


本文的理论思想来源于 JuiceFs 社区的一篇文章《从 Hadoop 到云原生,大数据平台如何做存算分离》,本文分为理论+实践两个部分,理论部分是对社区文章的总结、实践部分则是对理论的落地探索企业对 hadoop 生态的改造
一、大数据平台如何做存算分离
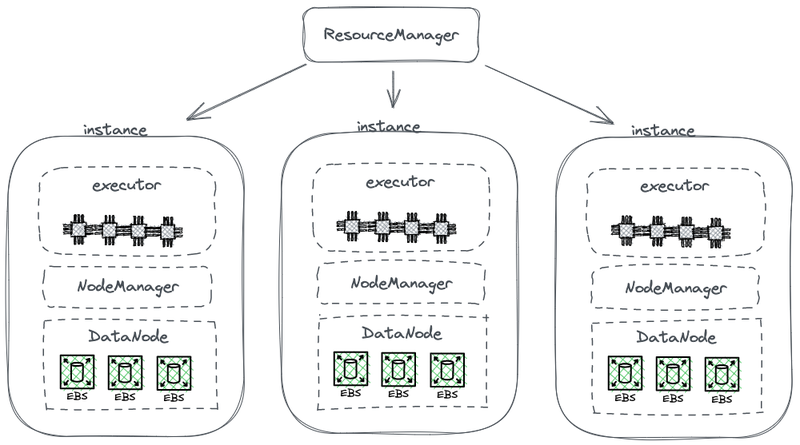
1.1 hadoop 存算耦合架构回顾
hadoop 作为大数据时代的开山组件,作为一个 all-in-one 套件有三个核心组件:MapReduce负责计算、Yarn负责资源调度、HDFS负责存储。在这三个组件中,发展最迅速和多元的是计算组件这一层,最早只有一个 MapReduce,但业界很快在计算层上面各显神通,造出了一大堆的轮子,包括有 MapReduce,Tez,Spark 这样的计算框架,Hive 这类数据仓库,还有 Presto、Impala 查询引擎,各种各样的组件。配合这些组件的,还有像 scoop 这样的数据流转采集的组件也很丰富,一共有几十款。
但底层存储经过了大概 10 年左右的时间,一直是 HDFS 一枝独秀,带来的一个结果就是它会成为所有计算组件默认的设计选择。上面提到的这些大数据生态里发展出来的各种组件,都是面向HDFS API 去做设计的。有些组件也会非常深入的利用 HDFS 的一些能力,比如深入看 Hbase,在写 WAL log 的时候就直接利用了HDFS 的一些很内核的能力,才能达到一个低时延的写入;比如说像最早的 MapReduce 和 Spark 也提供了数据亲和性(Data Locality)的能力,这些都是HDFS 提供的一些特殊的 API。这些大数据组件面向 HDFS API 设计的做法, 为后续数据平台上云带来了潜在的挑战。MapReduce等计算框架针对海量数据还提出了“移动计算”的计算模型和本地读取的设计思想,其主要原因就是网络带宽是一个瓶颈。这些都促使 hadoop 在设计之初就是一个存算耦合的架构。
1.2 存算分离需求的出现
从企业需求来看,2006年到2016年的十年发展。企业数据增长很快,但算力的需求其实长得没那么快,这些计算任务不会发生一天一倍的去涨的情况,但是产生的数据的速度是是非常快的,有可能是指数型的;而且有些数据产生出来,也不一定马上知道怎么用,但未来会用,所以企业都会先把数据尽可能全量的去存起来,再去挖掘它的价值。在这个背景下,存算耦合的硬件的拓扑的架构就给扩容带来了一个影响,当存储不够,就要去加机器。但是不能只加机器,不能只有硬盘,因为在存算耦合的架构上,数据的节点还需要负责计算,所以 CPU 和内存也不能太差。因此配置的机器都是计算与存储配置非常平衡的机器,在提供足够存储容量的同时,也提供了等量的算力。但实际场景中算力的需求没涨。这样扩出来的算力对企业来说造成了更大的浪费,整个集群在存储和 I/O 上的资源利用率可能是非常不平衡的,**当集群越大,这种不平衡就越严重。而且另外买机器也挺难的,购买的机器必须是计算与存储平衡的。**在这个过程中硬件也发生了翻天覆地的变化,带宽将不在是限制,这给存算分离架构带来了可行性。
1.3 如何实现存算分离
1. 最初的尝试:云上部署 hdfs
最初的方案比较简单,就是独立部署 HDFS,不再和负责计算 worker 去混合部署。这个方案在 Hadoop 生态里,没有引入任何的新组件。即 DataNode 节点上不再部署 NodeManager,存储成为独立的集群,计算需要用到的数据都会通过网络来传输,端到端的万兆网卡去支持。在这个改变里,尽管 HDFS 最巧妙的数据本地性这个设计被舍弃了,但由于网络通讯速度的提高,给集群的配置带来更大的便利。但是这个架构没有得到进一步发展,是什么原因呢?最大的一个原因,当在机房做这样的改造是可行的,但当我们去使用云上资源的时候,这个方案的弊端就显露了。
首先,源自于 HDFS 的多副本机制在云上会增加企业的成本。过去为了避免裸硬盘的损坏 HDFS 设计了多副本机制来保证数据的安全性,同时多副本机制还承担数据的可用性,因为除了磁盘的损坏还存在 DataNode 宕机的情况。当 HDFS 被迁移到云上,云厂商提供的云盘也是经过多副本机制,企业用云盘搭建 HDFS 再去配置软件层面的多副本,如果都是三倍冗余那么企业数据在云上就要存 9 份,成本飙升好几倍。后来云厂商也提供一些裸硬盘机型,但这类机型往往非常少且型号不一定符合企业要求。
其次,这个方案依然是需要企业去云上部署 HDFS 集群,需要自己创建机器、监控和维护。企业并没有得到云上的独特优势,对于如开箱即用、弹性伸缩、按量付费等。
最后,由于 HDFS 本身的限制,当集群存储文件过多时 NameNode 的内存将是集群的瓶颈,负载高容易触发 FullGC 影响集群的可用性,这就需要引入 HDFS 的 Federation 机制,但它就增加了运维和管理的成本。
2. 公有云+对象存储
随着云计算技术的成熟,企业存储又多了一个选项————对象存储。最早从 AWS 开始,后来所有的云厂商其实都在往这个方向发展,开始推动用对象存储去替代 HDFS。这些方案首先带来了两个 HDFS 无法实现的最明显的好处:
- 对象存储是服务化的,开箱即用,不用做任何的部署监控运维这些工作
- 弹性伸缩,企业可以按量付费,不用考虑任何的容量规划,开一个对象存储的 bucket ,有多少数据写多少数据,不用担心写满(只要你付得起账单就是无限存储)
这些方案相比在云上独立部署 HDFS , 运维方面是有了很大的简化。但当对象存储被用来去支持复杂的 Hadoop 这样的数据系统,就会发现如下的一些问题。
- 文件 Listing 的性能比较弱。对象存储的元数据结构是扁平的,当用户需要存储成千上万,甚至数亿个对象,对象存储需要做的是用 Key 去建立一份索引,Key 可以理解为文件名是该对象唯一标识符。如果用户要执行 Listing,只能在这个索引里面去搜索,搜索的性能相比文件系统树形结构的查找弱很多。
- 对象存储没有原子 Rename, 影响任务的稳定性和性能。在 ETL 的计算模型中,每个子任务完成会将结果写入临时目录,等到整个任务完成后,把临时目录改名为正式目录名即可。但由于对象存储没有原生目录结构,处理 rename 操作是一个模拟过程,会包含大量系统内部的数据拷贝,会耗时很多,而且没有事务保证。
- 对象存储数据最终一致性的机制,会降低计算过程的稳定性和正确性。举个例子,比如多个客户端在一个路径下并发创建文件,这是调用 List API 得到的文件列表可能并不能包含所有创建好的文件列表,而是要等一段时间让对象存储的内部系统完成数据一致性同步。这样的访问模式在 ETL 数据处理中经常用到,最终一致性可能会影响到数据的正确性和任务的稳定性。
3. 对象存储+Juicefs
下面是 Juicefs 的部署架构图
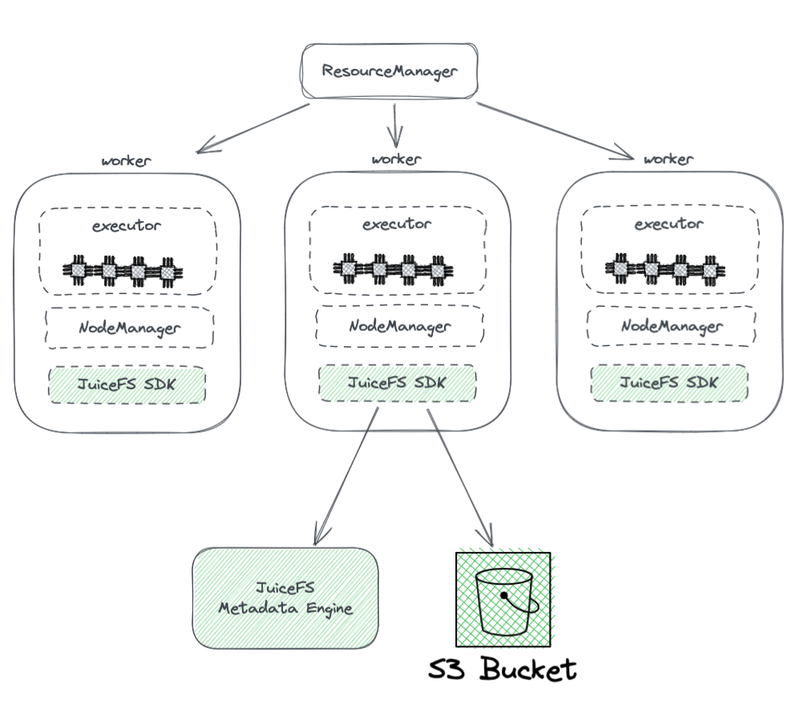
YARN 管理的这些执行节点上,都带一个 JuiceFS Hadoop SDK, 这个 SDK 可以保证完整兼容 HDFS。图片下方可以看到, SDK 它需要访问两个部分,左侧是 JuiceFS Meta Engine,右侧是 S3 bucket。Metadata engine 就相当于 HDFS里的 NameNode,整个文件系统的元数据信息会存储在这里,元数据信息包括目录数、文件名,权限时间戳这些信息,并且相应的解决掉了 HDFS NameNode 扩展性 、GC 这些的痛点。相较于直接使用对象存储, JuiceFS 还有哪些优势呢?
- HDFS 100% 兼容。可以和 HDFS 一块使用,在 Hadoop 集群中可以配置多个文件系统。可以结合着业务,结合着集群的情况,分步分批的去做融合。
- 元数据性能强大。JuiceFS 将元数据引擎独立出来不再依赖于 S3 里面的原数据性能,保证了元数据的性能。
- 原子 rename。因为有独立的原数据引擎,JuiceFS 也可以支持原子 rename。
- 缓存。为了复现数据本地化特性,提高热数据访问性能,Juicefs 支持将反复读取的热数据缓存在 worker 节点的本地磁盘。
- 兼容 POSIX 协议。
二、Juicefs 实战
2.1 Juicefs + oss 部署
Juicefs支持市面上几乎所有的对象存储,这里则使用 minio 作为对象存储的实现,下面演示 docker 部署,其他部署模式可参考这个。
mkdir -p ~/minio/data
docker run -d\
-p 9000:9000 \
-p 9090:9090 \
--name minio \
-v ~/minio/data:/data \
-e "MINIO_ROOT_USER=ROOTNAME" \
-e "MINIO_ROOT_PASSWORD=NIXIANGBUDAODEMIMA" \
quay.io/minio/minio server /data --console-address ":9090"
注:9000 为 API 端口,9090 为 web 端口
创建一个用于测试的 bucket
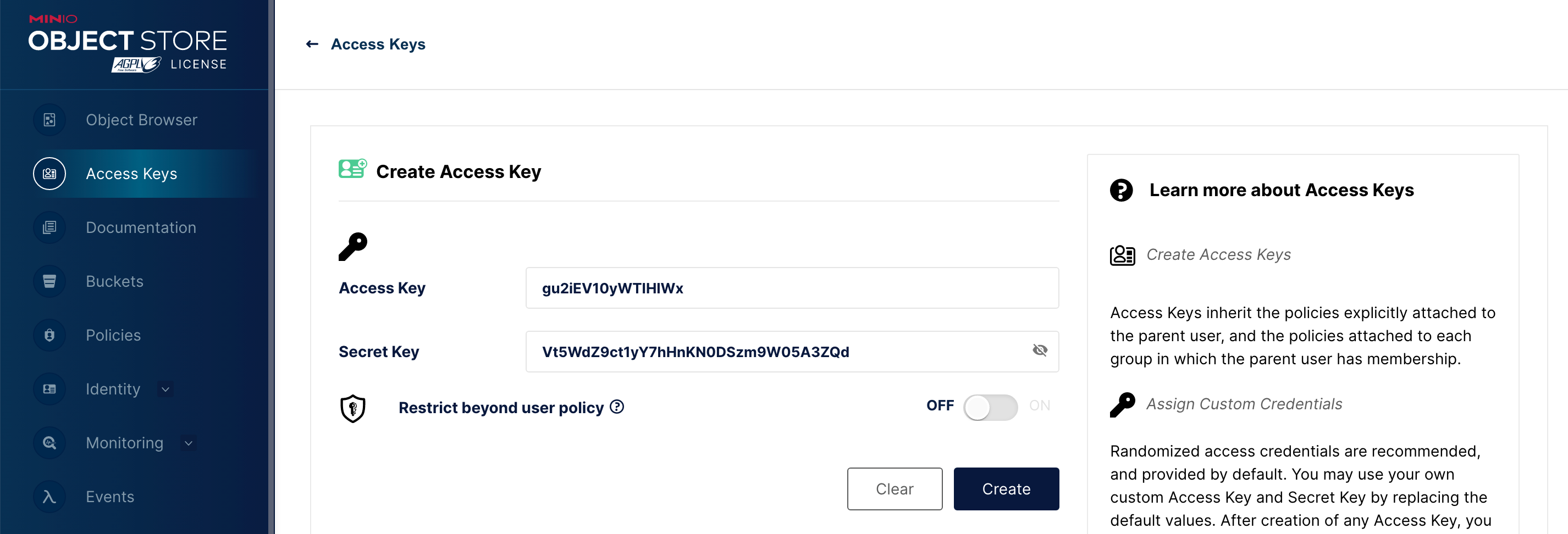
创建一个用于测试的 access key(默认自动生成,可以根据自己喜好自定义)
因为 juicefs 的元数据系统是独立于对象存储之外的,需要我们自己部署元数据系统。允许多个用户通过网络同时访问的数据库,从这个角度出发,可以简单的把数据库分成:
- 单机数据库:数据库是单个文件,通常只能单机访问,如 SQLite,Microsoft Access 等;
- 基于网络的数据库:数据库通常是复杂的多文件结构,提供基于网络的访问接口,支持多用户同时访问,如 Redis、PostgreSQL 等。
JuiceFS 目前支持的基于网络的数据库有:
- 键值数据库:Redis、TiKV
- 关系型数据库:PostgreSQL、MySQL、MariaDB
不同的数据库性能和稳定性表现也各不相同,比如 Redis 是内存型键值数据库,性能极为出色,但可靠性相对较弱。PostgreSQL 是关系型数据库,相比之下性能没有内存型强悍,但它的可靠性要更强。
这里使用 Redis 作为元数据引擎,同样是用 docker 部署,个人比较喜欢 bitnami 的开源镜像。
docker run -d \
-p 6379:6379 \
-e ALLOW_EMPTY_PASSWORD=no \
-e REDIS_PASSWORD=NIXIANGBUDAODEMIMA \
-e REDIS_AOF_ENABLED=no \
--name redis \
-v ~/redis/data:/bitnami/redis/data \
bitnami/redis:latest
到这里准备环境就做好了,首先需要明白一点 juicefs 本质上就是一个客户端,哪个节点、哪个服务想要将数据存储到对象存储中就需要安装 juicefs 客户端或者依赖包。幸运的是 juicefs 提供一键安装脚本
curl -sSL https://d.juicefs.com/install | sh -
Downloading juicefs-1.0.3-linux-amd64.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 24.0M 100 24.0M 0 0 1545k 0 0:00:15 0:00:15 --:--:-- 701k
Install juicefs to /usr/local/bin/juicefs successfully!
# 校验
juicefs --version
juicefs version 1.0.3+2022-12-27.e4bf15a
类似 NameNode 的安装首先需要初始化
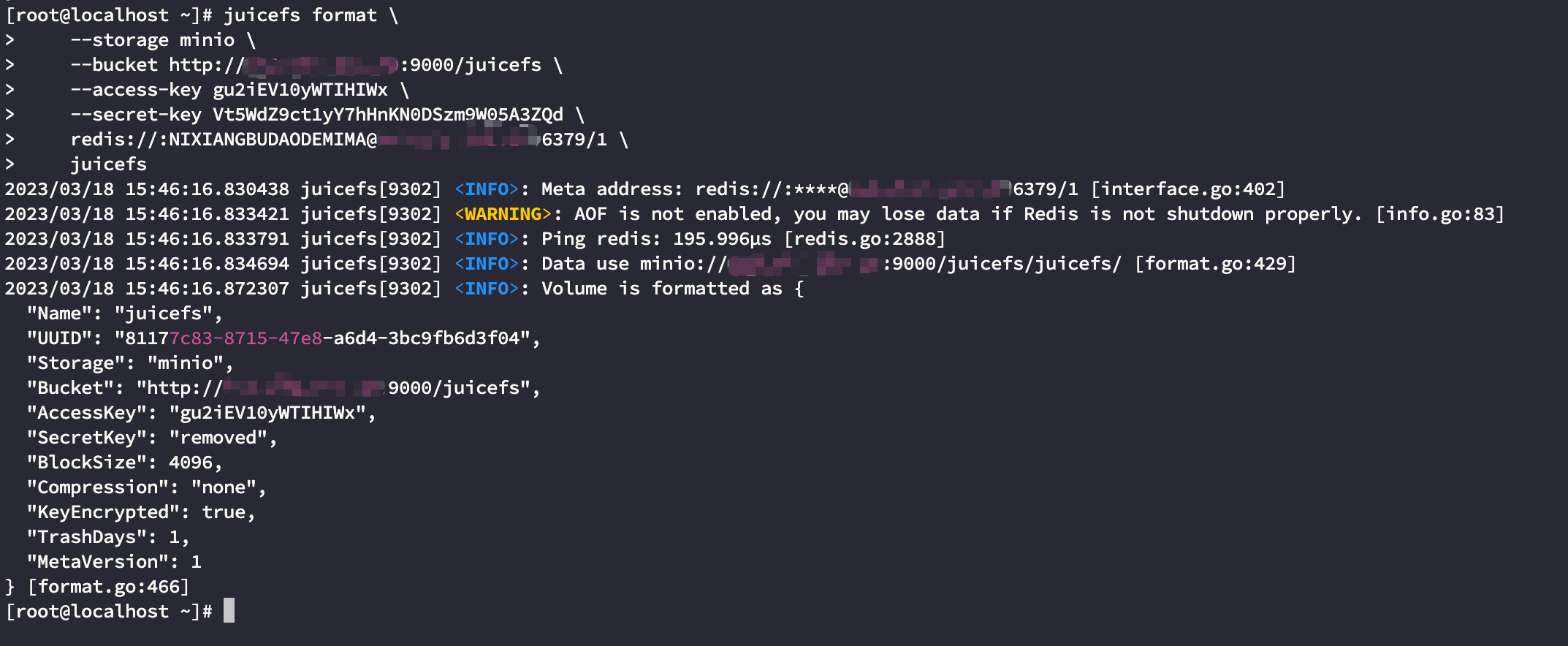
juicefs format \
--storage minio \
--bucket http://xxx.xxx.xxx.xxx:9000/juicefs \
--access-key gu2iEV10yWTIHIWx \
--secret-key Vt5WdZ9ct1yY7hHnKN0DSzm9W05A3ZQd \
redis://:NIXIANGBUDAODEMIMA@xxx.xxx.xxx.xxx:6379/1 \
juicefs
- storage: 对象存储的类型,更多对象存储实现的类型参考这个
- bucket: 桶的 endpoint,不同对象存储的 endpoint 不一致,参考上面的链接
- juicefs:juicefs 的文件系统名称(任意,后续使用 JFS_NAME 泛指)
结果如下:
此时 redis 已经存在若干个 key

后续只要 juicefs 可以访问到这个 redis 元数据系统就可以操作同一个对象存储
2.2 fuse
juicefs 支持 fuse 模式,将对象存储挂载到本地,像操作本地磁盘一样操作对象存储。fuse 模式可以支撑很多有趣的玩法,如各类数据库的热温冷数据的分离,例如将 clickhouse 的热数据存储在本地磁盘,通过配置存储策略和TTL,将温数据自动下沉到由 juicefs 挂载在本地的目录中实现冷热数据分离。其 fuse 也超简单
juicefs mount \
--background \
--cache-dir ~/mycache \
--cache-size 512000 \
redis://:NIXIANGBUDAODEMIMA@115.231.162.10:6379/1 \
~/jfs
缓存机制可以让 juicefs 高效的处理海量数据的读写任务,通过 cache-dir 配置本地缓存路径,并通过 cache-size 指定缓存空间大小

例如将对象存储挂载到 ~/jfs 下
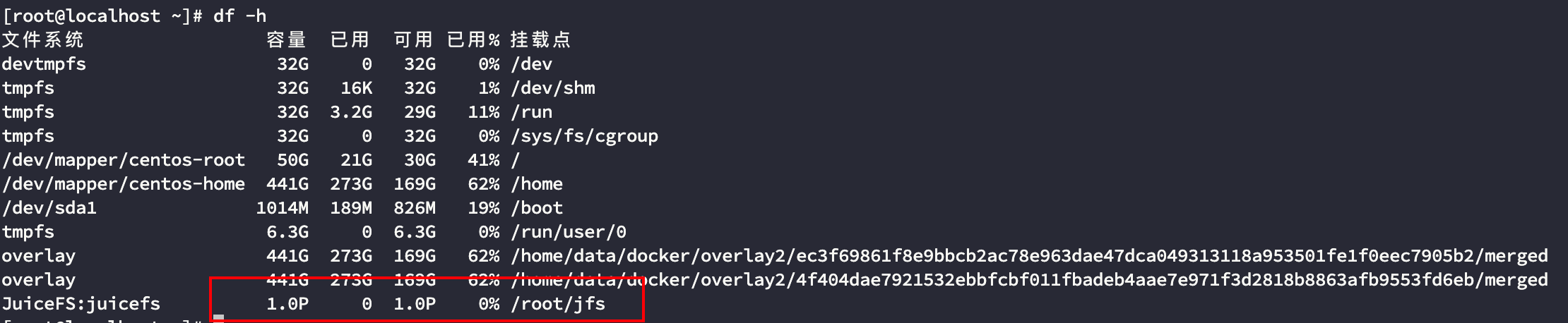
当然肯定没有 1P 的容量,毕竟我的 minio 也是部署在单节点,这里只是体现 juicefs 的一种设计思想,juicefs 只需要做好中间层的 API 就好无需考虑实际存储,因为只要你付得起账单,对象存储就是一个无限的。
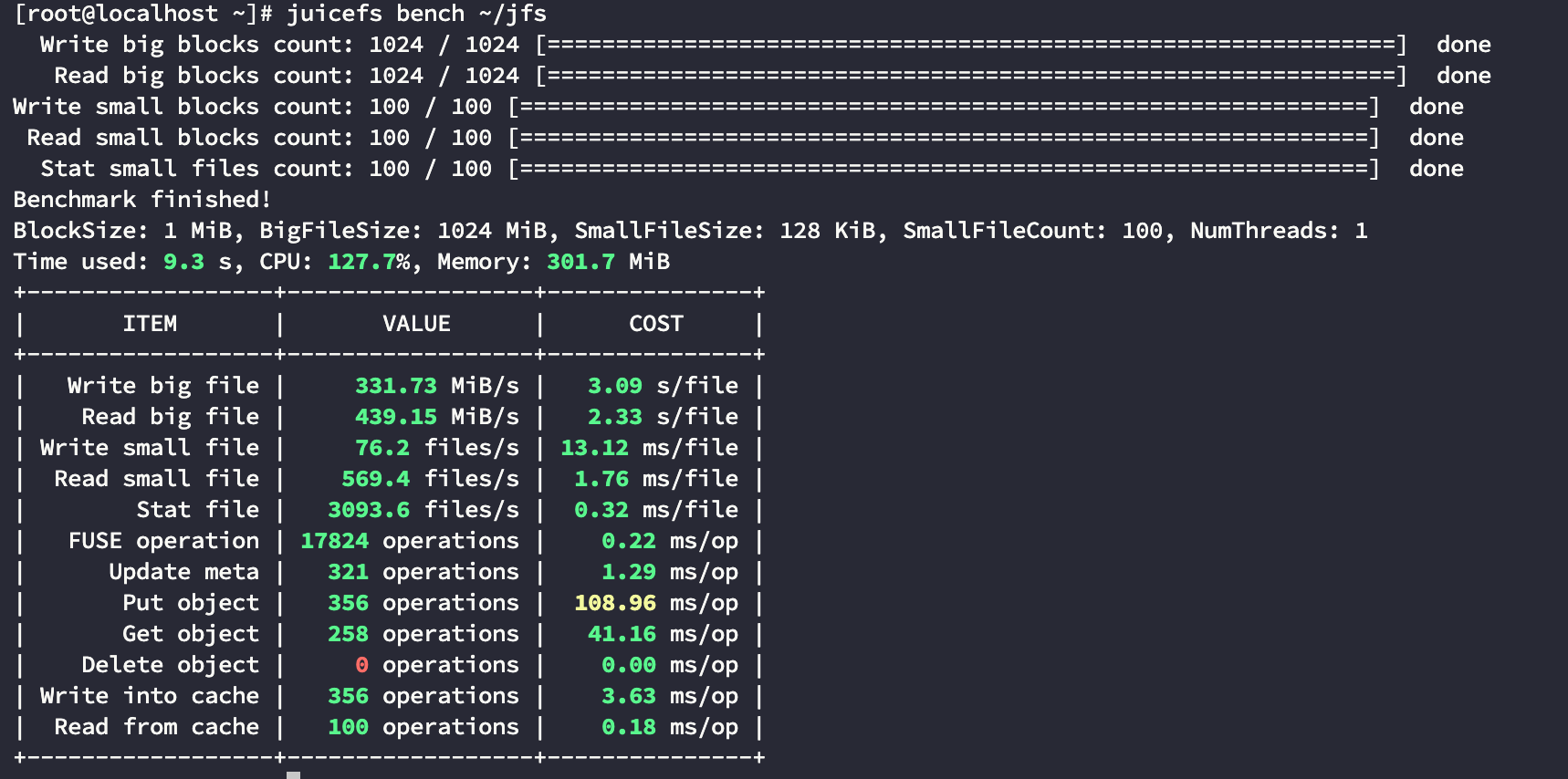
下面操作对象存储就和操作本地文件一样,你可以在 ~/jfs 下任意进行文件操作,例如进行一下压测
卸载文件系统
juicefs umount ~/jfs
如若存在 Device or resource busy 异常表名此时本地进程正有 ~/jfs 的读写操作,尝试等待或终止这个读写进程
注:如在使用过程中发现本地文件系统文件已经删除,但是通过对象存储查看 bucket 容量没有变化,是因为 juicefs 存在回收站机制文件已经从元数据层面被删除并移至 .trash 中
下面则是 juicefs 与 hadoop 生态进行融合
2.3 hadoop
首先一个问题就是为什么不使用上述所说的 fuse 实现 POSIX 接口呢?原因有下面两点:
- fuse 需要提前在 hadoop 集群各个节点安装 juicefs 客户端并挂载
- file:/// 协议在使用 hadoop api 时性能比较差
因此与 hadoop 继承则使用 juicefs 专门为 hadoop 设计的 java 接口,100% 兼容 hadoop api
因为 juicefs 使用 go 开发每个平台都需要自己进行编译,其操作也很简单:
编译依赖的工具
- Go 1.15+
- JDK 8+
- Maven 3.3+
- Git
- make
- GCC 5.4+
git clone https://github.com/juicedata/juicefs.git
cd juicefs/sdk/java
make
编译完成后,可以在 sdk/java/target 目录中找到编译好的 JAR 文件,包括两个版本:
- 包含第三方依赖的包:
juicefs-hadoop-X.Y.Z.jar - 不包含第三方依赖的包:
original-juicefs-hadoop-X.Y.Z.jar
建议使用包含第三方依赖的版本。如果不想编译可以使用官方编译好的全平台通用的 SDK(唯一的缺点就是包比较大)
wget https://github.com/juicedata/juicefs/releases/download/v1.0.3/juicefs-hadoop-1.0.3.jar
将其放入 hadoop classpath 下即可(执行 hadoop classpath 可以查看都有哪些路径),随后配置core-site.xml让 hadoop cli 可以读取到元数据集即可,下面是最小配置
<configuration>
<property>
<name>fs.jfs.impl</name>
<value>io.juicefs.JuiceFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.jfs.impl</name>
<value>io.juicefs.JuiceFS</value>
</property>
<property>
<name>juicefs.meta</name>
<value>redis://:NIXIANGBUDAODEMIMA@xxx.xxx.xxx.xxx:6379/1</value>
</property>
</configuration>
先通过 fuse 挂载本地上传一点(cp)数据用于测试,接下来测试 hadoop cli
hadoop fs -ls -R jfs://juicefs/
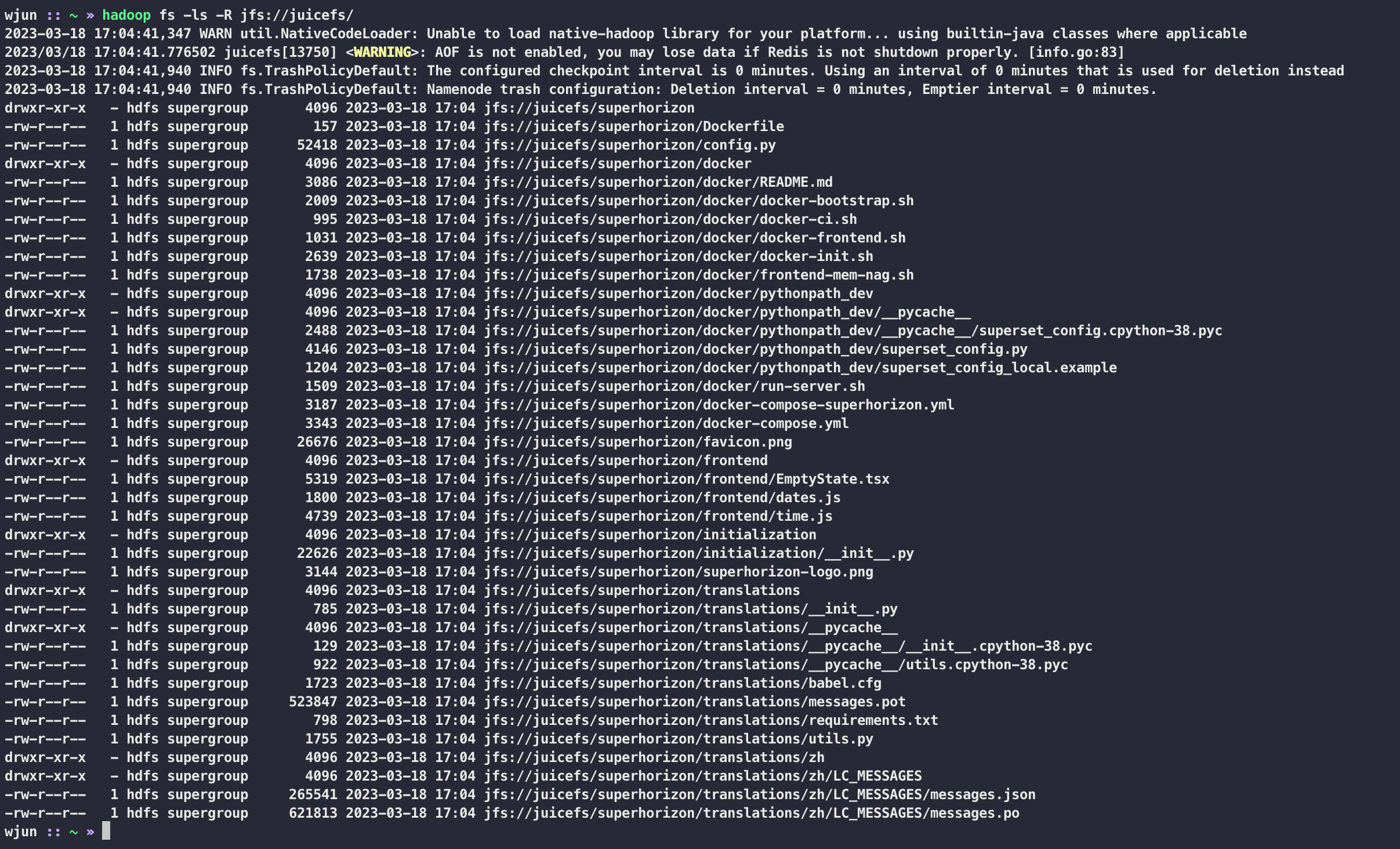
细心的小伙伴可能已经发现了,执行 hadoop cli 的机器已经不是刚才部署的那一台了,命令中的 juicefs 就是 JFS_NAME,下面随意测试一下 hadoop cli 的增删改查
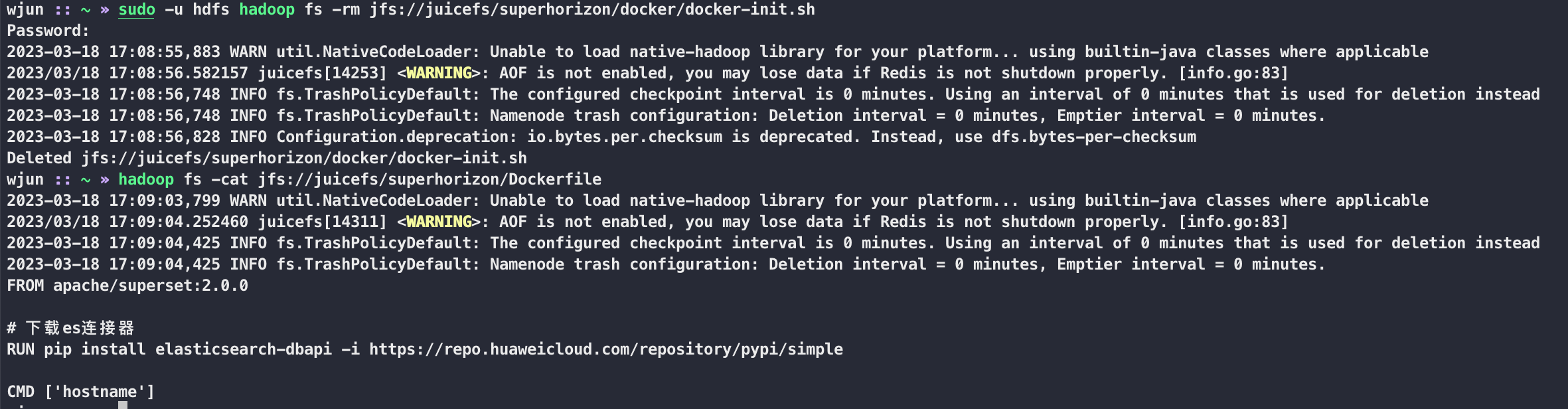
当前的测试机器是我的开发机器,可以发现 juicefs 与之前的 hadoop 是并存的
下面测试使用 hadoop 的 java api 来测试
pom 文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>tech.kpretty</groupId>
<artifactId>juicefs</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.3.4</hadoop.version>
<juicefs.version>1.0.3</juicefs.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>io.juicefs</groupId>
<artifactId>juicefs-hadoop</artifactId>
<version>${juicefs.version}</version>
</dependency>
</dependencies>
</project>
代码如下:
package tech.kpretty.juicefs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author wjun
* @date 2023/3/15 13:55
*/
public class JuiceFsDemo {
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
conf.set("fs.jfs.impl", "io.juicefs.JuiceFileSystem");
conf.set("fs.AbstractFileSystem.jfs.impl", "io.juicefs.JuiceFS");
conf.set("juicefs.meta", "redis://:NIXIANGBUDAODEMIMA@xxx.xxx.xxx.xxx:6379/1");
FileSystem fs = FileSystem.get(new URI("jfs://juicefs/"), conf);
// 上传文件
fs.copyFromLocalFile(new Path("/Users/wjun/Downloads/学习资料/trial.tar.gz"), new Path("/"));
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.printf("%s\t%s\t%s\t%s\n",
fileStatus.getPermission(),
fileStatus.getOwner(),
fileStatus.getGroup(),
fileStatus.getPath()
);
}
fs.close();
}
}
本质上就是将 core-site.xml 文件 set 进去即可,或者 addResource 指定文件路径。运行结果如下
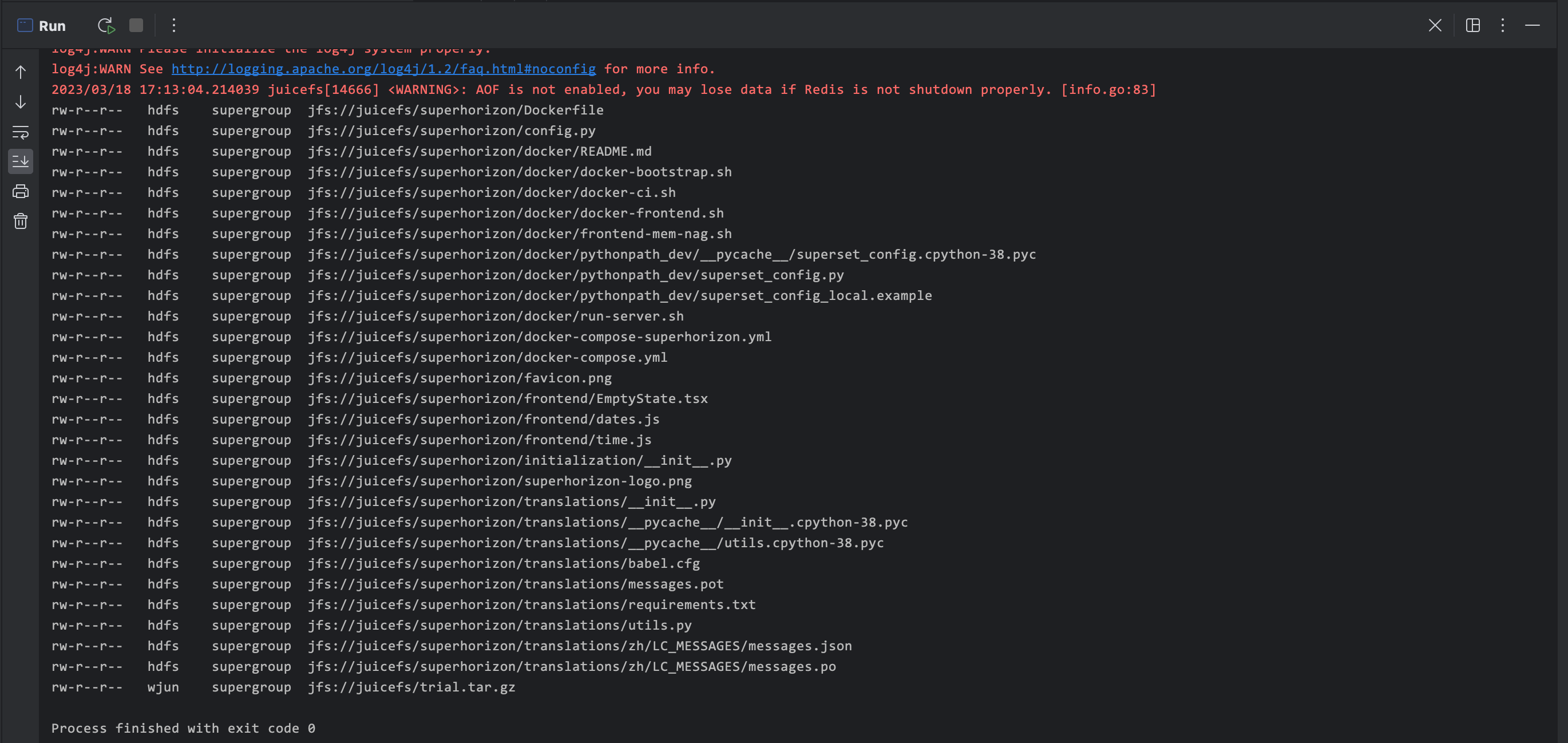
2.4 hive
如果之前环境已经存在 hive 且上述 hadoop 已经配置成功,那么 hive 就什么都不需要了,直接启动即可
创建数据库并将 location 指向 jfs,这样后续该库下面的表默认都创建 jfs 下
hive (default)> create database juice_demo location 'jfs://juicefs/user/hive/warehouse/juice_demo';
2023/03/18 17:20:11.957141 juicefs[16680] <WARNING>: AOF is not enabled, you may lose data if Redis is not shutdown properly. [info.go:83]
OK
Time taken: 1.663 seconds
--------------------
hive (default)> use juice_demo;
OK
Time taken: 0.022 seconds
下面进行一些简单测试
创建表并查看表结构
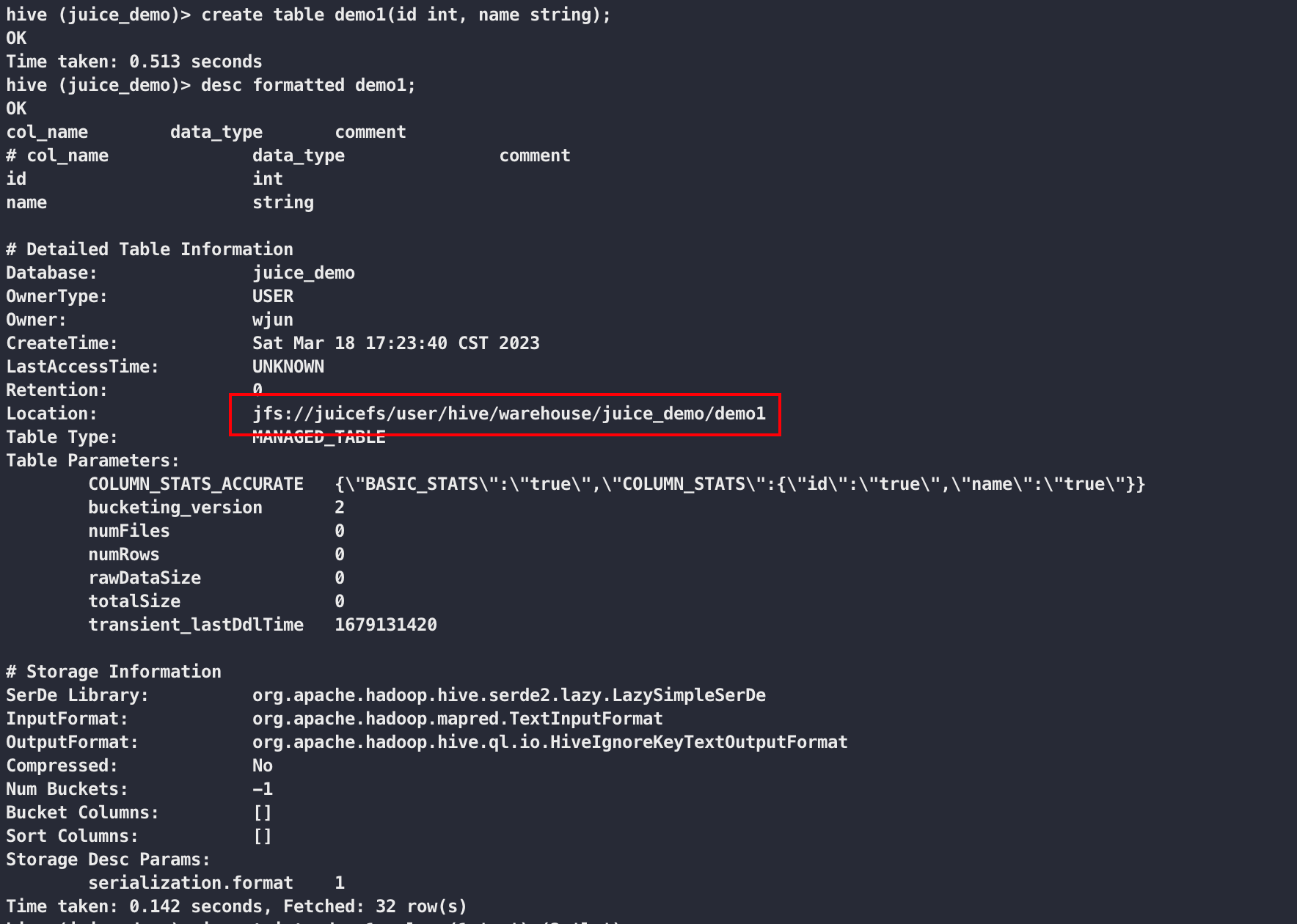
插入数据并查询
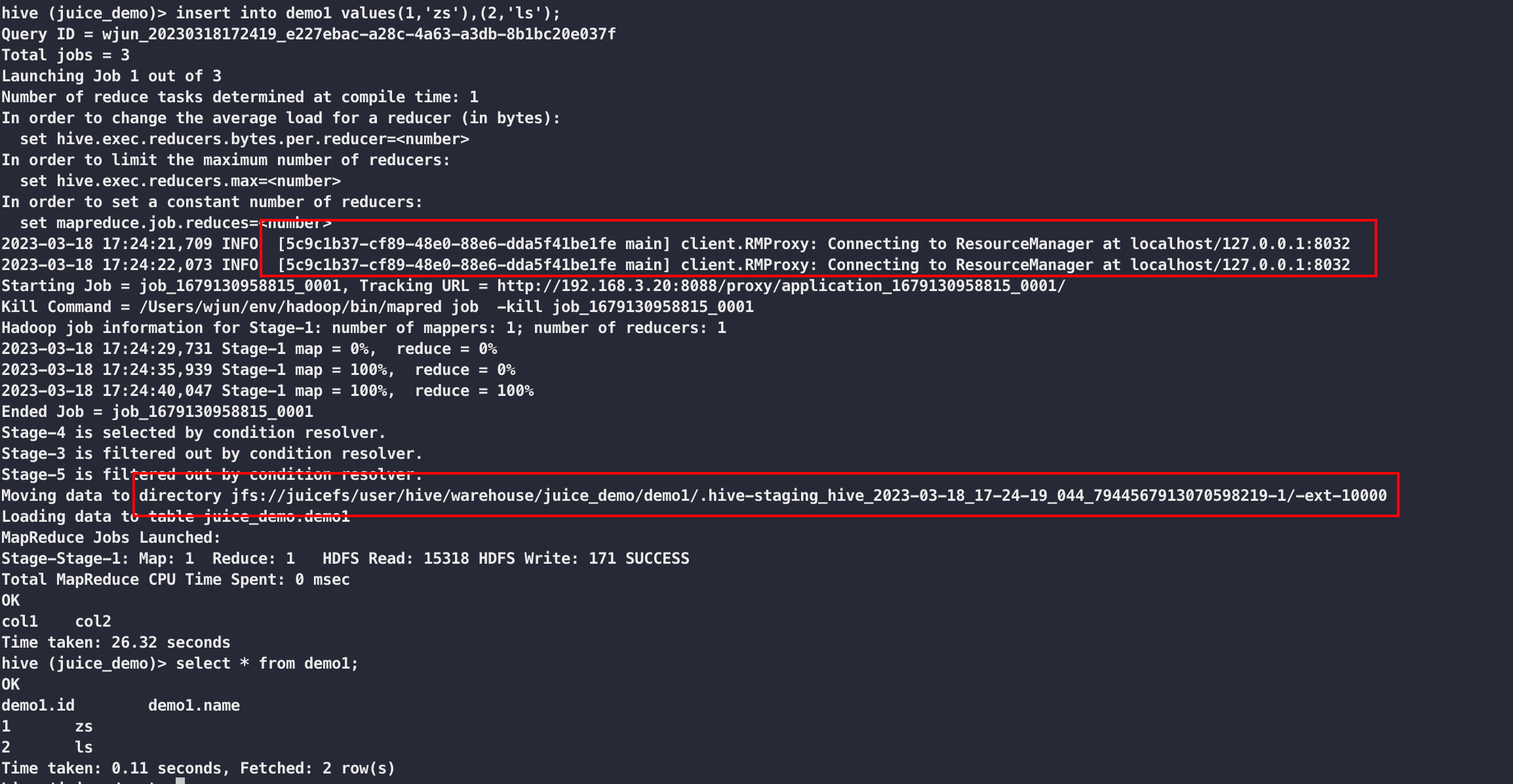
2.5 spark
将 juicefs-hadoop-1.0.3.jar 放到 spark 的 jars 下,这里建议将 juicefs-hadoop-1.0.3.jar 统一放到一个路径后续所有的组件通过符号链接进行调用
ln -sf ../../hadoop/share/hadoop/common/juicefs-hadoop-1.0.3.jar juicefs-hadoop-1.0.3.jar
spark sql 连接 hive metastore 计算上面的 demo1 表,可 hive 一样的操作
评论区