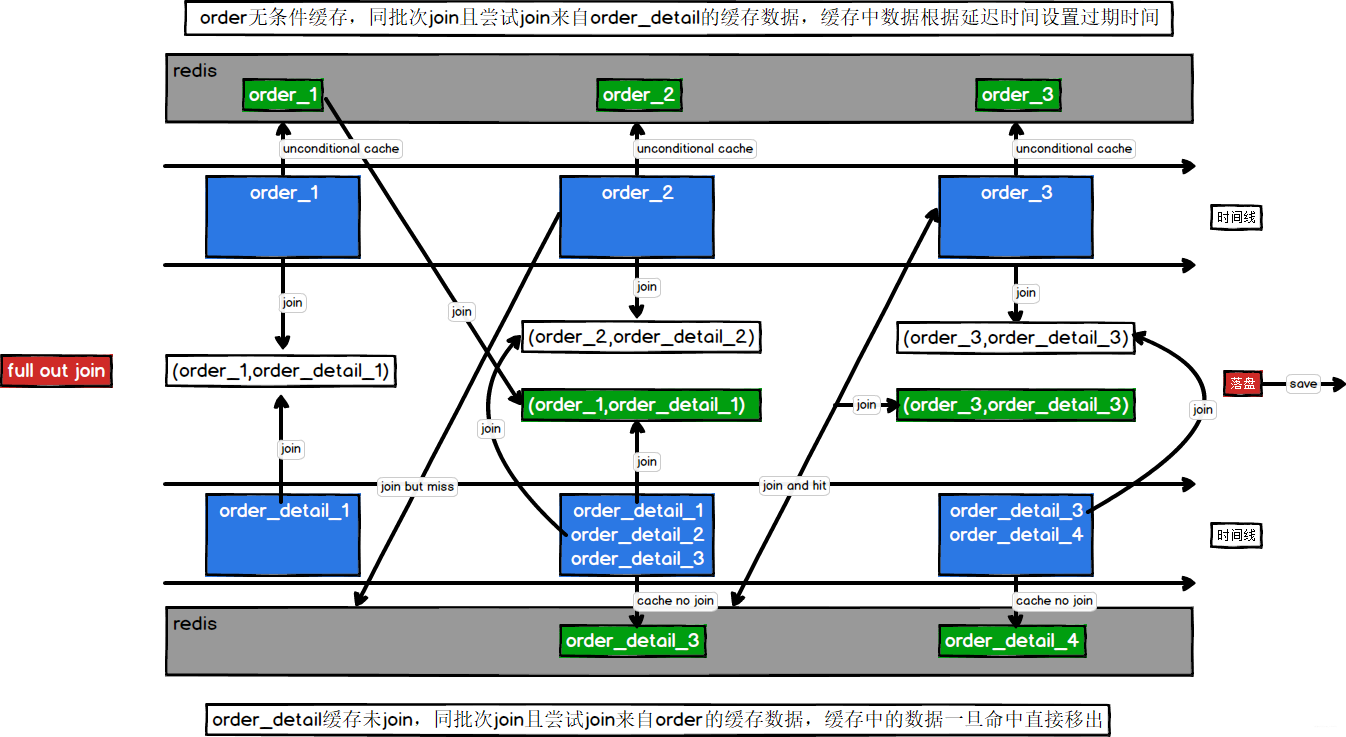
考虑订单数据,不管订单数据来早还是来晚都需要做缓存,站在订单数据的角度上,即使同批次join上了也不能确定还有没有对应的其他订单详情数据有没有来,是来过了还是没有来,因此订单数据需要先和同批次进行join,然后无条件缓存自身同时还需要查询订单详情的缓存,缓存自身为了等待来晚的订单详情数据,查询订单详情缓存为了寻找来早的订单详情数据。
考虑订单详情数据,若同批次join上,那就结束了(该数据的生命周期结束),若同批次没有join上需要查询订单数据缓存尝试join为了确保订单数据有没有先到,若还是没有join上那就以为了这条数据来早了,因此就缓存自身等待订单数据,也就是说同批次join上意味着没有没有延迟;查找订单缓存join上意味着自己来晚了,没有join上缓存自身意味着自己来早了
二、实现
2.1 几个问题
2.1.1 采用什么样的 join
Spark Streaming中有四个join分别是join、leftOuterJoin、rightOuterJoin、fullOuterJoin
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("join").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List((1, "a"), (2, "b"), (3, "c")))
val rdd2 = sc.makeRDD(List((1, "a1"), (1, "a2"), (4, "d1")))
println("join: " + rdd1.join(rdd2).collect().toList)
println("leftOuterJoin: " + rdd1.leftOuterJoin(rdd2).collect().toList)
println("rightOuterJoin: " + rdd1.rightOuterJoin(rdd2).collect().toList)
println("fullOuterJoin: " + rdd1.fullOuterJoin(rdd2).collect().toList)
}
}
最终结果
join: List((1,(a,a1)), (1,(a,a2)))
leftOuterJoin: List((1,(a,Some(a1))), (1,(a,Some(a2))), (2,(b,None)), (3,(c,None)))
rightOuterJoin: List((4,(None,d1)), (1,(Some(a),a1)), (1,(Some(a),a2)))
fullOuterJoin: List((4,(None,Some(d1))), (1,(Some(a),Some(a1))), (1,(Some(a),Some(a2))), (2,(Some(b),None)), (3,(Some(c),None)))
| join类型 | 是否丢数据 |
|---|---|
| join | 只保留两个集合公有的key,其他全部丢弃 |
| leftOuterJoin | 只保留左边集合的所有key |
| rightOuterJoin | 只保留右边集合的所有key |
| fullOuterJoin | 保留全部数据 |
因此双流join必须选择fullOuterJoin
2.1.2 缓存数据问题
首先任何支持存储的组件都能实现,但需要考虑到实时性以及数据量的问题,因此可以使用redis或者Hbase,本文选择redis作为缓存,基于如下考虑:
- 订单数据无条件缓存,那么是否无条件缓存下去?
- 订单详情数据缓存后,是否无条件缓存下去?
答案都是不会,首选订单详情数据的数据量往往是很大的,因此缓存中的数据一旦被join命中立刻删除,此时这条数据已经没有用了(不删也不会有影响,考虑一下?不删会不会造成数据重复,即会不会再次被命中),对于订单数据也无需要无限缓存下去,只要等待一段时间(大于实际的延迟时间即可)就可以删除,即使极端情况下有某条订单详情数据过来了,那也没有join的必要,已经过了实时计算的范畴了。因此使用redis来管理这些数据的生命周期(设置key的过期时间)
2.2 图示
2.3 代码实现
2.3.1 样例类
知道有这些类即可,具体字段不需要知道
订单样例类
case class OrderInfo(id: String,
province_id: String,
consignee: String,
order_comment: String,
var consignee_tel: String,
order_status: String,
payment_way: String,
user_id: String,
img_url: String,
total_amount: Double,
expire_time: String,
delivery_address: String,
create_time: String,
operate_time: String,
tracking_no: String,
parent_order_id: String,
out_trade_no: String,
trade_body: String,
var create_date: String,
var create_hour: String)
订单详情样例类
case class OrderDetail(id: String,
order_id: String,
sku_name: String,
sku_id: String,
order_price: String,
img_url: String,
sku_num: String)
保存join结果的样例类
case class SaleDetail(var order_detail_id: String = null,
var order_id: String = null,
var order_status: String = null,
var create_time: String = null,
var user_id: String = null,
var sku_id: String = null,
var user_gender: String = null,
var user_age: Int = 0,
var user_level: String = null,
var sku_price: Double = 0D,
var sku_name: String = null,
var dt: String = null) {
def this(orderInfo: OrderInfo, orderDetail: OrderDetail) {
this
mergeOrderInfo(orderInfo)
mergeOrderDetail(orderDetail)
}
def mergeOrderInfo(orderInfo: OrderInfo): Unit = {
if (orderInfo != null) {
this.order_id = orderInfo.id
this.order_status = orderInfo.order_status
this.create_time = orderInfo.create_time
this.dt = orderInfo.create_date
this.user_id = orderInfo.user_id
}
}
def mergeOrderDetail(orderDetail: OrderDetail): Unit = {
if (orderDetail != null) {
this.order_detail_id = orderDetail.id
this.sku_id = orderDetail.sku_id
this.sku_name = orderDetail.sku_name
this.sku_price = orderDetail.order_price.toDouble
}
}
def mergeUserInfo(userInfo: UserInfo): Unit = {
if (userInfo != null) {
this.user_id = userInfo.id
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val date = sdf.parse(userInfo.birthday)
val curTs: Long = System.currentTimeMillis()
val betweenMs = curTs - date.getTime
val age = betweenMs / 1000L / 60L / 60L / 24L / 365L
this.user_age = age.toInt
this.user_gender = userInfo.gender
this.user_level = userInfo.user_level
}
}
}
2.3.2 前期准备(不重要)
对数据进行处理,转换样例类、脱敏等
//1.创建SparkConf
val sparkConf = new SparkConf().setAppName("SaleApp").setMaster("local[*]")
//2.创建streamingContext
val ssc: StreamingContext = new StreamingContext(sparkConf, Seconds(3))
//3.消费三个主题的数据
val orderInfoKafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(ssc, Set(GmallConstant.GMALL_EVENT))
val orderDetailInfoKafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(ssc, Set(GmallConstant.GMALL_EVENT))
val userInfoKafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(ssc, Set(GmallConstant.GMALL_EVENT))
//4.将数据转换成样例类,同时转换结构
val orderInfoDStream: DStream[(String, OrderInfo)] = orderInfoKafkaDStream.map(record => {
val jsonString: String = record.value()
// 1 转换成 case class
val orderInfo: OrderInfo = JSON.parseObject(jsonString, classOf[OrderInfo])
// 2 脱敏 电话号码 1381*******
val telTuple: (String, String) = orderInfo.consignee_tel.splitAt(4)
orderInfo.consignee_tel = telTuple._1 + "*******"
// 3 补充日期字段
val datetimeArr: Array[String] = orderInfo.create_time.split(" ")
orderInfo.create_date = datetimeArr(0) //日期
val timeArr: Array[String] = datetimeArr(1).split(":")
orderInfo.create_hour = timeArr(0) //小时
(orderInfo.id, orderInfo)
})
val orderDetailDStream: DStream[(String, OrderDetail)] =
orderDetailInfoKafkaDStream.map(record => {
val orderDetail = JSON.parseObject(record.value(), classOf[OrderDetail])
(orderDetail.order_id, orderDetail)
})
//5.order和order_detail做join
val joinDStream: DStream[(String, (Option[OrderInfo], Option[OrderDetail]))] =
orderInfoDStream.fullOuterJoin(orderDetailDStream)
2.3.3 逻辑实现
//6.处理joinDStream业务逻辑
val noUserInfoDStream = joinDStream.mapPartitions(iter => {
//清空保存数据的集合
noUserSaleDetails.clear()
//获取 redis 连接,自己封装的工具类
val jedisClient = RedisUtil.getJedisClient
//导入隐式转换,将样例类转换为json字符串
import org.json4s.native.Serialization
implicit val formats: DefaultFormats.type = org.json4s.DefaultFormats
iter.foreach {
case (orderId, (orderInfoOpt, orderDetailOpt)) =>
//定义redis的key
val orderKey = s"order:$orderId"
val detailKey = s"detail:$orderId"
//判断order是否为空
if (orderInfoOpt.isDefined) {
//order
val orderInfo = orderInfoOpt.get
if (orderDetailOpt.isDefined) {
//order_detail不为空,保存到集合 => 订单数据来晚了
val orderInfoDetail = orderDetailOpt.get
noUserSaleDetails += new SaleDetail(orderInfo, orderInfoDetail)
}
//orderInfo数据无条件写入redis
//scala 将样例类对象转换为json字符串
val jsonStr: String = Serialization.write(orderInfo)
jedisClient.setnx(orderKey, jsonStr)
//设置过期时间
jedisClient.expire(orderKey, 300)
//无条件查询detail缓存
val details: util.Set[String] = jedisClient.smembers(detailKey)
import collection.JavaConversions._
details.foreach((detail: String) => {
//将str => orderDetail
val orderDetail = JSON.parseObject(detail, classOf[OrderDetail])
noUserSaleDetails += new SaleDetail(orderInfo, orderDetail)
})
} else {
//order 为空,则 order_detail 一定不为空
val orderDetail = orderDetailOpt.get
//获取order缓存数据,如果有直接join,如果没有把自己写入redis
val orderStr = jedisClient.get(orderKey)
if (orderStr != null) {
//存在 => 订单详情数据来晚了
val orderInfo = JSON.parseObject(orderStr, classOf[OrderInfo])
noUserSaleDetails += new SaleDetail(orderInfo, orderDetail)
} else {
//不存在 => 订单详情数据来早了
val orderDetailStr = Serialization.write(orderDetail)
jedisClient.sadd(detailKey, orderDetailStr)
//设置过期时间
jedisClient.expire(detailKey, 300)
}
}
}
//关闭连接
jedisClient.close()
noUserSaleDetails.toIterator
})
评论区