


本文侧重与从生产环境角度出发来搭建一个 kafka 集群,因此默认读者已经初步了解 kafka 的架构、使用并搭建过测试环境的 kafka 集群。本文主要介绍如何设置 zk,还会介绍 kafka 的基本配置,以及简单的聊一聊如何为 kafka 选择合适的硬件,最后谈谈把 kafka 应用到生产环境我认为需要注意的事项。
一、要事先行
1.1 选择操作系统
kafka 作为使用 java 开发的应用程序,所以可以运行在 windows、mac、linux 等多种操作系统上,但运行在 linux 系统上是最为常见的,也是作为 kafka 一般性用途
1.2 安装 java
虽然 zk 和 kafka 只需要 java 运行时环境即 jre,以备不时之需还是建议安装完整的 jdk;假设到这里 java 环境已经准备好了
1.3 安装 zk
kafka 使用 zk 保存集群的元数据信息和消费者信息,虽然 kafka 在 2.8 之后推出了 kraft 模式脱离了对 zk 的依赖,但目前还没有广泛的运用在生产环境。
因为 zk 使用的是一致性协议,所以建议每个 zk 集群应该包含奇数个节点,但也不建议包含超过七个节点,因为过多的节点会降低整个集群的性能(zk 保证了最终一致性,会有较短时间的内部同步过程,期间不提供服务)。zk 具体安装方式不做过多介绍,下面介绍一下 zk 的配置文件(假设现在有三台服务器分别是vm001、vm002、vm003)
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/hdp/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
4lw.commands.whitelist=*
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
server.0=vm001:2888:3888
server.1=vm002:2888:3888
server.2=vm003:2888:3888
配置详解:
- initLimit:表示从节点与主节点之间建立初始化连接的时间上限,作用于集群启动阶段
- syncLimit:表示从节点与主节点处于不同步状态的时间上限,作用于主节点选举、数据同步阶段
- tickTime:为 initLimit、syncLimit 的时间单位,二者都是 tickTime 的倍数关系,单位毫秒,例如上述配置 initLimit 时间为 10 * 2000ms = 20s
- dataDir:zk 存放数据目录
- clientPort:客户端连接 zk 的端口
- 4lw.commands.whitelist:zk 允许调用四字命令的ip白名单
zk 服务器地址配置遵循 server.X=hostname:peerPort:leaderPort
- X:服务器 ID,必须是一个证书,不要求从 0 开始也不要求必须连续
- hostname:服务器名或 IP
- peerPort:节点间通信的 TCP 端口
- leaderPort:leader 选举的 TCP 端口
1.4 zk 四字命令
zk 通过配置的 4lw.commands.whitelist 内的 ip 访问集群任意节点的 2181 端口发送四个单词的命令来快速获取集群信息,简称:四字命令
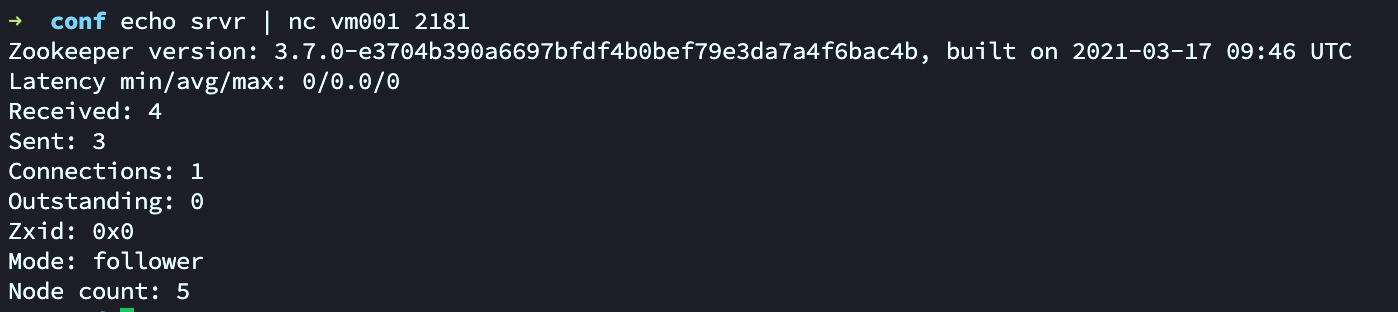
可通过 nc 或者 telnet 来发送,例如:srvr 获取服务器信息
echo srvr | nc vm001 2181
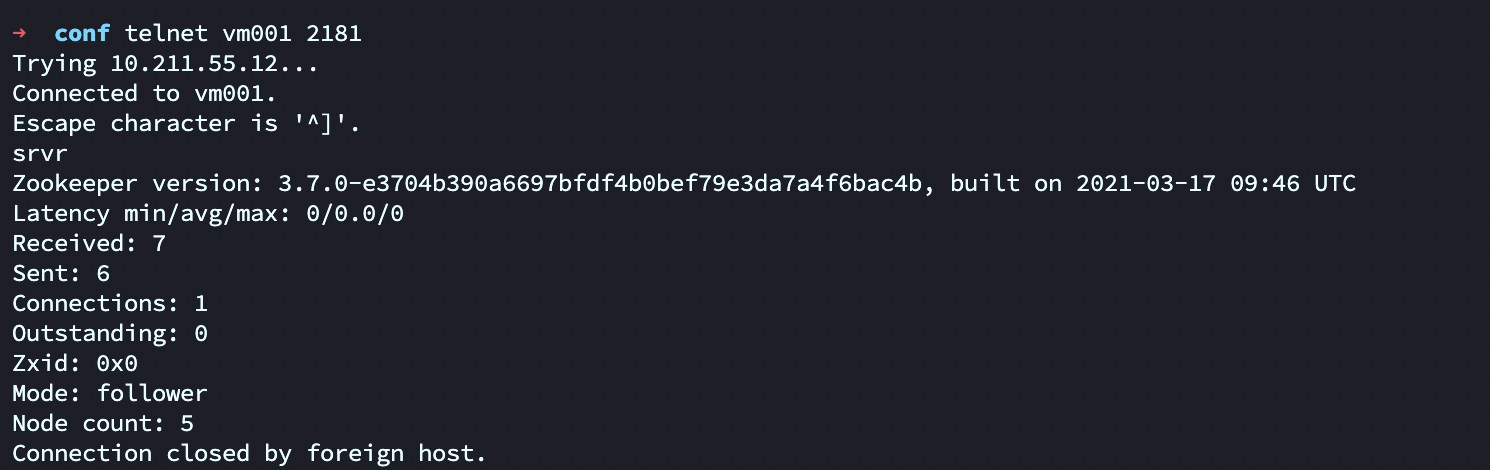
或通过 telnet
telnet vm001 2181
常用的四字命令有:
- conf:获取集群配置信息
- cons:统计这台zk服务器客户端的连接会话信息
- crst:重置所有连接会话的统计信息
- dump:获取比较重要的会话和临时节点,只能在 leader 上使用
- envi:获取集群环境变量
- reqs:获取未处理的请求
- srvr:获取这台zk服务器信息
- wchs:获取集群watch信息
- mntr:输出用于检测集群健康状态的变量
二、安装 kafka
kafka 的安装流程就不在赘述,这里主要是为了详解 kafka 的配置文件详情,明白 kafka 的 server.properties 文件每个配置项的含义以及配置的标准。
2.1 常规配置
broker.id
集群的每个 broker 都需要一个唯一标识,使用 broker.id 来表示,默认值为 0,可以是任意整数,但集群内必须唯一。建议 broker.id 与主机名存在映射关系,例如:vm001 的 broker.id 配置为 1
port
kafka 监听的端口,默认为 9092,可以设置其他任意可用端口,但若使用 1024 以下的端口需要使用 root 权限启动,因此不建议这么做
zookeeper.connect
用户保存 broker 元数据的 zk 地址,建议将 zk 集群的所有 ip:port 全部配置上用逗号隔开,虽然 kafka 只会选择其中一个节点与之交互,但多个地址可以在 zk 部门节点不可用的情况下故障转移到其他可用地址。同时建议只用 chroot 方式如:
zookeeper.connect=vm001:2181,vm002:2181,vm003:2181/kafka
chroot 的好处首先 kafka 的元数据默认会打散创建在 zk 的根目录,导致 zk 上会有很多关于 kafka 的目录这样不利于后期维护,同时该 zk 集群可能会共享给其他应用,最终的结果是 zk 的目录很混乱,chroot 方式 kafka 会事先创建一个 znode(如果不存在的话),之后将相关目录放入其中;其次一个 zk 可能会被其他多个 kafka 集群所共享,这样给每个 kafka 集群指定一个 chroot 是一个最佳实践
log.dirs
配置 kafka 日志片段的存放目录,它是一组用逗号隔开的本地文件系统路径;如果指定了多个路径,kafka 会根据"最少使用"原则,把同一个分区的日志片段保存到同一个路径下。
tips:kafka 的最少使用原则是根据分区数也即文件夹个数最少而不是磁盘占用空间
num.recovery.threads.per.data.dir
配置线程数处理日志,kafka 在如下三种情况会启动线程来处理日志片段
- 服务正常启动,启动线程来打开每个分区日志片段
- 服务正常关闭,启动线程来关闭每个分区日志片段
- 服务崩溃后重启,启动线程来检查和截断每个分区日志片段
默认情况下每个日志目录只使用一个线程,这些线程只有在服务启动或关闭的时候才会用到,因此完全可以设置大量的线程来达到并行操作的目的,对于拥有大量主题和分区的集群来说,一旦发生崩溃,在多个线程并行恢复时会省下大量的时间。
tips:该参数是对应目录个数来说的,例如若 num.recovery.threads.per.data.dir = 10 同时 log.dir 配置了三个存储路径,那么在启动或关闭时会开启 3 * 10 = 30 个线程
auto.create.topics.enable
默认情况下,kafka 在如下三种情况会自动创建主题
- 当生产者向不存在的主题写入消息时
- 当消费者向不存在的主题读取消息时
- 当客户端向主题发送元数据的请求时
但这些行为都是未预期的,因此非常建议关闭自动创建,根据具体的业务场景评估创建主题的元数据
2.2 主题配置
kafka 为新建的主题提供了很多默认参数,当然也可以为每个主题单独配置一部分参数,比如分区副本个数,数据保留时间这是很有必要的。
num.partitions
指定新建主题将包含多少个分区,默认值为 1;kakfa 就是通过分区数来实现横向扩展,还可以通过分区实现负载均衡,因此对于已经存在的主题该参数也可以动态调整,但是该参数只能增加不能减少(显而易见,减少的分区数据怎么处理这是一个很复杂的问题),那么如何选定分区的个数将会是一门艺术,通常会考虑如下几点:
- 主题需要多大的吞吐量
- 单个分区读取数据的最大吞吐量是多少?也就是每个消费者的消费能力
- 同样的方式可以预估生产者的生产能力
- 综合考虑服务器的磁盘以及网络带宽
- 但是对于整个集群来说,分区数越多占用的内存就越多,选举 leader 的时间也就越长
例如:如果期望主题的吞吐量为 1G/s,消费者平均的消费速度为 50M/s,那么至少需要 20 个分区;若这些信息都无法评估,可以把分区的大小限制在 25G 之内有比较理想的效果。
log.retention.ms
kafka 根据时间决定数据可以被保留多久,默认使用 log.retention.hours 参数来配置时间,默认值为 168 小时(7天),除此之外还有 log.retention.minutes,若指定了不止一个参数,kafka 会选择最小的时间
tips:根据时间保留数据 kafka 的实现逻辑是通过检查磁盘上日志片段最后的修改时间来实现的。通常来说最后的修改时间就是最后一条数据被写入的时间也就是日志关闭的时间;但若通过命令在服务器之间移动分区会改变这个时间,因此会让数据保留变的不准确。同时只有日志片段处于关闭状态才开始计算过期时间
log.retention.bytes
kafka 根据日志片段的字节数判断是否过期,该参数作用于每一个分区,默认 1G 多出来数据就会被删除;也就是说假如一个主题有 10 个分区,那么这个主题最多可以保存 10G 的数据。
tips:log.retention.ms、log.segment.bytes 只要一个条件得到满足消息就会被删除,也就是说即使日志片段没有到 1G 默认 7 天后也会被删除(主题数据量小的情况)或日志片段没有到 7 天也会被删除(主题数据量特别大的情况)
log.segment.bytes
当消息到达 broker 时会被追加到对应分区的当前日志片段上,当日志片段字节数达到 log.segment.bytes 上限时(默认 1G)当前日志片段会被关闭,同时开启一个新的日志片段;只有处于关闭状态的日志片段 kafka 才会运用删除策略,因此当 log.segment.bytes 的值特别小时,就会频繁地关闭并分配日志片段,从而降低磁盘写入的整体效率。但当主题整体数据量不大时 log.segment.bytes 的配置将尤为重要,例如一个主题每日数据量为 100M,要达到默认的 log.segment.bytes 上限需要 10 天,再此期间该日志片段永不过期,假设过期时间为 7 天,那么该片段会在 10 天后关闭,并在之后的 7 天被删除(通常可以理解为该片段的最后一条数据过期),那么该片段将会被保存 17 天。
tips:log.segment.bytes 参数还会影响消费者,当消费者通过时间戳来获取偏移量时,kafka 会根据日志片段的最后修改时间来进行二分查找,因此 log.segment.bytes 的参数越小,消费者获取偏移量就会越快越准确
log.segment.ms
另外一个可以控制日志片段关闭的参数,同 log.retention.ms、log.segment.bytes 功能一样,与 log.segment.bytes 不存在互斥,满足一个就可以关闭日志片段,默认情况 log.segment.ms 没有被设置只通过日志片段的字节数判断是否被关闭。
tips:使用时间来控制日志片段是否应该被关闭需要重点考虑并行关闭日志片段对磁盘性能的影响。如果集群整体的数据量不大就存在大量分区永远达不到 log.segment.bytes 上线,也就是说基于时间关闭的策略会提前执行,那么大量日志片段被关闭总是同时发生,这是一个需要考虑的影响。
message.max.bytes
该参数用来限制单个消息的大小默认 1M,如果生产者尝试发送超过这个限制的消息时,broker 会拒绝接收并返回一个错误信息,注意对消息大小的限制是压缩后的大小。因此对消息启用压缩是一个很好的选择。同时该值对 kafka 整体性能会产生非常大的影响,因为太大的消息负责网络连接和请求的线程将会花费大量的时间来处理,同时 follower 在同步数据也会占用更多的 IO,同时 因为 replica.fetch.max.byte 的参数影响同步复制消息上限,若小于 message.max.bytes 时在同步大于 replica.fetch.max.byte 时会发生同步失败,此时若发生了 leader 重新选举将产生数据的丢失。
tips:replica.fetch.max.byte 还需要和消费者的 fetch.message.max.bytes 进行协调,若小于 replica.fetch.max.byte,消费者在拉取较大的消息时会被阻塞,上述的 replica.fetch.max.byte 同样如此。
2.3 硬件选择
kafka 本身对硬件没有特别的要求,如果比较关注性能,那么就需要考虑磁盘、内存、网络、cpu,在既定的预算内选择最优化的硬件配置
高影响
- 磁盘吞吐量:再生产环境上生产者的 ack 大多是 1 或者 all,也就是至少有一个节点同步落盘才会确认消息,也就是说消息写入速度越快,生产者延迟越低。
- 内存:磁盘吞吐量影响生产者,那么内存会影响消费者;消费者一般都是从分区尾部读取数据,如果有生产者存在此时消费者就紧跟生产者,消费者读取的数据会直接存放在系统的页面缓存中。同时运行 kafka 的 jvm 并不需要太大的内存,剩余的系统内存都可以用作页面缓存,这也是为什么不建议在 kafka 集群中安装其他应用程序,这样会导致页面内存被共享最终降低 kafka 性能
- 网络:网络吞吐量确定 kafka 能处理数据的上限。
低影响
- 磁盘空间:根据业务场景决定数据保存时间,磁盘空间能达到预估的数据量即可。
- cpu:kafka 对计算处理能力要求相对较低,在对消息进行压缩、解压以及偏移量相关操作会涉及cpu计算,但不会成为 kafka 的性能瓶颈。
2.4 垃圾回收
JVM 的垃圾回收配置需要进行大量的观察和试错,但随着 jdk1.7 引入的 G1 垃圾回收器,可以执只进行少量的配置就可以完成根据工作负载自我调整垃圾回收时间,可以轻松处理大块的堆内存。
MaxGCPauseMillis
指定每次垃圾回收默认的停顿时间,默认 200ms,但是 G1 可以根据当时的负载来动态规划停顿时间,该参数可以理解为 G1 的平均停顿时间
InitiatingHeapOccupancyPercent
在新一轮垃圾回收之前可以使用堆内存百分比,默认 45%,也就是说在堆内存使用率达到 45% 之前 G1 不会启动垃圾回收
kafka 对堆内存的使用率特别高,容易产生垃圾,所以可以将上述值设置的小一点让 G1 比默认的要早一点启动。同时 kafka 的启动脚本并没有启用 G1 垃圾回收,而是使用了 Parallel New 和 CMS(标记清除)垃圾回收,可以在启动脚本或者环境变量中修改:
export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+DisableExplicitGC -Djava.awt.headless=true"
2.5 架构选择
数据中心布局
最好把集群的 broker 安装在不同的机架上,至少不要让他们共享可能出现故障的基础设施,比如:电源、网络
共享zk
kafka 对 zk 的延迟和超时比较敏感,zk集群之间的通讯异常会导致 kafka 出现无法预测的行为,甚至集体离线,因此建议每个 kafka 独享自己的 zk 集群
评论区