


flink 1.16 发版之处,Apache Flink PMC&Committer 伍翀(云邪)在 9 月 24 日 Apache Flink Meetup 的演讲《Flink 1.16:Hive SQL 如何平迁到 Flink SQL》
在实际迁移过程中面临的挑战主要有以下三种:
- hive 的元数据是否需要迁移
- hive 的管理的数据是否需要迁移
- hivesql 是否需要重写
技术验证
要做到 Hive SQL 平滑迁移的第一步就是 Flink 能否完美继承 Hive 的元数据,否则一个稳定运行的 Hive 数仓管理的库、表将是非常庞大的,如果需要进行迁移其工作量以及技术成本将是不可评估的;元数据的兼容将直接影响到数据的迁移,因为 Hive 管理的数据通常是在 HDFS 中,如果元数据得以继承 Flink 按照 Schema 读取 HDFS 数据是很容易做到的;但是第三点将是整个迁移工作能否进行的最关键因素,要求 Flink 能够几乎完美的继承 Hive 的语法,否则复杂的业务建模 SQL 将面临重写,这些对于数仓开发人员是不可能被接受的。下面将正对这三点做技术验证。
幸运的是,得易于 Flinksql Catalog 功能,Flink 可以管理多个元数据空间,Hive 的 Metastore 就在其中,而 Hive Catalog 不仅仅在 Flink on Hive 中被使用,在几乎所有要求持久化元数据空间场景中 Hive Catalog 都是很优秀的解决方案。下面简单介绍一下 Flink 的 Catalog。
关于 Catalog 的定义这里不做过多介绍,Flink 默认的 Catalog 实现是GenericInMemoryCatalog,在创建表执行环境时被创建
final CatalogManager catalogManager =
CatalogManager.newBuilder()
.classLoader(userClassLoader)
.config(tableConfig)
.defaultCatalog(
settings.getBuiltInCatalogName(),
new GenericInMemoryCatalog(
settings.getBuiltInCatalogName(),
settings.getBuiltInDatabaseName()))
.executionConfig(executionEnvironment.getConfig())
.build();
从名字就可以看出其元数据是保存在内存中仅当前 session 有效,而它的实现也很简单:将各类元数据以Map的形式存储在内存中
public static final String DEFAULT_DB = "default";
private final Map<String, CatalogDatabase> databases;
private final Map<ObjectPath, CatalogBaseTable> tables;
private final Map<ObjectPath, CatalogFunction> functions;
private final Map<ObjectPath, Map<CatalogPartitionSpec, CatalogPartition>> partitions;
private final Map<ObjectPath, CatalogTableStatistics> tableStats;
private final Map<ObjectPath, CatalogColumnStatistics> tableColumnStats;
private final Map<ObjectPath, Map<CatalogPartitionSpec, CatalogTableStatistics>> partitionStats;
private final Map<ObjectPath, Map<CatalogPartitionSpec, CatalogColumnStatistics>> partitionColumnStats;
对于持久化 Catalog 的方案各大连接器均有实现,例如:
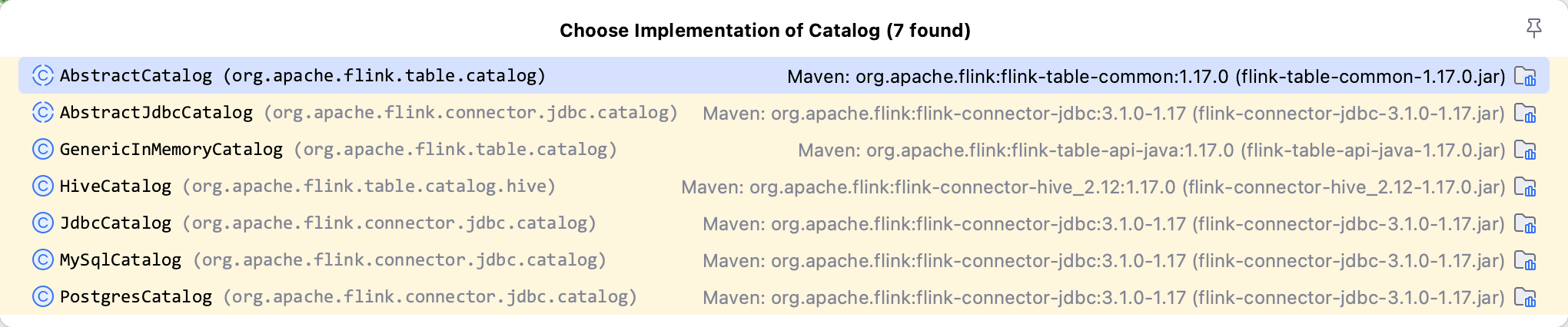
本文主要介绍 HiveCatalog 并使用sql-client进行演示。首先下载 flink hive 连接器并放置到${FLINK_HOME}/lib下,创建 Hive Catalog
首先需要下载相关依赖到${FLINK_HOME}/lib中,列表如下:
flink-connector-hive_2.12-1.17.0.jar
hive-exec-3.1.3.jar
libfb303-0.9.3.jar // 在 hive 3.1.3 中 exec 没有包含 libfb303,这个包主要是做 thrift 通信的
最终文件目录树结构如下

注:这里的 guava 主要是因为 flink 与 hadoop 的 guava 有冲突,使用 hadoop 的 guava
一切准备就绪,别忘了启动 hive metastore 服务和 flink 集群(测试使用 standalone 模式)。
启动sql-client
export HADOOP_CLASSPATH=`hadoop classpath`
bin/sql-client.sh embedded
创建名为 hive 的 catalog,这种方式的 catalog 信息也是临时的,但创建在此 catalog 的库表不会消失,只需要下次创建相同的 catalog 即可,如果想要 catalog 也保留可以在sql-client-defaults.yaml文件中配置此 catalog 信息。
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = '/Users/wjun/env/hive/conf'
);
查看当前 catalog
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| hive |
+-----------------+
2 rows in set
应用名为 hive 的 catalog
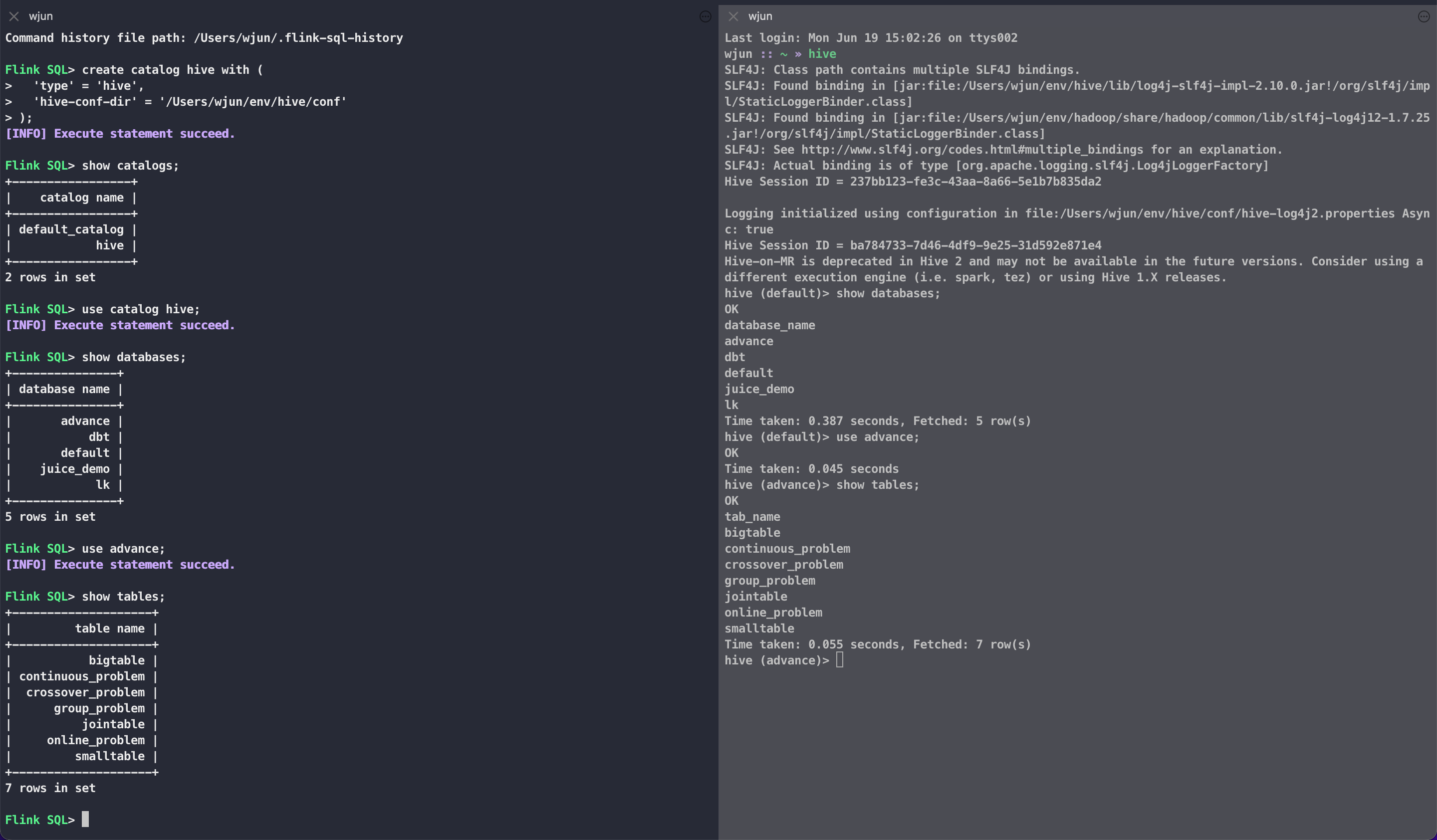
Flink SQL> use catalog hive;
[INFO] Execute statement succeed.
此时可以发现 FlinkSQL 可以完美继承 Hive 的元数据,可以看到 Hive 中已创建的库、表
那么 flink 可以直接读取 hive 的数据吗?仅这一点 flink 就做了大量的工作,对于 flinksql 会经过 flink parser 转换为 flink relnode,后续在经过 LogicalPlan、Physical Plan、JobGraph;对于 hivesql 复用了 flink sql 的很多核心逻辑和代码,仅仅引入了 hive parser 将 hive sql 转换为 flink relnode 降低了 flink on hive 的代码复杂性。基于此理论上 flink 就可以直接读取 hive 的表数据
select * from bigtable limit 10;
执行结果如下:

执行一些简单的聚合查询
select keyword, count(1) from bigtable group by keyword order by 2 desc limit 10;
执行结果如下

在执行过程中该结果是在实时变化的且排序的结果似乎不对,这是因为此时 flink 以流模式进行计算,作为流批一体的计算框架当然也支持批处理,只需要一个配置即可
set 'execution.runtime-mode' = 'batch';
再次执行则是批处理与 hive 执行的结果是一致的。那么是否可以下解决说 HiveSQL 迁移完成且零成本?答案是否定的。
因为上述演示的只是简单 sql,这些通用语法 flink 也是支持的,其本质我们使用的 flinksql 而并非 hivesql,如果此时直接通知数仓开发人员直接来使用得挨喷,例如:按照 hive 习惯我想创建一个 sannpy 压缩 orc 存储格式的表来保存上述的 top10 结果(别管这个需求合不合理),sql 如下:
create table keyword_top10
(
keyword string,
num bigint
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties ("orc.compress" = "SNAPPY");
放到 flinksql 中呢!显然是直接语法解析错误
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.sql.parser.impl.ParseException: Encountered "row" at line 6, column 5.
Was expecting one of:
<EOF>
"AS" ...
"LIKE" ...
"WITH" ...
"COMMENT" ...
"PARTITIONED" ...
";" ...
同时谁也不敢保证 hive 庞大且功能强大的函数 flink 都支持(函数名保持一致、入参出参也一样)
幸运的是 flinksql 支持使用 hivesql 的方言,仅需要有限的几步配置(以 flink 1.17 为例,不同版本操作存在差异以官方文档为准)
- 下载 antlr-runtime-3.5.3.jar 到 lib 下
- 移除 lib 下的 flink-table-planner-loader-1.17.0.jar
- 将 opt 下的 flink-table-planner_2.12-1.17.0.jar 移入 lib

注:hive 语法需要在 hive 的 catalog 下使用
打开 hive 方言的支持
set table.sql-dialect=hive;
下面继续创建之前未成功创建的 hive 表,此时就可以创建成功,接下来将 hive 的数据通过 flink 回写到 hive。
可以发现此时执行的是 flink 任务
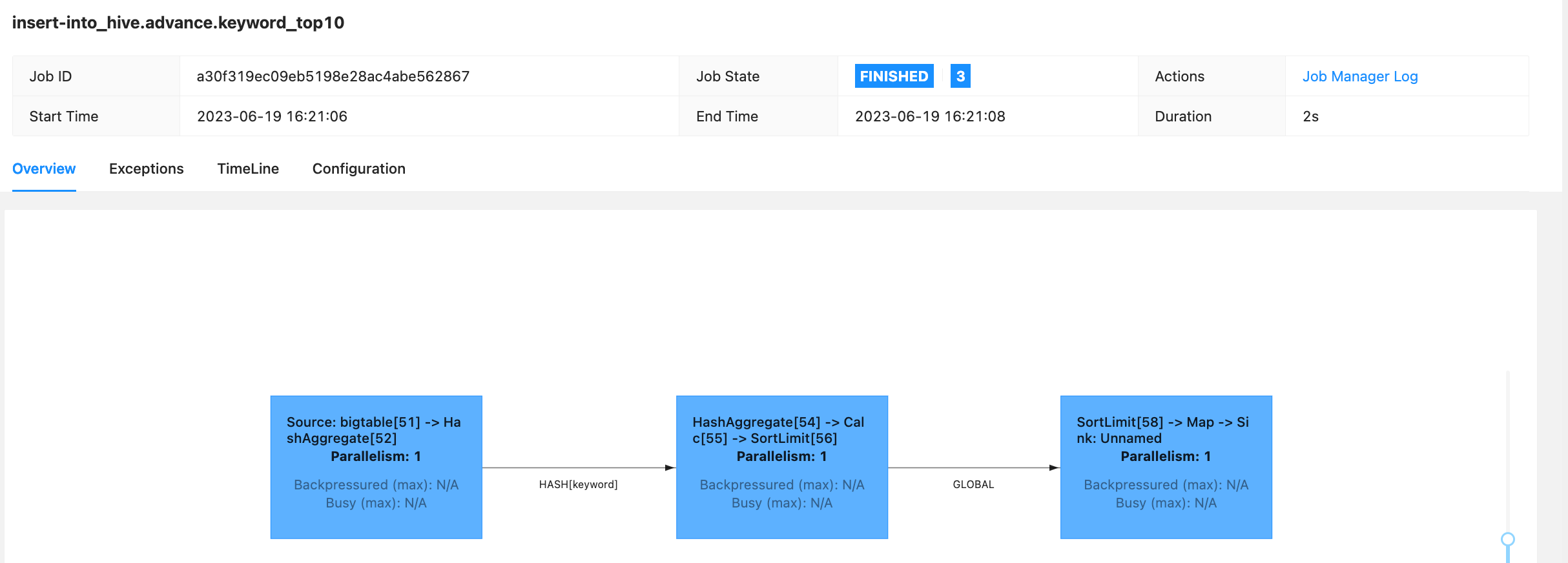
注:目前 hive dialect 并不能完全兼容 hive 的所有函数,期待 flink 的发展
评论区