


flink 调优第一步便是资源调优,在一定范围内,增加资源的分配与性能的提升成正比;在实现最优的资源配置后再去考虑后续的性能调优策略
从一个 flink 任务提交命令开始
bin/flink run \
-t yarn-per-job \
-p 5 \
-Djobmanager.memory.process.size=2048mb \
-Dtaskmanager.memory.process.size=4096mb \
-c tech.kpretty.ck.DemoCheckPoint \
jobs/dev-audit-1.0-SNAPSHOT-jar-with-dependencies.jar
一、内存模型
1.1 TaskManager
当进行资源调优时,最直接的方式就是资源翻倍,如:将 TaskManager 内存由 4G 提高到 8G,这种手段往往是有效的,但并不是最优方案,因为我们必须要了解 flink 的内存模型,了解 flink 每个内存空间的使用率;一味地提高 TaskManager 内存可能对某个告急的内存空间提高并不高,因此 flink 的内存模型将是调优的第一步。
从提交任务的 WebUI 上 flink 已经给出了 TaskManager 的内存模型,如下图:
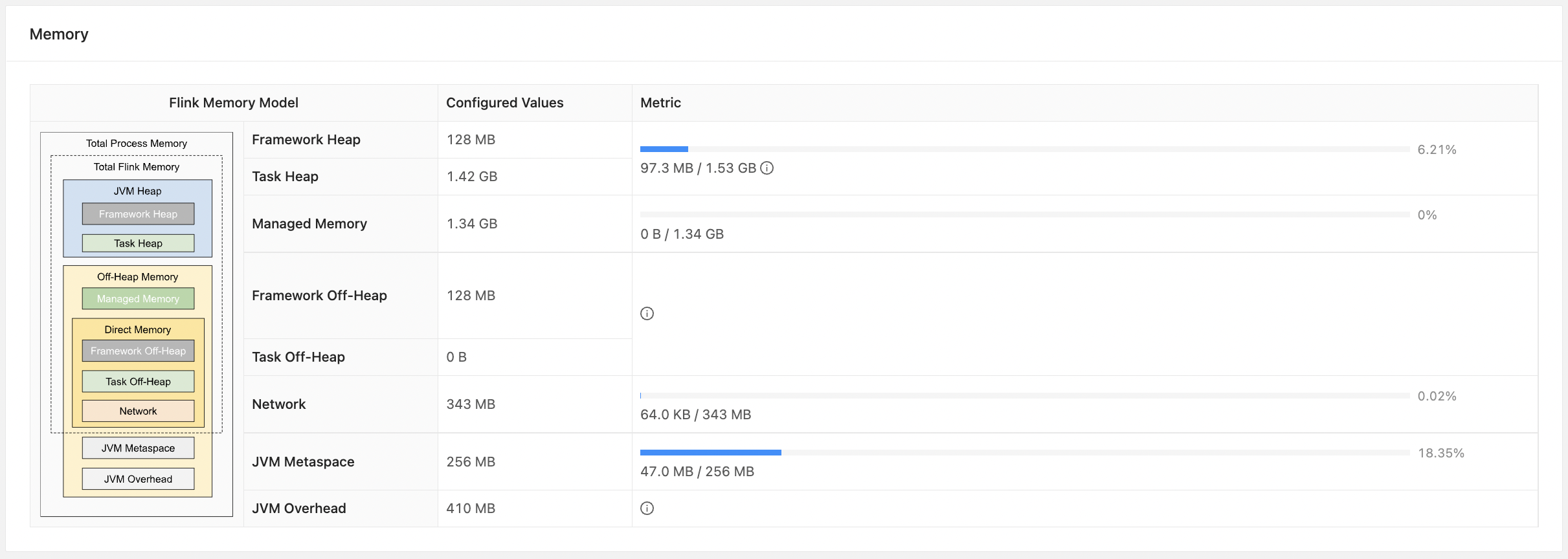
这里对每个内存空间从上往下一次介绍其主要作用:
-
Total Process Memory:总进程空间,对于 flink on yarn 来说,就是 taskmanager.memory.process.size 内存也可以理解是 yarn 每个 Container 内存,为什么说可以理解?因为受限于 yarn 的资源调度 Container 的内存是可以大于 taskmanager.memory.process.size 指定的内存,对出来的内存将不被 flink 所使用
-
JVM 特定内存:JVM 自身使用的内存
- JVM Metaspace:JVM元空间,通过 taskmanager.memory.jvm-metaspace.size 指定,默认 256M
- JVM Overhead:JVM执行开销,保存 JVM 执行自身所需要的内存,如:线程堆栈、IO、编译缓存等,通过如下方式调整
# JVM Overhead = min(max(Total Process Memory * fraction,192MB),1GB) taskmanager.memory.jvm-overhead.fraction=0.1 taskmanager.memory.jvm-overhead.min=192MB taskmanager.memory.jvm-overhead.max=1GB -
Total Flink Memory:flink 内存,总进程内存 - JVM 自身使用的内存
-
框架内存:flink 框架内存,TaskManager 自身所需要的内存,不计入 slot 的资源中
- Framework Heap:框架堆内存,通过 taskmanager.memory.framework.heap.size 指定,默认 128MB
- Framework Off-Heap:框架堆外内存,通过 taskmanager.memory.framework.off-heap.size 指定,默认 128MB
-
Task 内存:执行用户代码所使用的内存
- Task Heap:任务堆内存,通过 taskmanager.memory.task.heap.size 指定,默认 none,由 flink 内存扣除其余部分得到的
- Task Off-Heap:任务堆外内存,通过 taskmanager.memory.task.off-heap.size 指定,默认 0 表示不适用堆外内存
-
Network:网络内存,用于任务之间数据传输的直接内存,通过如下方式调整
# Network = min(max(Total Flink Memory * fraction,64MB),1GB) taskmanager.memory.network.fraction=0.1 taskmanager.memory.network.min=64MB taskmanager.memory.network.max=1GB -
Managed Memory:管理内存,用于 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存,通过如下方式调整
# Managed Memory = taskmanager.memory.managed.size != none ? taskmanager.memory.managed.size:Total Flink Memory * 0.4 taskmanager.memory.managed.fraction=0.4 taskmanager.memory.managed.size=none # 没指定为 flink 内存的 0.4
以开篇的启动命令为例,得 Total Process Memory = 4096MB
+ Total Process Memory = 4096MB
————> JVM Metaspace 为默认值
+ JVM Metaspace = 256MB
————> min(max(4096MB * 0.1,192MB),1GB) = 410MB
+ JVM Overhead = 410MB
————> 4096MB - 256MB - 410MB = 3430MB
+ Total Flink Memory = 3430MB
————> 框架内存为默认值
+ Framework Heap = 128MB
+ Framework Off-Heap = 128MB
————> 任务堆外内存为默认值
+ Task Off-Heap = 0MB
————> min(max(3430MB * 0.1,64MB),1GB) = 343MB
+ Network = 343MB
————> Managed Memory 为默认值,且未指定
+ Managed Memory = 3430MB * 0.4 = 1372MB
————> 3430MB - 128MB - 128MB - 343MB - 1372MB = 1459MB
+ Task Heap = 1459MB
与开篇 flink 给出的内存模型基本一致;flink 进程启动时,会根据配置或自动推导各内存的大小后,显式地设置 JVM 参数,规则如下:
- -Xmx和-Xms = Framework Heap + Task Heap
- -XX:MaxDirectMemorySize = Framework Off-Heap + Task Off-Heap + Network
- -XX:MaxMetaspaceSize = JVM Metaspace
大胆推测一下:
JVM Options:
-Xmx1587MB
-Xms1587MB
-XX:MaxDirectMemorySize=471MB
-XX:MaxMetaspaceSize=256MB
如何合理的调整各部分内存以及整体的进程内存
- 若任务中没有使用到 RocksDB 作为状态后端,那么 Managed Memory 直接设置为 0,如 taskmanager.memory.managed.size=0
- 剩下的内存空间,则需要结合 WebUI 进行合理分配
- 若每个内存空间使用率都是 90%,则需要提高整体的进程空间内存
- 若部分内存空间使用率高,大部分内存空间使用率低,则可以划出一部分空间的内存给使用率高的部分
1.2 JobManager
JobManager 的内存模型相对简单,可配置的不多

其中 JVM Metaspace、JVM Overhead 与上述一致,配置方式为只需将 taskmanager 替换成 jobmanager
Off-Heap Memory:堆外内存,通过 jobmanager.memory.off-heap.size,默认 128MB
JVM Heap:JVM 堆内存,通过 jobmanager.memory.heap.size,默认 none,若没有指定则通过 Total Process Memory 减去其余部分,但不能低于 128MB
JobManager 更多的内存配置可查看官网:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/memory/mem_setup_jobmanager/
最后解释一下:基于 yarn 模式 Container 内存和 TaskManager/JobManager 总进程内存不一致情况,主要是受 yarn 资源调度的影响
2022-05-25 17:15:16,027 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1024 MB. YARN will allocate 1536 MB to make up an integer multiple of its minimum allocation memory (1536 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 512 MB may not be used by Flink.
2022-05-25 17:15:16,027 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 4096 MB. YARN will allocate 4608 MB to make up an integer multiple of its minimum allocation memory (1536 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 512 MB may not be used by Flink.
2022-05-25 17:15:16,027 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1536, taskManagerMemoryMB=4096, slotsPerTaskManager=1}
二、cpu配置
基于 yarn 的 cpu 配置也就是 vcore 的配置,默认情况下一个 Container 一个 vcore,而 Flink 任务的 TaskManager 数量与 Container 数量一一对应,默认情况一个 TaskManager 中只有一个 slot,结合上一篇文章如何计算一个 flink 任务需要多少个 slot,可以知道开篇的任务需要 5 个 slot,因此默认情况下需要 5 个 TaskManager,外加一个 JobManager,因此 yarn 需要分配 6 个 Container 和 6 个 vcore,如图

可以通过 -Dtaskmanager.numberOfTaskSlots 配置一个 TaskManager 中可以有多少个 slot,如修改启动脚本
bin/flink run \
-t yarn-per-job \
-p 5 \
-Djobmanager.memory.process.size=2048mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c tech.kpretty.ck.DemoCheckPoint \
jobs/dev-audit-1.0-SNAPSHOT-jar-with-dependencies.jar
提交之前可以先推测一下,此时一个 TaskManager 可以运行 2 个 slot,因此整个任务只需要 3 个 TaskManager,外加一个 JobManager,此时 yarn 需要分配 4 个 Container

但此时,一个 Container 使用一个 vcore 运行两个 slot,若想要 vcore:slot 为 1:1,虽然 slot 并不能隔离 cpu。yarn 的容量调度器默认使用 DefaultResourceCalculator 分配策略,只根据内存调度可用资源,所以 yarn 给每个容器的 vcore 个数就是 1,即使通过 -Dyarn.containers.vcores 指定更多个 vcore 也不起作用;解决方案是修改默认的分配策略 capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> -->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
可通过下面命令动态更新 capacity-scheduler.xml 的配置
yarn rmadmin -refreshQueues
三、并行度配置
3.1 全局并行度配置
开发完成后,先进行压测,测试单并行度的处理上限最后基于总的 QPS /单并行度的处理上限向上取整即可,这里的总 QPS 最好是高峰阶段的压测。同时建议预留一部分资源如取整后的并行度提高 0.2 倍左右。单并行度的处理上限可以在 WebUI 中获取如:
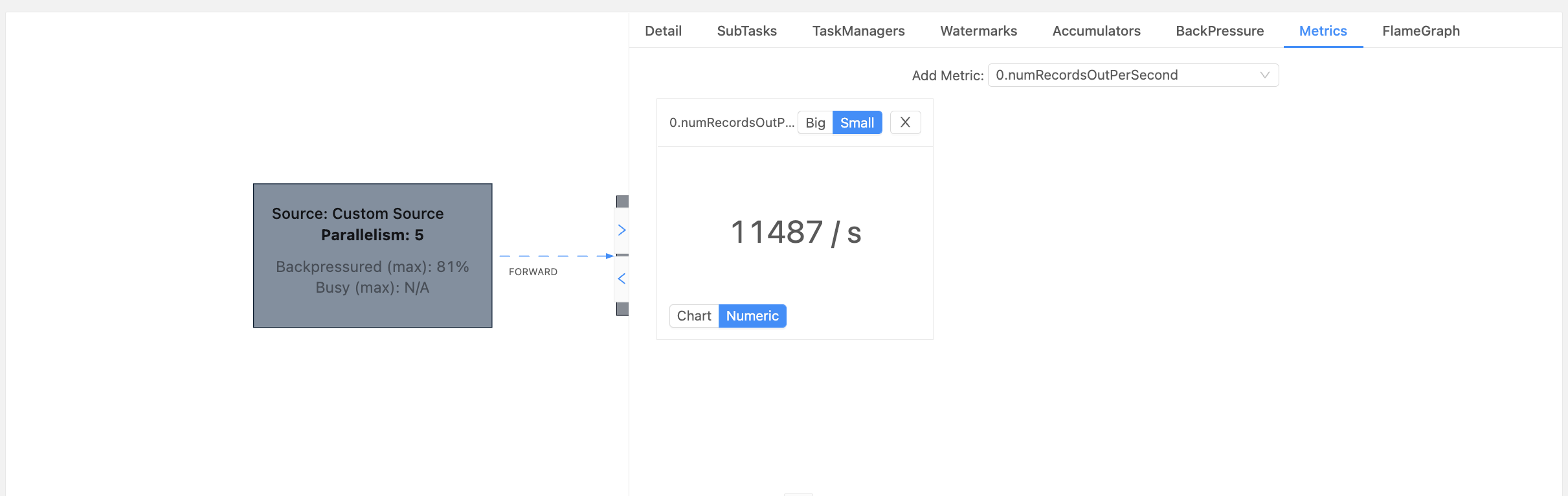
如上图,是一个处于反压状态的 source 算子,通过 Metrics 获取每秒的数据条数(其他指标也可以),再结合高峰时期的 QPS 即可推算出大致的全局并行度
3.2 source 并行度
如果数据源是 kafka 那么 source 的并行度就是 topic 的分区数,如果已经等于 kafka 的分区数,通过 kafka 的脚本查看发现数据仍有积压,考虑扩大 kafka 的分区数,同时提高 source 的并行度。
3.3 transform 并行度
这类算子链通常以 keyBy 为分割线,
- keyBy 之前的算子一般不会有太重的操作,如 map、flatMap、filter 等,并行度保持和 source 一致
- keyBy 之后的算子若并发度较大建议设置为 2 的整次幂
3.4 sink 并行度
如果数据源是 kafka 那么 sink 的并行度就是 topic 的分区。其他数据源则需要考量下游服务的抗压能力,若 sink 数据量小,如监控告警等可以设置较小的并行度;若存在数据膨胀情况如对数据做了细粒度的拆分则 sink 的并行度就需要增加。
总结:并行度的配置是一个综合考量并不断试错的过程
评论区