


在实际生产中,往往试图去优化一些线上的 SQL,但是伴随着大量数据的生产环境不可能做一个小小的优化有去线上执行,甚至多次执行去观察到底优化有没有成功;这种做法往往是不可取的。因此 Hive 提供了一个执行计划的功能帮助我们查看优化前后的 SQL 到底是怎么执行的来判断本次优化是否成功。
本文将依托 join 操作来介绍如何查看执行计划,同时解读 mapjoin 的执行计划并提供一个 mapjoin 失效的案例
如何查看执行计划
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query-sql
通常 explain sql 的信息就已经够用了,拓展、依赖、权限相关的根据具体情况来看
hive (advance)> explain select * from smalltable;
OK
Explain
-- 阶段的依赖关系
STAGE DEPENDENCIES:
Stage-0 is a root stage
-- 具体每个阶段的执行计划
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
TableScan
alias: smalltable
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint), t (type: bigint), uid (type: string), keyword (type: string), url_rank (type: int), click_num (type: int), click_url (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
ListSink
Time taken: 0.139 seconds, Fetched: 17 row(s)
可以看出当前执行计划只有一个阶段,该阶段的执行计划是一个 Fetch 抓取操作;limit -1 表示没有限制;之后是执行树是一个 TableScan 表扫描,展示了表名以及关于表的一些统计信息;接下来就是查询操作,查了哪些字段、输出的字段名是什么以及一些统计信息。这就是简单的 select * 操作的执行计划
mapjoin 执行计划
众所周知 mapjoin 是 hive 优化的重要一环,可以有效的解决因 join 操作带来的数据倾斜,同时也可以提高 sql 的执行效率;通常在大表 join 小表的时候将小表缓存到内存,再在 map 端读取大表并将小表广播到大表的每个 mapTask 中进行 join 操作,因此避免了 reduce 也就避免了数据倾斜,那 mapjoin 的执行计划是什么样子的呢?
首先开启 mapjoin(默认就是开启的),设置小表的阈值(默认 25M)
set hive.auto.convert.join=true;
set hive.mapjoin.smalltable.filesize=25000000;
事先准备两张表,一个大表、一个小表
hive (advance)> explain select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
> from smalltable s
> join bigtable b
> on s.id = b.id;
OK
Explain
STAGE DEPENDENCIES:
Stage-4 is a root stage , consists of Stage-5, Stage-1
Stage-5 has a backup stage: Stage-1
Stage-3 depends on stages: Stage-5
Stage-1
Stage-0 depends on stages: Stage-3, Stage-1
STAGE PLANS:
Stage: Stage-4
Conditional Operator
Stage: Stage-5
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_0:s
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_0:s
TableScan
alias: s
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: b
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint), t (type: bigint), uid (type: string), keyword (type: string), url_rank (type: int), click_num (type: int), click_url (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint), _col2 (type: bigint), _col3 (type: string), _col4 (type: string), _col5 (type: int), _col6 (type: int), _col7 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: s
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
TableScan
alias: b
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint), t (type: bigint), uid (type: string), keyword (type: string), url_rank (type: int), click_num (type: int), click_url (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint), _col2 (type: string), _col3 (type: string), _col4 (type: int), _col5 (type: int), _col6 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint), _col2 (type: bigint), _col3 (type: string), _col4 (type: string), _col5 (type: int), _col6 (type: int), _col7 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.313 seconds, Fetched: 131 row(s)
这个时候发现:哇!好多不想看了,不要着急每一个复杂的 SQL 都是一个个简单的 SQL 组合起来的,因此执行计划也是这样的。
首先看阶段的依赖关系
STAGE DEPENDENCIES:
Stage-4 is a root stage , consists of Stage-5, Stage-1
Stage-5 has a backup stage: Stage-1
Stage-3 depends on stages: Stage-5
Stage-1
Stage-0 depends on stages: Stage-3, Stage-1
解释:
阶段 4 是根阶段,包含阶段 5 和阶段 1;
阶段 5 有一个备份阶段是阶段 1,也就是说阶段 1 是阶段 5 的备份
阶段 3 依赖阶段 5,也就是说阶段 5 执行完是阶段 3
阶段 1 是独立的,是阶段 5 的备份
阶段 0 依赖阶段 3 和阶段 1
最终该执行计划其实有两条线,主线是阶段 4 -> 阶段 5 -> 阶段 3 -> 阶段 0,备份线是阶段 4 -> 阶段 1 -> 阶段 0;为什么会有备份线呢?后面说 😉😉
先看主线阶段 4 -> 阶段 5 -> 阶段 3 -> 阶段 0
阶段 4
Stage: Stage-4
Conditional Operator
就是一个条件运算符,或许是声明一下 join 的连接方式吧
阶段 5
Stage: Stage-5
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_0:s
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_0:s
TableScan
alias: s
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
阶段五是一个本地的 mapreduce 任务,首先是一个抓取操作,扫描的表是 s,即 smalltable 表,以 HashTable Sink 的形式输出,可以理解为把 smalltable 以 HashTable 的形式加载到内存,key 是 _col0 也就是 id,因为 join 操作只用到 smalltable 的 id,输出的都是 bigtable 的字段。
阶段 3
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: b
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint), t (type: bigint), uid (type: string), keyword (type: string), url_rank (type: int), click_num (type: int), click_url (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint), _col2 (type: bigint), _col3 (type: string), _col4 (type: string), _col5 (type: int), _col6 (type: int), _col7 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Execution mode: vectorized
Local Work:
Map Reduce Local Work
阶段三首先扫描了 b 表即 bigtable;同时 select 了 7 个字段;之后进行了 MapJoin 的操作,并将结果输出成一个临时表,没有压缩并展示了序列化类,输入输出格式;同时大表的执行模式是 vectorized 矢量查询,注意该过程是没有 reduce 阶段的。

阶段 0
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
简单的抓取操作输出
这就是主线的执行计划也是 mapjoin 的一个原理,下面看备用线阶段 4 -> 阶段 1 -> 阶段 0
阶段 1
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: s
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
TableScan
alias: b
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint), t (type: bigint), uid (type: string), keyword (type: string), url_rank (type: int), click_num (type: int), click_url (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint), _col2 (type: string), _col3 (type: string), _col4 (type: int), _col5 (type: int), _col6 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint), _col2 (type: bigint), _col3 (type: string), _col4 (type: string), _col5 (type: int), _col6 (type: int), _col7 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
阶段一很长,但无非做了两件事,首先该阶段是一个 mapreduce 任务且有 reduce 阶段;map 阶段分别扫描了两张表 s,b 即:smalltable 和 bigtable;reduce 阶段对两张表做了 join 操作,后面的操作和上面一样;这其实就是普通的 join 操作,map 端读取数据,reduce 端处理。

看完就好理解 mapjoin 的执行计划了,备用线路防止 mapjoin 失效,即:如果 mapjoin 的条件不成立就进行普通的 join 操作。
mapjoin 失效
上面的执行计划看出,mapjoin 执行过程中会有一个普通的 join 来兜底,如果 mapjoin 失效走普通 join 保证任务不失败,那 mapjoin 何时失效呢 ?当然不是我把 mapjoin 关了,比如这样
-- 不是这样做的
set hive.auto.convert.join=false;
我们依然保持 mapjoin 的开启,即和上面操作的配置不变,仅改动一丢丢的 SQL
explain select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
left join bigtable b
on s.id = b.id;
将内连接改为左连接,同样满足传说中的那句话,小表在前、大表在后,查看执行计划
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: s
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 1 Data size: 130150840 Basic stats: COMPLETE Column stats: NONE
TableScan
alias: b
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: bigint), t (type: bigint), uid (type: string), keyword (type: string), url_rank (type: int), click_num (type: int), click_url (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 1 Data size: 1291573248 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint), _col2 (type: string), _col3 (type: string), _col4 (type: int), _col5 (type: int), _col6 (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join 0 to 1
keys:
0 _col0 (type: bigint)
1 _col0 (type: bigint)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint), _col2 (type: bigint), _col3 (type: string), _col4 (type: string), _col5 (type: int), _col6 (type: int), _col7 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 143165927 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 1.145 seconds, Fetched: 60 row(s)
啊这,发现做的是普通的join,这时候 mapjoin 就失效了,这是为什么呢?看下面图解
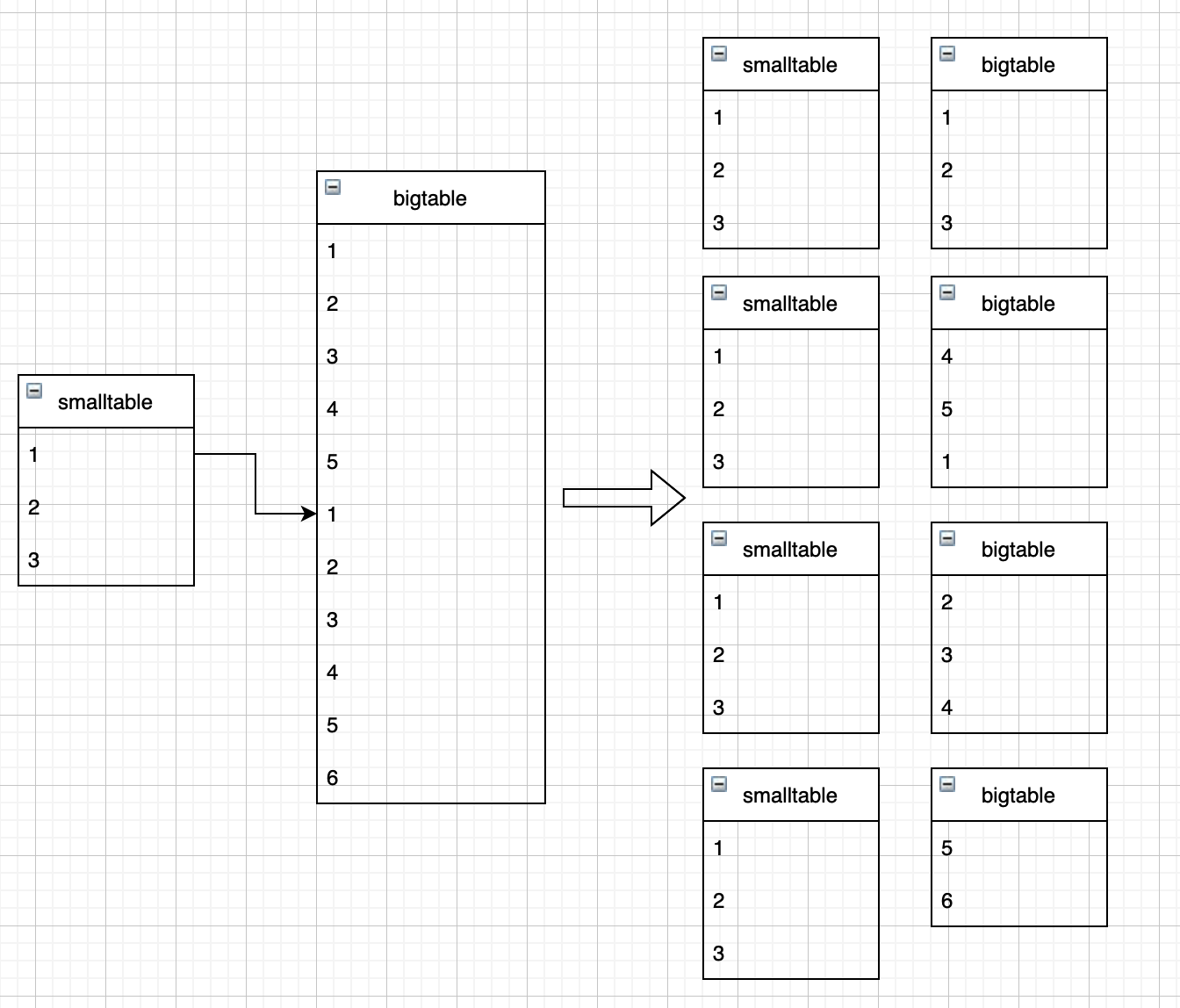
按照 mapjoin 的思路,小表广播到大表的每一个 maptask 中进行左连接,这时候问题就出现了,因为小表是主表,如果小表中的数据没有关联到大表,那这个字段该如何处理?补 null,不行,因为不能保证这个字段在另一个 maptask 中不出现;剔除也不可取因为这是左连接。因此左连接时 mapjoin 会失效。
评论区