


一、HBase简介
1.1HBase定义
HBase是一种分布式、可拓展、支持海量数据存储的非关系型数据库。来源于谷歌的三驾马车之一的BigTable,负责海量数据的存储。对于数据量不大的时候优势不明显,使用HBase不划算,在运行期间一直在“分分合合”的操作耗费资源,当数据量上来时,可以做到几十亿条数据秒级响应。针对HDFS并不支持随机写操作,但HBase是基于HDFS可以在HDFS上实现随机写操作,实现HDFS上的增删改查,其实现十分简单HBase把数据下载下来修改然后重新上传,但由于HBase拥有许多组件对其进行极致的优化,使之让这种效率低的方法速度变得极快,利用资源换取了时间,目前是Apache维护的顶级项目。
1.2 HBase 数据模型
逻辑上,HBase的数据模型关系数据库同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K - V)来看,HBase更像是一个multi-dimensional map
1.2.1 HBase逻辑结构
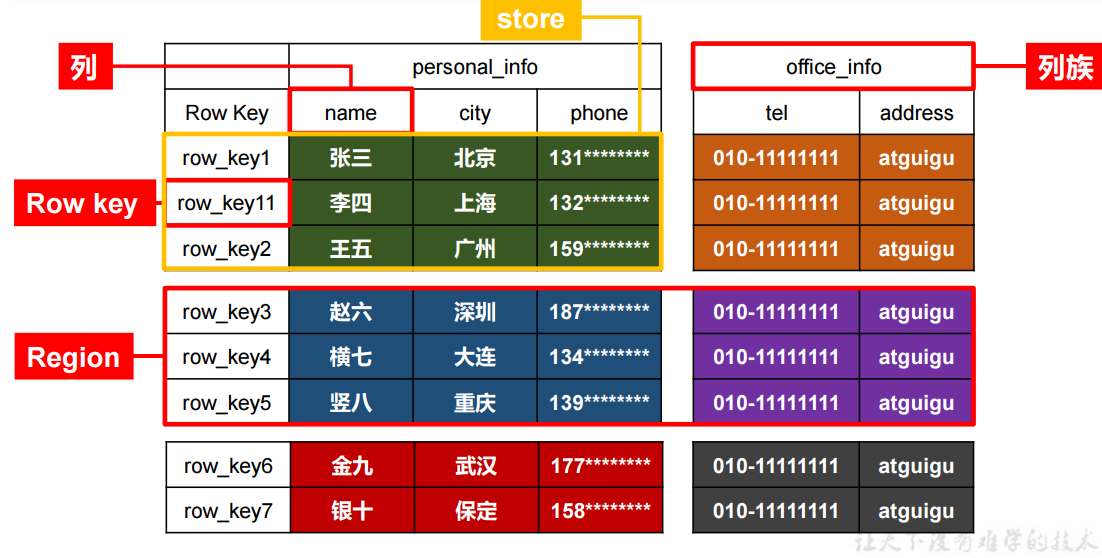
- Row Key:行键,系统自带,在一张表中必须是唯一的,类似MySQL的主键【字典序】
- 列:类似MySQL的字段
- 列族:将很多列分出来不同的列族,影响最终的存储,不同的列族存储在不同的文件夹中
- Region:横向切片
- store:存储,真正存储在HDFS的数据
其中region/store借鉴MySQL的高表宽表的存储策略
1.2.2 再谈store
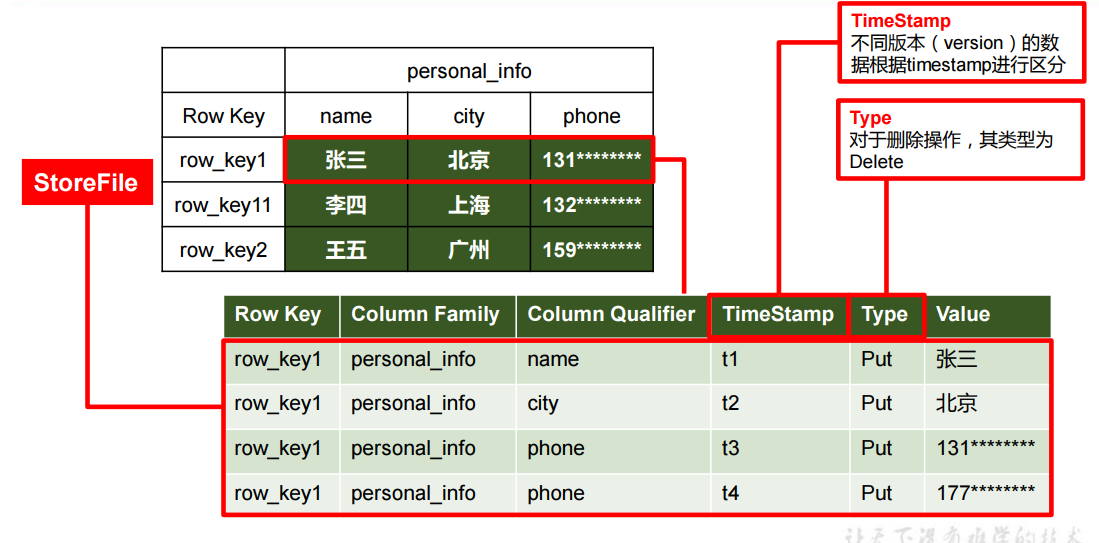
在HBsae上每一条数据都有很多信息,如row_key1这列真正存储了行键、列族、列名、时间戳、操作类型和数据,其中HBase实现HDFS的随机写操作完全靠这个时间戳来完成即TimeStamp(记录当前操作时间),因此后面进行API操作时一定要将Linux时间和Windows时间调成一致,否则会发生各种诡异的事情,如:删除数据删不掉,插入数据看不见等等... 注意到t3和t4时间戳行,发现它们的列名都是phone且操作类型都是Put,这就是HBase的随机写操作(修改phone数据操作),只要t4>t3即可实现修改(覆盖),若进行删除HBase会将操作类型设为Delete,若Delete的时间戳大于Put的时间戳则不返回数据,造成了一种删除的错觉,其实当时的数据并没有被删除(在分表和表过程中删除),否则HBase的速度不会这么快。
1.2.3 数据模型
1)Name Space
命名空间,类似MySQL库的概念,每个命名空间下有很多表,其中HBase自带两个命名空间分别是hbase和default,其中hbase存放系统内置的表,default是用户默认使用的命名空间。
2)Region
表的切片,当达到高表时会有很多切片对于HBase来说10G一切,当然我们也可以手动切。HBase建表时只需要指定到列族即可,字段可以动态增加,因为HBase是以键值对的形式为一个数据进行存储,他的列(字段)相当于数据里的键。
3)Row
每行数据都有一个RowKey和多个列组成,数据是按照RowKey的字典顺序存储,并且查询数据时只能根据RowKey进行检索。
4)Column
每个列都是由列族和列限定符(字段)进行鉴定
5)TimeStamp
用于标识数据的不同版本,如果不指定时间戳系统会自动天剑当前时间
6)Cell
唯一确定的单元{rowkey,column Family:column Qualifier,time Stamp}。cell中的数据没有类型,底层都是字节数组形式存储。
总结:第一个NameSpace命名空间,类似数据库;第二个Region和表有关系,从大的结构往小看的,起初数据量小的时候,这个表就是一个Region;表里面在HBase叫列族,列族下是列,列下面是数据,但这个数据是你看到的版本最大的数据,实际上这个单元格底下可能隐藏着其它数据,只有row key加列族加列加时间戳才能唯一确定这个数据,不加时间戳可能会是一系列数据,如果我们能唯一确定一个数据即加了时间戳那么这个数据就是一个Cell,叫单元格或者细胞,在这个Cell里数据没有复杂的数据类型都是字节数组。
1.3 HBase基本框架
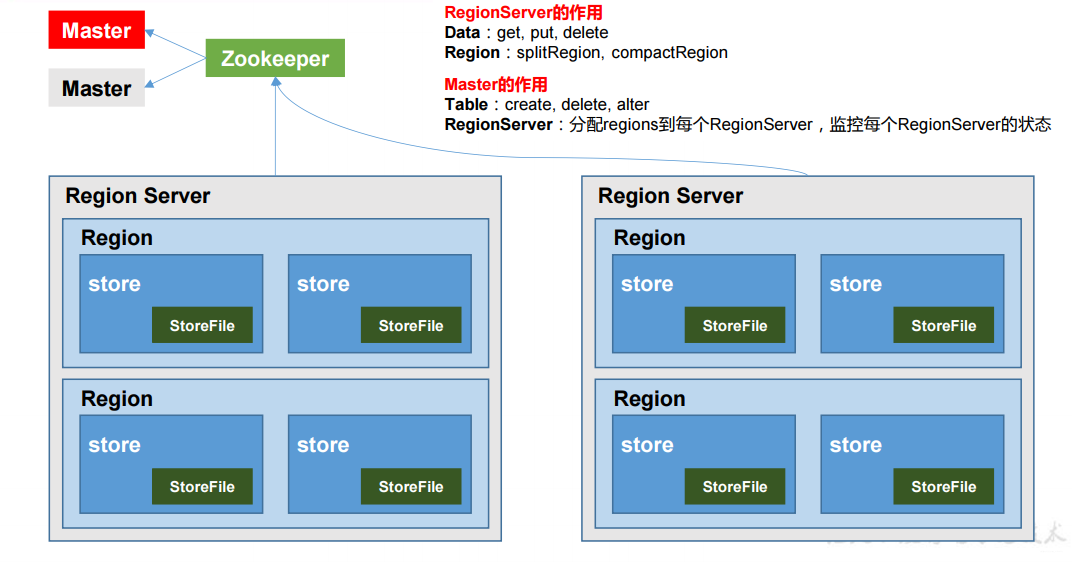
1)Region Server【DML】
Region的管理者,管理数据的增删改查,和Region的分表(splitRegion)和表(compactRegion)
2)Master【DDL】
RegionServer的管理者,管理表的增删改查,监控每个RegionServer的状态,负载均衡和故障转移
3)Zookeeper
通过Zookeeper实现Master的高可用,RegionServer的监控、元数据入口以及集群的配置维护等
4)HDFS
为HBase提供最终的底层数据存储服务,提供HBase的高可用
二、HBase快速入门
2.1 HBase集群搭建
2.1.1 Zookeeper正常部署并启动
HBase的Master需要Zookeeper提供高可用的支持,通过群起脚本快速启动
#!/bin/bash
pcount=$#
if [ $pcount == 0 ]
then
echo "no args"
exit
fi
# 获取参数
p1=$1
if [ $p1 == "start" ]
then
for i in root@master root@slave01 root@slave02
do
echo "=============== $i ==============="
ssh $i "source /etc/profile && /usr/local/soft/zookeeper-3.4.10/bin/zkServer.sh start"
done
exit
fi
if [ $p1 == "stop" ]
then
for i in root@master root@slave01 root@slave02
do
echo "=============== $i ==============="
ssh $i '/usr/local/soft/zookeeper-3.4.10/bin/zkServer.sh stop'
done
exit
fi
if [ $p1 == "status" ]
then
for i in root@master root@slave01 root@slave02
do
echo "=============== $i ==============="
ssh $i "source /etc/profile && /usr/local/soft/zookeeper-3.4.10/bin/zkServer.sh status"
done
exit
fi
2.1.2 Hadoop正常部署并启动
HBase需要HDFS提供存储服务,通过配置slaves文件可实现群起Hadoop集群(启动hdfs即可)
start-dfs.sh
2.1.3 HBase正常部署并启动
1. HBase解压
tar -zxvf hbase-2.2.5-bin.tar.gz
2. 修改配置文件
cd hbase-2.2.5/conf/
修改hbase-env.sh
# The java implementation to use. Java 1.8+ required.
export JAVA_HOME=/usr/local/soft/jdk1.8.0_144
# Tell HBase whether it should manage it's own instance of ZooKeeper or not.
export HBASE_MANAGES_ZK=false
写死JAVA_HOME,最新版[2020/6/25]的HBase要求jdk1.8+了,最后一定要修改你HBASE_MANAGES_ZK为false,HBase内置了一个Zookeeper默认使用它内置的版本,但会修改你本机的Zookeeper的myid导致原先的Zookeeper集群下次无法正常使用。
修改hbase-site.xml,内容如下
<configuration>
<!--
The following properties are set for running HBase as a single process on a
developer workstation. With this configuration, HBase is running in
"stand-alone" mode and without a distributed file system. In this mode, and
without further configuration, HBase and ZooKeeper data are stored on the
local filesystem, in a path under the value configured for `hbase.tmp.dir`.
This value is overridden from its default value of `/tmp` because many
systems clean `/tmp` on a regular basis. Instead, it points to a path within
this HBase installation directory.
Running against the `LocalFileSystem`, as opposed to a distributed
filesystem, runs the risk of data integrity issues and data loss. Normally
HBase will refuse to run in such an environment. Setting
`hbase.unsafe.stream.capability.enforce` to `false` overrides this behavior,
permitting operation. This configuration is for the developer workstation
only and __should not be used in production!__
See also https://hbase.apache.org/book.html#standalone_dist
-->
<!-- 是否搭建分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 临时文件目录 -->
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/soft/hbase-2.2.5/tmp/</value>
</property>
<!-- 暂时不知道干嘛的,上面的注释说让你设置成false-->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 写的是hdfs的namenode节点,相当于将HBase存储到hdfs下的/HBase -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/HBase</value>
</property>
<!-- 默认端口号,可写可不写 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- 你的Zookeeper节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave01,slave02</value>
</property>
<!-- 你的Zookeeper工作目录,配置文件里的 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/soft/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
配置regionservers
master
slave01
slave02
注意不要写空格,和群起hdfs一样的要求
==软连接hadoop配置文件到hbase==
ln -s /usr/local/soft/hadoop-2.7.2/etc/hadoop/core-site.xml /usr/local/soft/hbase-2.2.5/conf/core-site.xml
ln -s /usr/local/soft/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /usr/local/soft/hbase-2.2.5/conf/hdfs-site.xml
最后一步同步分发到其他节点,下面是我的分发脚本xsync.sh
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if [ $pcount == 0 ]
then
echo no args
exit
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
rsync -rvl $pdir/$fname $user@slave01:$pdir
rsync -rvl $pdir/$fname $user@slave02:$pdir
执行分发
xsync.sh /usr/local/soft/hbase-2.2.5/
上面说过在HBase中时间戳很重要,是一切操作的基础,因此集群之间的时间必须通过,默认时间差30秒,因此在集群启动之间必须同步时间,否则无法启动报ClockOutOfSyncException异常如何同步集群时间,不推荐修改默认时间差
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>
3. 启动HBase
start-hbase.sh //启动HBase
stop-hbase.sh //关闭HBase
下面这种情况是由于Hadoop的slf4j-log4j12-1.7.10.jar与HBase的slf4j-log4j12-1.7.25.jar版本不一样,但是不会影响正常使用,网上的解决方法删除其中一个jar包,亲测删除Hadoop的jar包后HBase确实不报异常了,Hadoop开始报异常(┬_┬),最好的方法是更换Hadoop版本,在搭建集群的时候就提前规划好(没有强迫症的随意)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/soft/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/soft/hbase-2.2.5/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2.1.4 查看集群状态
1. 方式一 jps
为了方便查看各个集群的java进程,我编写一个简单的脚本call.sh
#!/bin/bash
pcount=$#
if [ $pcount == 0 ]
then
echo "no args"
exit
fi
args=$1
if [ $args == "jps" ]
then
for i in master slave01 slave02
do
echo "================ $i ================"
ssh $i /usr/local/soft/jdk1.8.0_144/bin/jps
done
fi
[root@master shell]# call.sh jps
================ master ================
11521 DataNode
11254 QuorumPeerMain
12070 HRegionServer
11928 HMaster
12285 Jps
11407 NameNode
================ slave01 ================
8018 DataNode
7943 QuorumPeerMain
8107 SecondaryNameNode
8236 HRegionServer
8351 Jps
================ slave02 ================
6344 QuorumPeerMain
6665 Jps
6540 HRegionServer
6413 DataNode
1. 方式二 web查看
端口号 master:16010,master是你的HBase的Master节点ip(可在windows配置一下主机名映射)
2.2 HBase Shell 操作
写在前面,HBase的Shell命令只可能在学习,熟悉命令的时候使用,真正的项目开发还得用API
2.2.1 基本操作
1. 进入HBase客户端
habse shell
2. 查看帮助命令
help
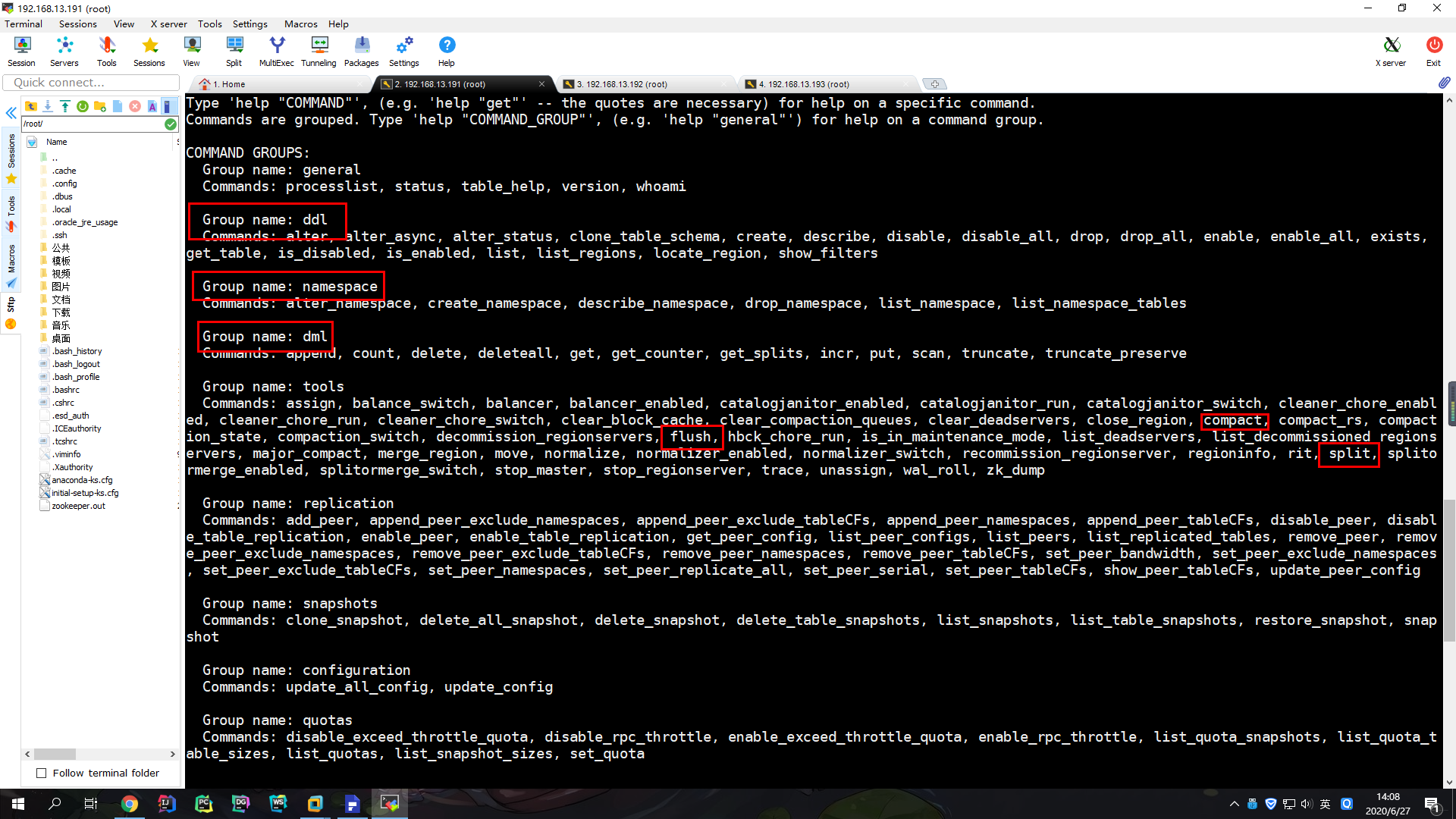
看到了熟悉的DDL、DML和namespace,以及前面说的compact、split和flush等
3. 查看所有的用户表
list
hbase(main):010:0> list
TABLE
0 row(s)
Took 0.0087 seconds
=> []
当前namespace下的表为空
注意:命令结束不要使用; ,命令结束不要使用; ,命令结束不要使用;
误操作可输入两次'退回shell命令行,不要ctrl c来回登录很麻烦
hbase(main):011:0> list;
hbase(main):012:0* '
hbase(main):013:0' '
TABLE
0 row(s)
Took 0.0093 seconds
=> "\n"
hbase(main):014:0>
2.2.2 DDL
1.创建一个表
create 'student','info'
基本语法:create '表名','列族名'
注意事项:
- 表名,列族名要用引号括起来(不区分单双引号)
- 一定要写列族名
2.查看表结构
describe 'student'
注意:hbase的shell支持tab提示

这个VERSIONS => '1'可以改,上面解释cell说过需要加时间戳才能唯一确定一个数据,这个VERSIONS决定这个单元格最终能存几个数据
3.修改表结构
常见的是改VERSIONS的信息
alter 'student',{NAME=>'info1',VERSIONS=>3}
将VERSIONS改为3,这样在分表和表时一个单元格会保留三份时间戳最大的数据
4.删除表
hbase(main):020:0> drop 'student'
ERROR: Table student is enabled. Disable it first.
For usage try 'help "drop"'
Took 0.0211 seconds
这里它报错了,说这个表是可用的,删除前让这个表下线,使用disable
disable 'student'
drop 'student'
5.关于命名空间的命令
和DDL命令几乎一样,如:
查看命名空间
list_namespace
创建一个命名空间
create_namespace 'bigdata'
将表创建到指定的命名空间,当我们不指定命名空间时,系统默认创建到default中,且使用表时不加命名空间系统会从default中查找
create 'bigdata:student','info'
list查看一下
hbase(main):025:0> list
TABLE
bigdata:student
student
2 row(s)
Took 0.0092 seconds
=> ["bigdata:student", "student"]
可能有人就说了,我怎么知道是创建在bigdata的命名空间呢,或许是你的表名就是bigdata:student呢?好吧,我们可以通过web来查看一下

最后是删除命名空间
hbase(main):026:0> drop_namespace 'bigdata'
ERROR: org.apache.hadoop.hbase.constraint.ConstraintException: Only empty namespaces can be removed. Namespace bigdata has 1 tables
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.prepareDelete(DeleteNamespaceProcedure.java:217)
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.executeFromState(DeleteNamespaceProcedure.java:78)
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.executeFromState(DeleteNamespaceProcedure.java:45)
at org.apache.hadoop.hbase.procedure2.StateMachineProcedure.execute(StateMachineProcedure.java:194)
at org.apache.hadoop.hbase.procedure2.Procedure.doExecute(Procedure.java:962)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execProcedure(ProcedureExecutor.java:1662)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.executeProcedure(ProcedureExecutor.java:1409)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.access$1100(ProcedureExecutor.java:78)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$WorkerThread.run(ProcedureExecutor.java:1979)
For usage try 'help "drop_namespace"'
Took 0.9124 seconds
发现它报错了,这个和MySQL一样,命名空间有表是不能被删除的,因此我们首先disable掉所有表,然后删除所有表,最后drop_namespace
2.2.3 DML
首先查看一下put的用法
hbase(main):003:0> help 'put'
Put a cell 'value' at specified table/row/column and optionally
timestamp coordinates. To put a cell value into table 'ns1:t1' or 't1'
at row 'r1' under column 'c1' marked with the time 'ts1', do:
hbase> put 'ns1:t1', 'r1', 'c1', 'value'
hbase> put 't1', 'r1', 'c1', 'value'
hbase> put 't1', 'r1', 'c1', 'value', ts1
hbase> put 't1', 'r1', 'c1', 'value', {ATTRIBUTES=>{'mykey'=>'myvalue'}}
hbase> put 't1', 'r1', 'c1', 'value', ts1, {ATTRIBUTES=>{'mykey'=>'myvalue'}}
hbase> put 't1', 'r1', 'c1', 'value', ts1, {VISIBILITY=>'PRIVATE|SECRET'}
The same commands also can be run on a table reference. Suppose you had a reference
t to table 't1', the corresponding command would be:
hbase> t.put 'r1', 'c1', 'value', ts1, {ATTRIBUTES=>{'mykey'=>'myvalue'}}
解释:
ns1:t1指定一张表,不写ns1默认defaultr1是Row Keyc1是列族,一般这个时候会加入列,如:info:namevalue插入的数据
put 'student','1001','info1:name','张三'
查看表两种方法scan和get,同理首先help 'scan'
Some examples:
hbase> scan 'hbase:meta'
hbase> scan 'hbase:meta', {COLUMNS => 'info:regioninfo'}
hbase> scan 'ns1:t1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1303668804000, 1303668904000]}
hbase> scan 't1', {REVERSED => true}
hbase> scan 't1', {ALL_METRICS => true}
hbase> scan 't1', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']}
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => "
(QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"}
hbase> scan 't1', {FILTER =>
org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}
hbase> scan 't1', {ISOLATION_LEVEL => 'READ_UNCOMMITTED'}
hbase> scan 't1', {MAX_RESULT_SIZE => 123456}
最简单的直接跟表名,当然可以添加过滤器过滤条件(在命令行写怕是疯了)
hbase(main):008:0> scan 'student'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1 row(s)
Took 0.0844 seconds
数据会自动增加一个时间戳,请忽略value😄(远程连接工具编码格式问题,影响不大)
第二种方法get
hbase> get 'ns1:t1', 'r1'
hbase> get 't1', 'r1'
hbase> get 't1', 'r1', {TIMERANGE => [ts1, ts2]}
hbase> get 't1', 'r1', {COLUMN => 'c1'}
hbase> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2], VERSIONS => 4}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1, VERSIONS => 4}
hbase> get 't1', 'r1', {FILTER => "ValueFilter(=, 'binary:abc')"}
hbase> get 't1', 'r1', 'c1'
hbase> get 't1', 'r1', 'c1', 'c2'
hbase> get 't1', 'r1', ['c1', 'c2']
hbase> get 't1', 'r1', {COLUMN => 'c1', ATTRIBUTES => {'mykey'=>'myvalue'}}
hbase> get 't1', 'r1', {COLUMN => 'c1', AUTHORIZATIONS => ['PRIVATE','SECRET']}
hbase> get 't1', 'r1', {CONSISTENCY => 'TIMELINE'}
hbase> get 't1', 'r1', {CONSISTENCY => 'TIMELINE', REGION_REPLICA_ID => 1}
hbase(main):010:0> get 'student','1001'
COLUMN CELL
info1:name timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1 row(s)
Took 0.0641 seconds
总结:get最大可以指定到row key,最小可以指定列
细节一波,首先添加一些数据
hbase(main):011:0> put 'student','1001','info1:sex','nan'
Took 0.0130 seconds
hbase(main):012:0> put 'student','1001','info2:addr','anhui'
Took 0.0208 seconds
hbase(main):013:0> put 'student','1002','info1:name','lisi'
Took 0.0074 seconds
hbase(main):014:0> put 'student','1002','info1:sex','nv'
Took 0.0082 seconds
hbase(main):015:0> put 'student','1003','info1:name','wangwu'
Took 0.0057 seconds
hbase(main):016:0> scan 'student'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1593242822073, value=nan
1001 column=info2:addr, timestamp=1593242848437, value=anhui
1002 column=info1:name, timestamp=1593242882626, value=lisi
1002 column=info1:sex, timestamp=1593242890679, value=nv
1003 column=info1:name, timestamp=1593242899920, value=wangwu
3 row(s)
Took 0.0123 seconds
- 列名可以在添加数据的时候动态增加
- 列名只和row key有关,虽然scan出很多行,但最终它就是3条数据
看下面的语句
hbase(main):018:0> scan 'student',{STARTROW=>'1001',STOPROW=>'1003'}
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1593242822073, value=nan
1001 column=info2:addr, timestamp=1593242848437, value=anhui
1002 column=info1:name, timestamp=1593242882626, value=lisi
1002 column=info1:sex, timestamp=1593242890679, value=nv
2 row(s)
Took 0.0401 seconds
它是左闭右开,当然STOPROW不写或者STARTROW不写结果应该能猜出来,参考java的subString
看下面的语句
put 'student','10010','info1:name','zhaoliu'
这时候我再scan会返回什么,2秒钟考虑🤔
hbase(main):020:0> scan 'student'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1593242822073, value=nan
1001 column=info2:addr, timestamp=1593242848437, value=anhui
10010 column=info1:name, timestamp=1593243313017, value=zhaoliu
1002 column=info1:name, timestamp=1593242882626, value=lisi
1002 column=info1:sex, timestamp=1593242890679, value=nv
1003 column=info1:name, timestamp=1593242899920, value=wangwu
4 row(s)
Took 0.0162 seconds
猜对了吗,Row Key是按字典序进行排序,和插入顺序无关
这个时候工位旁边的小伙伴问了我一句,HBase的数据到底是怎么存的,存在哪里?
还记得当时的配置文件
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/HBase</value>
</property>
没错存在HDFS的/HBase
继续追,看到了什么,没错就是namespace
再追一次你就能看到表了(不截图了),不要放弃继续追
看着背影确实是个美女,走进一看懵了吧,两个隐藏文件夹,还有一个不知道是什么的文件夹,不要着急,如果我告诉你它是一个Region呢?

是不是一模一样?那就继续追吧
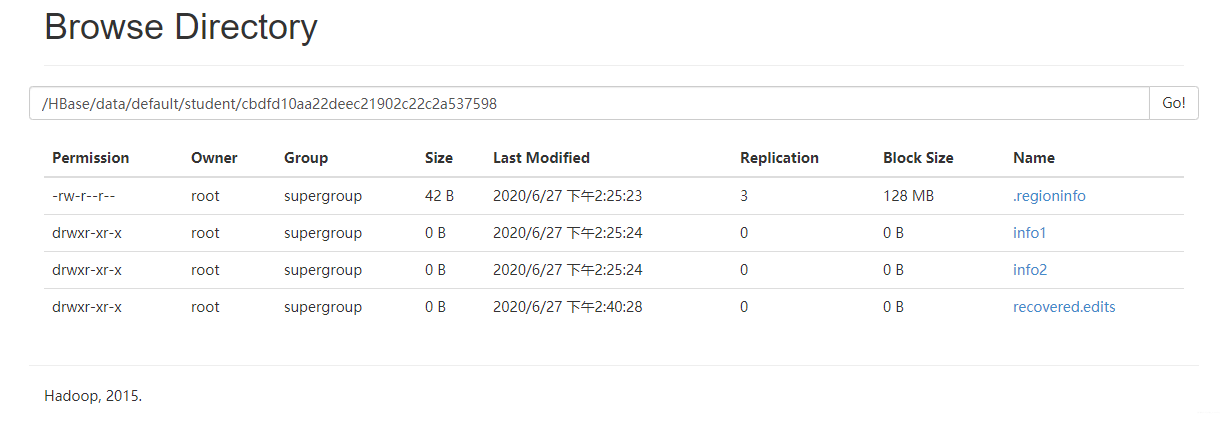
看到了什么,没错你看到列族了,如果你是第一次使用HBase,刚创建的表,添加了屈指可数的数据,那我劝你就追到这吧😄,因为里面是空的...没错因为此时的数据还在内存中,没有到刷写(flush)的阶段。(你可以等一个小时自动刷,当然手动刷也是支持的)
现在插播改数据操作
前面说过改数据也是put只要我的时间戳比原来的大就能实现覆盖,注意是覆盖不是删除原来的数据哟
put 'student','1002','info1:name','lisi666'
hbase(main):023:0> scan 'student'
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1593242822073, value=nan
1001 column=info2:addr, timestamp=1593242848437, value=anhui
10010 column=info1:name, timestamp=1593243313017, value=zhaoliu
1002 column=info1:name, timestamp=1593244813675, value=lisi666
1002 column=info1:sex, timestamp=1593242890679, value=nv
1003 column=info1:name, timestamp=1593242899920, value=wangwu
4 row(s)
Took 0.0148 seconds
下面我来证明一下,原来的数据还在内存中
hbase(main):025:0> scan 'student',{RAW=>true,VERSIONS=>10}
ROW COLUMN+CELL
1001 column=info1:name, timestamp=1593241775973, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:name, timestamp=1593241639593, value=\xE5\xBC\xA0\xE4\xB8\x89
1001 column=info1:sex, timestamp=1593242822073, value=nan
1001 column=info2:addr, timestamp=1593242848437, value=anhui
10010 column=info1:name, timestamp=1593243313017, value=zhaoliu
1002 column=info1:name, timestamp=1593244813675, value=lisi666
1002 column=info1:name, timestamp=1593242882626, value=lisi
1002 column=info1:sex, timestamp=1593242890679, value=nv
1003 column=info1:name, timestamp=1593242899920, value=wangwu
4 row(s)
Took 0.0177 seconds
上面的命令就是查看10个版本以内的所有数据,现在相信你的数据并没有被立刻删除,只是给你返回最大的时间戳数据,让你以为我把你数据删了
如果你还是没有明白其中的道理,那再来一个例子
首先get一波lisi666,记住它的时间戳
hbase(main):030:0> get 'student','1002','info1:name'
COLUMN CELL
info1:name timestamp=1593245367468, value=lisi666
1 row(s)
Took 0.0155 seconds
上面看到的put例子可以指定时间戳,那我们时间戳修改到比lisi666小一丢丢看看
put 'student','1002','info1:name','lisi666777',1593245367467
我们再get一波
hbase(main):033:0> get 'student','1002','info1:name'
COLUMN CELL
info1:name timestamp=1593245367468, value=lisi666
1 row(s)
Took 0.0343 seconds
发现数据并没有被修改,那么lisi666777到底有没有被插入进去呢?
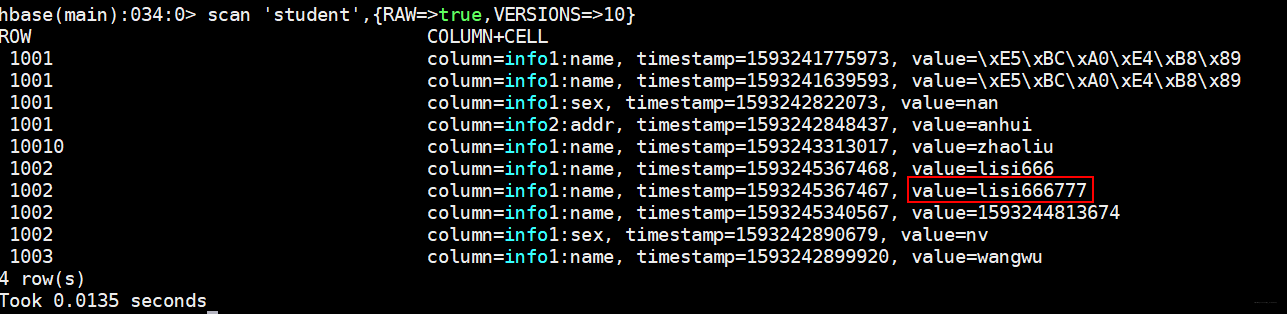
现在明白HBase是怎么操作了的吧!
最后一个DDL——删除操作
写在前面删除操作delete,我觉得HBase的程序员在封装API到Shell时抽风了,导致Shell中的delete设计很不合理
老规矩先查help
hbase(main):041:0> help 'delete'
Put a delete cell value at specified table/row/column and optionally
timestamp coordinates. Deletes must match the deleted cell's
coordinates exactly. When scanning, a delete cell suppresses older
versions. To delete a cell from 't1' at row 'r1' under column 'c1'
marked with the time 'ts1', do:
hbase> delete 'ns1:t1', 'r1', 'c1', ts1
hbase> delete 't1', 'r1', 'c1', ts1
hbase> delete 't1', 'r1', 'c1', ts1, {VISIBILITY=>'PRIVATE|SECRET'}
The same command can also be run on a table reference. Suppose you had a reference
t to table 't1', the corresponding command would be:
hbase> t.delete 'r1', 'c1', ts1
hbase> t.delete 'r1', 'c1', ts1, {VISIBILITY=>'PRIVATE|SECRET'}
看到帮助文档delete至少要三个参数,居然还要我传一个时间戳...但实际使用过程中发现时间戳可以不用写
先把1001的名字删了(就是我写中文,然后不识别)
delete 'student','1001','info1:name'
hbase(main):046:0> scan 'student'
ROW COLUMN+CELL
1001 column=info1:sex, timestamp=1593242822073, value=nan
1001 column=info2:addr, timestamp=1593242848437, value=anhui
1002 column=info1:name, timestamp=1593245367468, value=lisi666
1002 column=info1:sex, timestamp=1593242890679, value=nv
1003 column=info1:name, timestamp=1593242899920, value=wangwu
3 row(s)
Took 0.0112 seconds
确实是删了,和put的时候考虑一样,这台数据是不是真的被删了,根据最开始说的逻辑,应该是没有被删除,只是删除的时间戳大于原先的。

证明HBase确实是这么做的,当查询时,发现type=Delete且时间戳最大,这个时候就不会返回value给你造成了被删除的错觉。刚才看到了删除操作也可以传一个时间戳,那我们在熟悉一下HBase这样的操作逻辑。
首先put一个值进去
put 'student','1001','info1:name','zhangsan'
这个时候肯定能get到
hbase(main):050:0> get 'student','1001'
COLUMN CELL
info1:name timestamp=1593253497595, value=zhangsan
info1:sex timestamp=1593242822073, value=nan
info2:addr timestamp=1593242848437, value=anhui
1 row(s)
Took 0.0139 seconds
现在我们传一个比当前put操作小一丢丢的时间戳
delete 'student','1001','info1:name',1593253497594
我们再查看一波
hbase(main):052:0> get 'student','1001'
COLUMN CELL
info1:name timestamp=1593253497595, value=zhangsan
info1:sex timestamp=1593242822073, value=nan
info2:addr timestamp=1593242848437, value=anhui
1 row(s)
Took 0.0151 seconds
结果证明并没有被删除。关于delete就说到这,下面来吐糟一波delete
我们delete一直是用的都是定位到列,那么我们可以定位到列族,直接删除列族可不可以呢
hbase(main):053:0> delete 'student','1001','info1'
Took 0.0119 seconds
hbase(main):054:0> get 'student','1001'
COLUMN CELL
info1:name timestamp=1593253497595, value=zhangsan
info1:sex timestamp=1593242822073, value=nan
info2:addr timestamp=1593242848437, value=anhui
1 row(s)
Took 0.0103 seconds
结果是没有删除成功😠这时候又有一个疑问我可以直接根据row key删除吗?
hbase(main):057:0> delete 'student','1001'
ERROR: wrong number of arguments (2 for 3)
For usage try 'help "delete"'
Took 0.0020 seconds
直接给我报错???好吧!果然shell就是给你玩一玩,到了API操作都是可以做到的。
在MySQL是不是有个truncat直接清空表,当然HBase也是有的
hbase(main):058:0> truncate 'student'
Truncating 'student' table (it may take a while):
Disabling table...
Truncating table...
Took 2.3316 seconds
这个命令设计的就很人性化,先把你表停了在清空数据。
2.3 浅谈VERSIONS
前面在修改表结构的时候说到过VERSIONS我们设置成了3,这样HBase给我们保留最大的个数为3,举个例子吧。
put 'student','1005','info1:name','zhangsan'
put 'student','1005','info1:name','lisi'
put 'student','1005','info1:name','wangwu'
put 'student','1005','info1:name','zhaoliu'
我么可以通过下面命令获取数据
hbase(main):018:0> get 'student','1005',{COLUMN=>'info1:name',VERSIONS=>4}
COLUMN CELL
info1:name timestamp=1593260002688, value=zhaoliu
info1:name timestamp=1593259997155, value=wangwu
info1:name timestamp=1593259766686, value=lisi
1 row(s)
Took 0.0493 seconds
发现了什么,get 'student','1005',{COLUMN=>'info1:name',VERSIONS=>4}设置成4不管用,真正看的是建表时设置的VERSIONS,此时student表的VERSIONS是3(默认为1),这就意味着保存数据的最大数是3,即使你存了很多份,最终只会给你保留最新的三个版本的数据,当然你只存一份就只能给你保存一份。
到这里HBase的Shell就结束了,下面将是HBase的原理部分
三、HBase进阶
3.1 架构原理
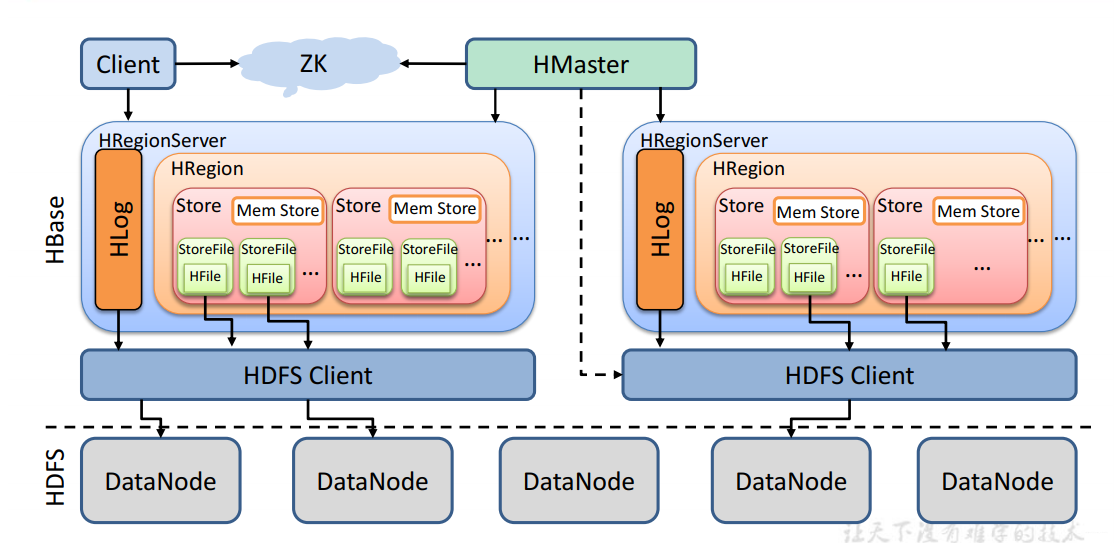
我们知道HBase依赖HDFS也依赖Zookeeper,那么首先出来的应该是HDFS,这是他底层的存储地,随便画几个DataNode无所谓,然后HBase还依赖Zookeeper,因此我们在启动HBase之前需要先启动它们。那接下轮到HBase启动了,HBase需要启动两大进程HMaster和HRegionServer,这个Master工作太累了,它需要把某些工作交给Zookeeper,后面在说具体都交给些什么任务。Master主要管理DDL相关的操作,操作表,操作命名空间,HRegionServer则是管理DML数据层面的操作,涉及数据的增删改查,同时Master也会管理HRegionServer,因为我的Region到底是给哪个HRegionServer维护由Master说的算,万一某个HRegionServer挂掉了,也需要Master重新分配给其它人来维护。
在谈HRegionServer之前还有一个HLog,这个又叫预写入日志Write-Ahead logfile在/HBase/wal文件夹中,相当于HDFS的edits文件,由于数据一开始并没有落盘存在内存中,若内存崩掉数据就会丢失,HLog会实时记录操作。接下来就是一堆HRegion,一个表对应一个或者多个HRegion,HRegion里面就是列族,也就是Store,它们的存储是隔离的,就像上面看的info1,info2,对于HBase来说它的列就是数据,在插入数据之前是没有列这个概念的,随着插入数据而存在。
下面来看看Mem Store,主要是做刷写操作(flush),上面我们做个一个操作证明HBase是按照Row Key的字典序排列的,因此数据首先存到Mem Store中进行排序,等待刷写时机将其写入磁盘中这就是HFile,因此将来会有很多个文件,当触发全局刷写条件(即HRegionServer的刷写条件)时可能有的Mem Store只有几k,就会产生很多小文件,这时候HBase就会做合并(compact)操作,当合并的文件过大又会做拆分(split)操作。
关于Store File和HFile的关系:HFile和.txt,.csv等同等级,是一种存储格式,Store File只是我们对刷写下来的文件的一种命名,这个文件以HFile格式存储,虽然Store File是HBase的一个组件,但它真正活跃在DataNode上,作用在磁盘上,然后就是一系列的HDFS读写操作。
那么Zookeeper到底为HMaster做了什么?如果是DDL那没话说客户端需要请求HMaster,若进行DML操作,客户端会请求Zookeeper然后直接到HRegionServer不经过HMaster,即使HMaster挂了,也可以进行读写操作,因此Zookeeper作为HBase接待客户端的第一管家,分担HBase的DML操作。
3.2 写流程
对于HBase来说,它的读比写慢
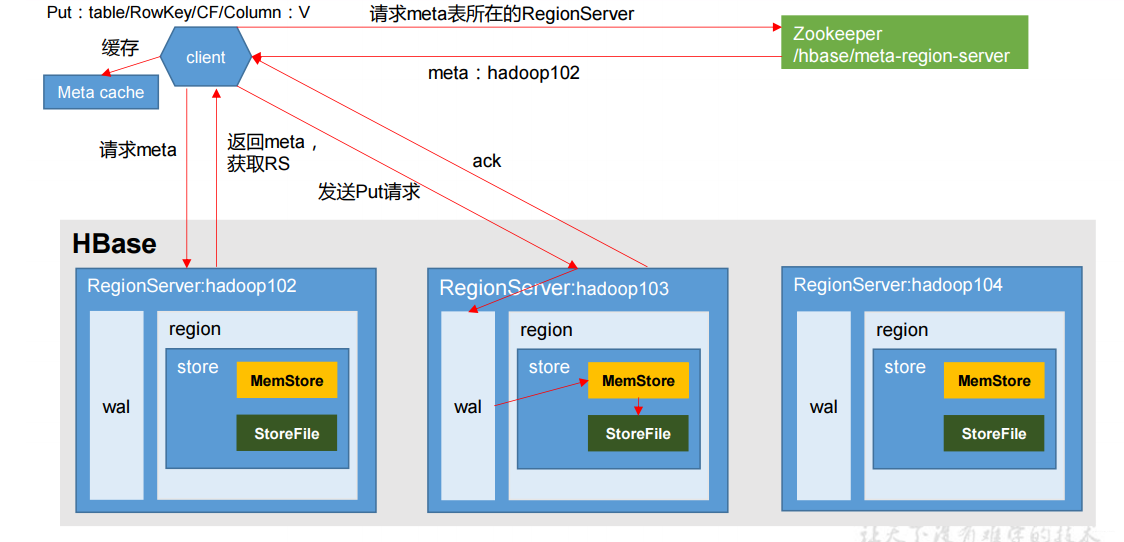
在写数据之前,首先肯定有一个客户端client,Zookeeper、HDFS、HBase得起来且wal、region、store都已经存在,这有这些前置条件成立才能进行写操作
假设我们需要put 'student','1001','info1:name','zhangsan',首先client会去Zookeeper拿meta表所在的RegionServer,那么meta表到底存了什么内容,其实它存了一些表的元数据,比如我们要put student那么我的学生表到底存在哪个HRegionServer上就记录在meta表上。
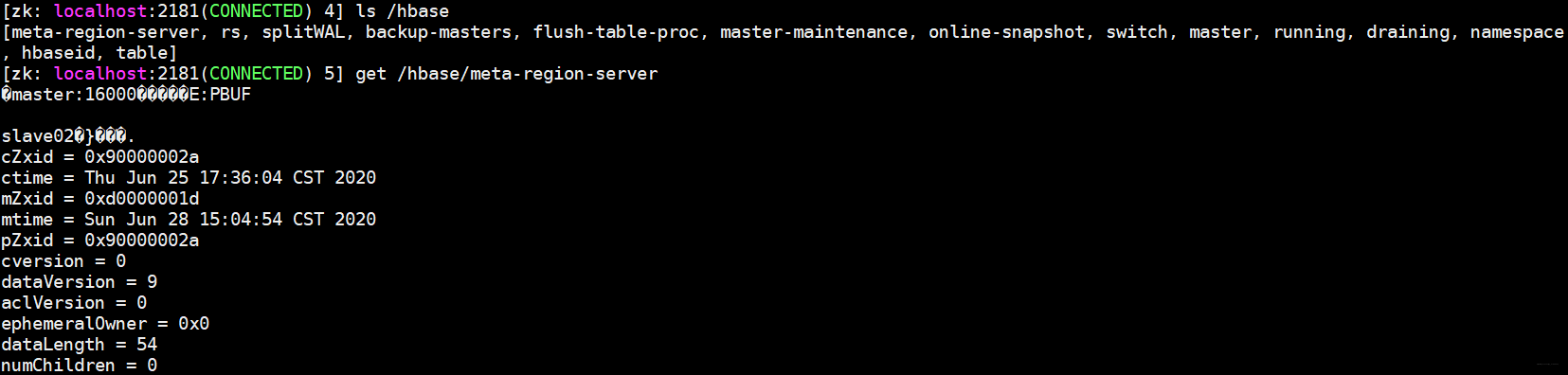

大致能看到我的meta表存在slave02节点上,那么client就会到这个节点上找meta表缓存一下(下次直接找缓存,若缓存没有就继续找zk)并且返回student表位置,接下来client就找到了我们需要插入的表,与指定节点建立连接后首先写到HLog中,对于client来说任务就结束了,它认为我数据写到内存中就不会丢失,不需要等到数据flush操作。
下面我们看看meta表内容到底是什么

它记录了所有表元数据,因此client主要就是取红线框住的部分与其建立连接。老版本的HBase还有一个-root-表,它是基于meta也要做切分考虑,因此老版本的逻辑是client向Zookeeper取-root-表,这个表存的是meta表的位置,然后从meta表取将要操作的表的位置信息。设计之初HBase害怕meta表过大所以让他加入切分逻辑,因此需要额外一张表来维护,但实际开发发现meta表根本就达不到切分要求(大于10G),因此新版本HBase摒弃了-root-表,在表进行切分操作时首先判断是不是meta表,让meta表不进入切分逻辑,这样仅用Zookeeper节点去维护即可。
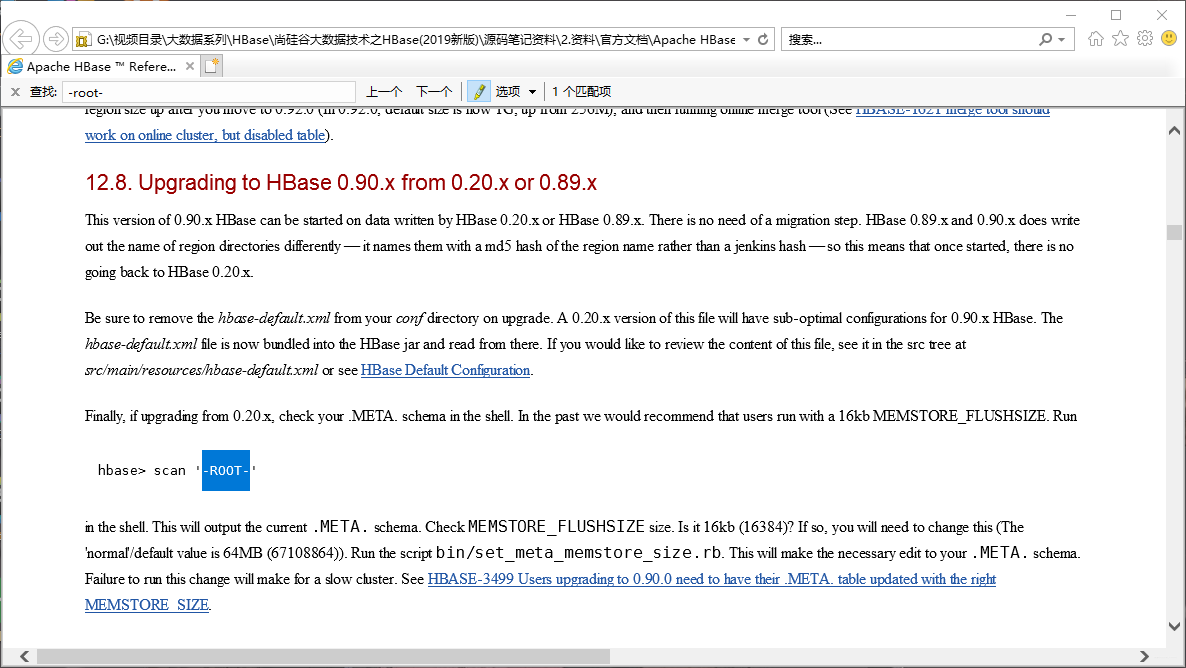
可以看到老版本(0.90.x)还让你去扫描-root-表,和我们扫描meta表是一样的逻辑
3.3 源码分析写流程
HBase的源码写的是真的好😄
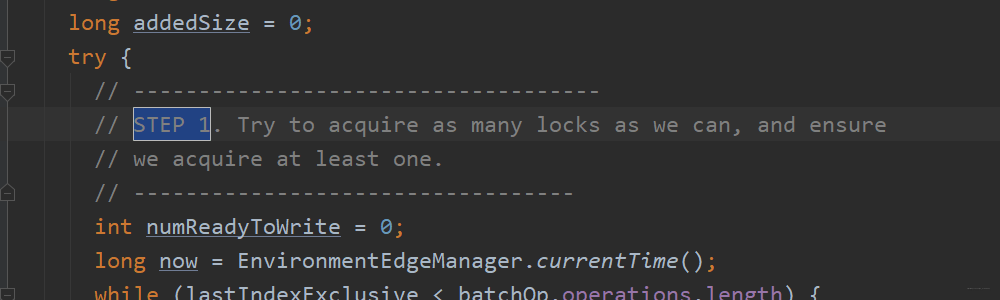
追HRegion这个类,因为最终的操作是一个个Region,可以搜一波STEP 1

第一步:获取锁。主要是为了读写分离,采用的是java.util.concurrent.locks.Lock
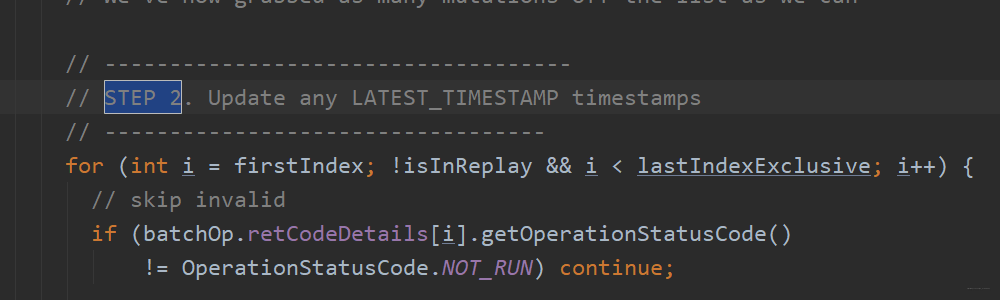
第二步:更新时间戳。更新的是服务端时间,因此即使windows时间真的无法与linux同步,我们调用API时就不传入时间戳即可。
第三步:构建wal文件
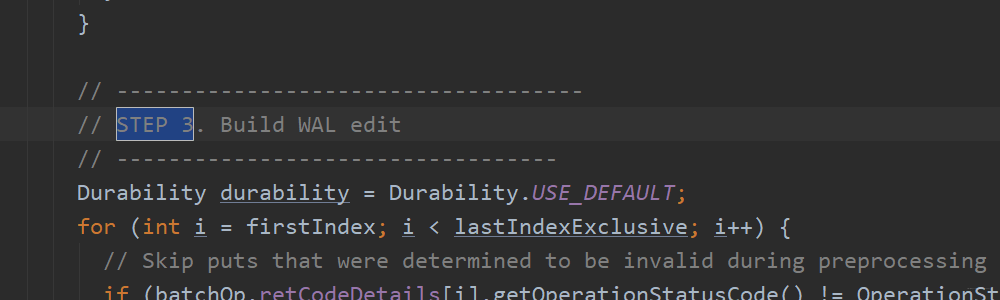
第四步:将记录操作的wal追加到最终的wal中,注意这里它没有选择同步,即没有写到HDFS中。
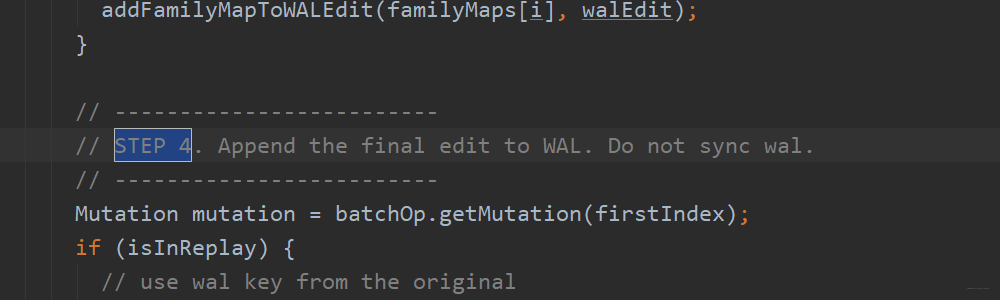
第五步:回写到memstore,what?memstore在哪?它是在内存中呀!难道它不怕这个时候断电,导致数据丢失吗?
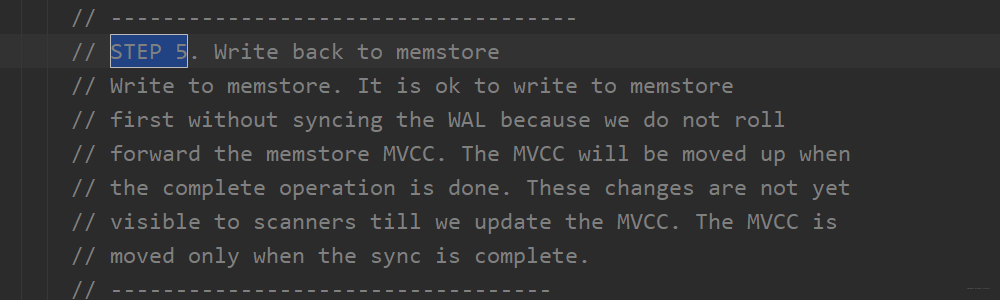
第六步:释放锁,也就意味着写流程结束。这时候所有的东西都在内存中。
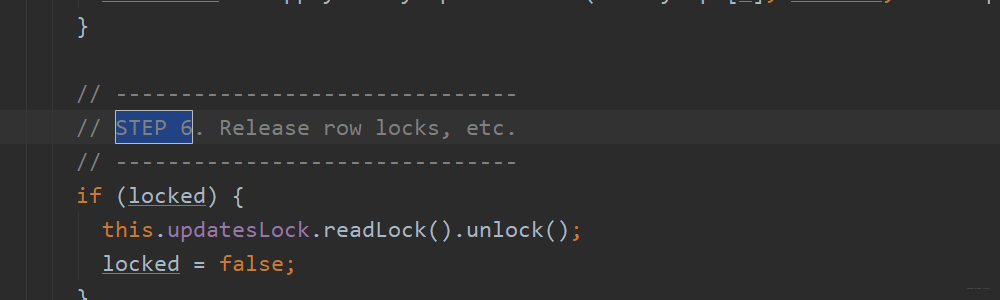
第七步:同步wal,即将其写到HDFS上。

最大的疑问:为什么HBase选择在写流程结束之后同步wal文件呢?万一断电岂不可惜,这里它做了一个事务的操作,看下面代码
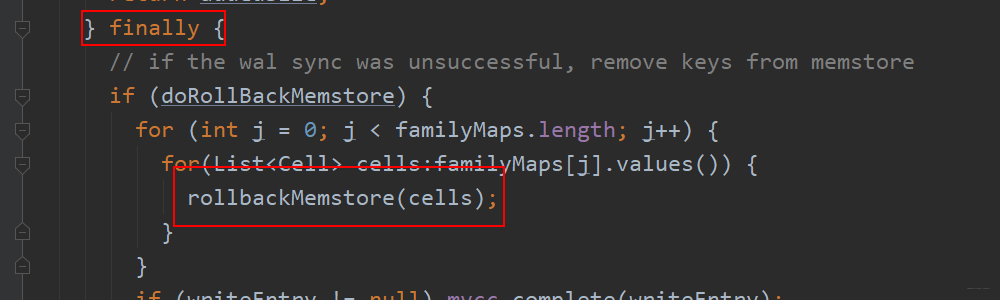
当同步失败的时候,删除写入memstore的数据并且回滚,注意这个逻辑是定义在finally的
总结:
client访问zookeeper,从中获取hbase:meta表所在的HResgionServer- 访问对应的
HResgionServer,获取hbase:meta写入缓存并从中去读预操作表在哪个HResgionServer哪个Region中 - 与对应的目标节点通讯
- 将操作追加到
wal中 - 将数据写入
memstore中,并在其中进行排序 - 同步
wal,返回ack,client写操作到此结束 - 等待
memstore刷写时机,将数据刷写到HFile
3.4 Flush
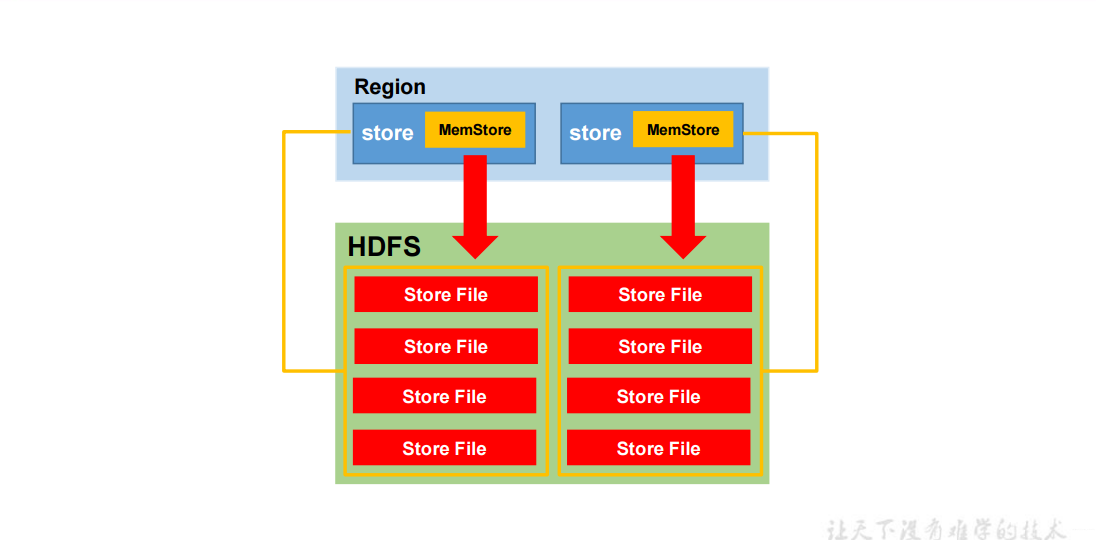
3.4.1 HRegionServer级别的flush
内存在一定条件下进行刷写操作,那么我们想到的条件有哪些?无非就是时间和大小。注意不同的store对应着不同的列族,即最终存储再不同的文件夹下面(隔离存储,可以提高效率),而之后的合并操作也只是对一个文件夹下的Store File进行合并。下面我们来看看刷写的时机都有哪些?
看一下HBase的默认配置文件
hbase.regionserver.global.memstore.size

当一个HRegionServer的全部memstore总量达到了jvm默认堆大小的40%时,触发HRegionServer级别的flush刷写,阻塞客户端的读写,HBase认为达到了这个级别很容易引起内存崩溃,因此它会暂停客户端的所有操作直到刷写全部完成。
hbase.regionserver.global.memstore.size.lower.limit

默认值为hbase.regionserver.global.memstore.size的95%,当一个HRegionServer中memstore总量达到这个数值HBase就开始读写,但是不会阻塞客户端读写操作,和hbase.regionserver.global.memstore.size搭配使用的意思就是,当达到hbase.regionserver.global.memstore.size.lower.limit时开始刷写,但若客户端的写操作速度大于刷写操作导致memstore总量持续增加达到了hbase.regionserver.global.memstore.size规定的大小,这就意味着客户端写数据太快,必须暂停一下等待flush完成;若客户端写操作速度小于刷写操作时,memstore总量下降直到低于hbase.regionserver.global.memstore.size.lower.limit刷写操作结束。
hbase.regionserver.optionalcacheflushinterval

一个小时自动刷写,若设置为0则关闭此功能,是一种“优先级略低的刷写”,这是什么意思呢?比如当客户端持续的进行写操作,但是写的数据特别小一个小时都没有达到默认堆的40%的95%,是不会触发刷写操作。这一个小时是指当前HRegionServer即这个节点内存最后一次编辑时间,对应的场景是长时间不操作,即这一个小时都没有新的数据进来那就进行刷写操作
HRegionServer级别的flush会按照memstore的大小进行顺序刷写,都要去刷写。
3.4.2 HRegion级别的flush
hbase.hregion.memstore.flush.size

当单个memstore达到128M时HRegion进行刷写操作,将其写入Store File中
还有一个老版本的配置hbase.regionserver.max.logs,即控制wal的大小,防止内存特别大,那么达到40%才进行刷写,那得刷多少数据呀。可以说wal和memstore是对等的。但目前版本这个配置不对用户开放,可以在HBase官网文档中找到。
3.5 读流程
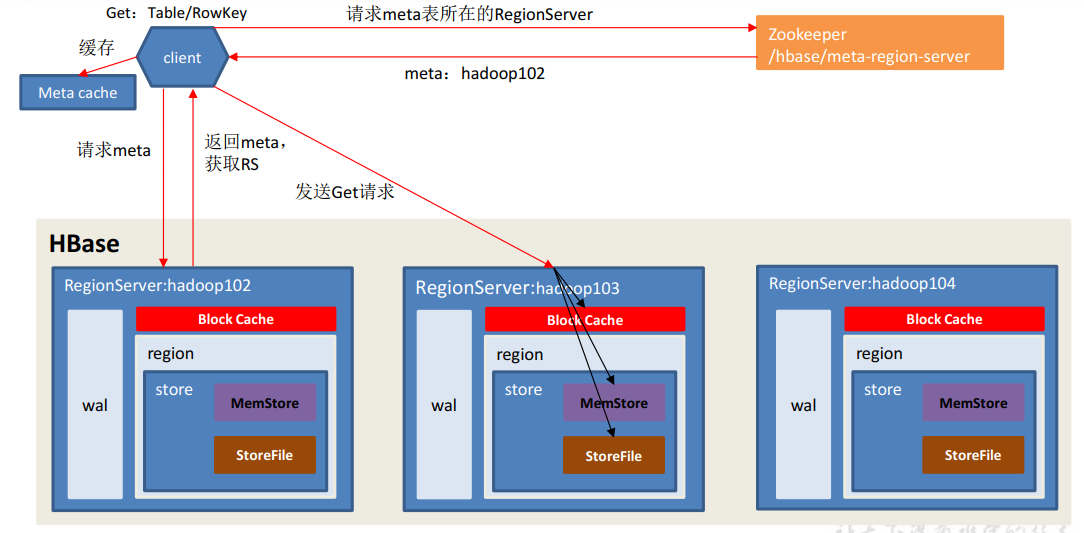
和写流程类似,首先client向Zookeeper拿到meta表所在的HRegionServer,去对应的节点读取meta表并返回将要操作的表所在的HRegionServer并且写入缓存以便下次使用,从对应的节点去读取文件,在读流程中会有一个Block Cache将最新读取的内容写入缓存中,使用的是是LRU算法,因此读取数据就面临着三个选择Block Cache(内存)、MenStore(内存)、StoreFile(磁盘),一般来说能从内存读绝不从磁盘读,例如先在内存找没有则去磁盘找,并且写入缓存中,但对于 ,这样做将会导致非常严重的后果。HBase来说不是这样的
上面的操作忽略了HBase最重要的元素——时间戳,设想下面这种情况,put 'stu','1001','info:name','zhangsan',timestmap1,这个时候数据大概率没有落盘,那么我手动flush将其写入HDFS中,随后我再次put 'stu','1001','info:name','lisi',timestmap2且timestmap1 > timestmap2,这个时候我通过get获取1001的数据,结果应该是zhangsan,但zhangsan此时是在磁盘中,内存中的却是lisi,是不是出问题了...
真正的操作是,同时读内存和磁盘并在Block Cache中进行比较,返回时间戳大的数据,同时存到缓存中方便下次读取。那么Block Cache的作用是什么?当Block Cache有的那个文件将不再扫磁盘的那个文件,注意是不扫缓存的那个文件,磁盘该扫还得扫,因此无论如何都要扫磁盘,当数据量大的时候甚至做全盘扫描,这就对应着前面说的那句话 ==HBase的写比读快==
3.6 StoreFile Compaction
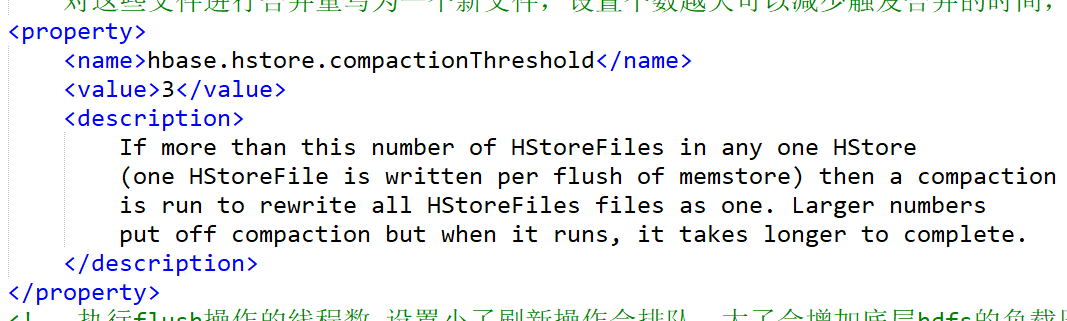
总结HBase的刷写逻辑发现,这种机制的刷写会产生很多小文件,因为最小的刷写都是HRegion级别的,一个HRegion会存在很多个Store对应着很多memstore存在刷写时部分memstore数据量少的情况,而HDFS是不擅长管理小文件的,因此HBase必须得有处理小文件的机制,即compact。HBase合表的机制分为两种分别是Minor Compaction和Major Compaction,它们的区别在于Minor Compaction属于小合并,将相邻的几个小文件合并成稍微大一点的文件(相邻的的意思就是在一个store中,因为不同的store是分文件夹存储,即仅合并一个文件夹下的),而Major Compaction属于大合并,不管文件大小全部合成一个文件。它们最大的区别是Minor Compaction合并不会删除数据,即一些被打了Delete标记或旧VERSIONS文件是不会删除的,而Major Compaction合并文件时会对其进行删除操作,且官网用的词是rewrite重写,意思就是读到内存修改再写回磁盘,因此Major Compaction非常消耗资源。下面是Compaction的一些配置

默认配置是7天进行一次Major Compaction,一到这个时间点就触发,万一此时客户端正在进行大规模的读写操作将非常危险,因此建议设置为0,找一个合适的时间手动调用major_compact
当一个Store即一个文件夹下有三个文件时会自动触发Major compact,考虑到数据的一致性,并不会立刻删除合并前的文件即使你是手动触发合并操作,亲测虚拟机在2分钟后自动删除,当不手动触发时,也不会一旦到了三个文件就立刻合并,并没有关注过到底多长时间自动合并(估计得按小时计算)。
hbase(main):007:0> put 'student','1001','info1:name','zhangsan'
hbase(main):008:0> flush
通过这种方式让一个Region里面刷写出4个文件
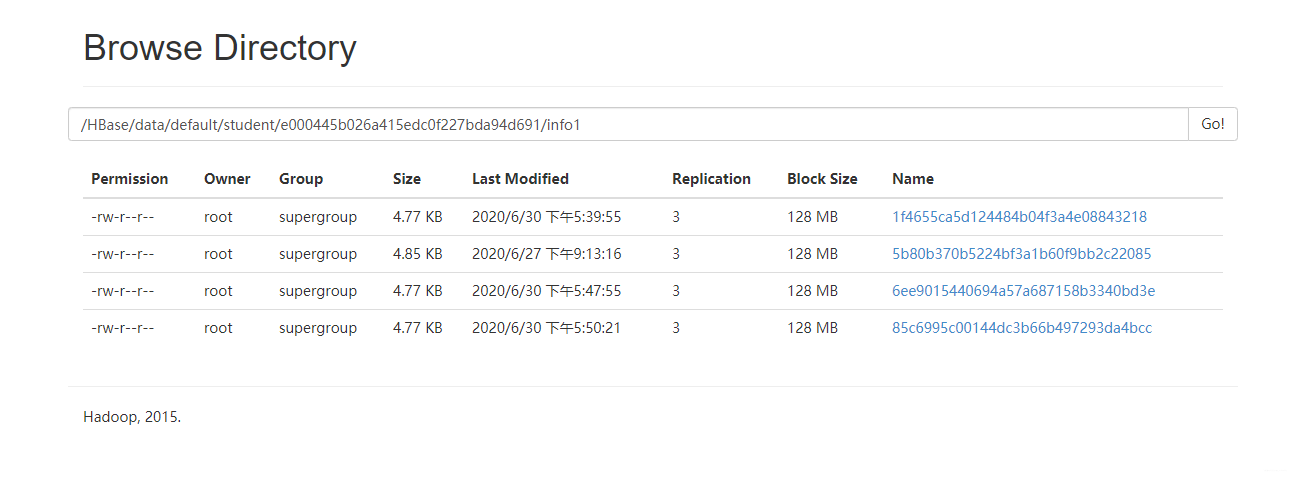
吃个饭的时间都没有自动合并,于是我开始手动合并
hbase(main):014:0> compact 'student'
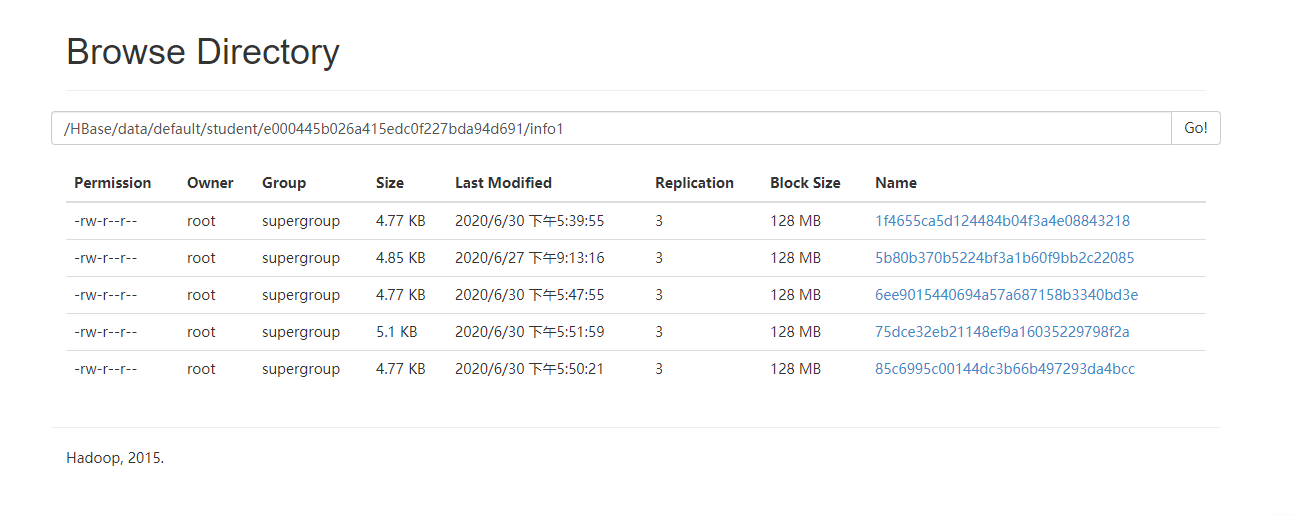
手动合并出一个文件(当文件数多于三个是,compact底层走的也是major_compact),静等几分钟合表前的数据就会被删除。
3.7 来点“恶心”的操作
根据上面的读写流程发现根本就没有master什么事,确实在关于数据的增删改查是不经过master的,因此下面我们试图kill掉HMaster进程测试是否能够继续进行curd操作。

此时HMaster已经被干掉了,然后启动客户端进行curd,发现并不影响我的操作

hbase(main):006:0> create 'stu','info'
ERROR: KeeperErrorCode = NoNode for /hbase/master
For usage try 'help "create"'
Took 0.0934 seconds
但是建表语句就会报错,且是Zookeeper的报错,因此之后的API操作只要连接Zookeeper即可
突然想到我漏了一个小的知识点,那就是flush也能删除数据,但和合表操作删除不太一样。可以做这样的实验,连续put两次数据让后一条数据覆盖前一条,然后手动flush表,此时再scan 'stu',{RAW=>true,VERSIONS=>10},会发现原先的数据被删除了,但若你put一次flush一次就不会被删除,因此flush会根据设定的VERSIONS值删除内存中的数据,已经刷写到磁盘的就不归flush管。
3.8 Split
核心原理最后一部分
当持续进行合表操作时,表会越来越大,大到一定程度就要进行切分,那么切分也有它的时机。
hbase.hregion.max.filesize

任何列族超过这个大小(10G)对于老版本来说会将其一分为二,但是新版本(0.94版本之后)会有一个公式,当某个列族下所有文件超过min(hbase.hregion.max.filesize,hbase.hregion.memstore.flush.size*R^2)
即min(10G,128M*R^2)其中R为Region数,切分是按照Row Key。
HBase核心原理到此结束,另一篇博客将开启HBase实战及其优化
评论区