


最近在群里看到很多初学大数据的同学在搭建 hadoop 集群时遇到各种问题,甚至在搭建虚拟机时频频出错,如:网络问题、权限问题等等。于是乎借着 docker 出一篇基于 docker 的 hadoop 搭建,计划启动三个容器一主两从的模式,下面就开始吧!!!
构建基础镜像
本次使用的环境是 docker for mac m1,自身为 arm64 架构,注意根据自身架构替换一些必要的地方,我会尽可能的提出来。
思路:基于官方的 centos7 镜像,将 jdk、hadoop 整合进去,同时创建一个用户和用户组来管理 hadoop 服务,之后安装 ssh 服务并启动
创建一个空白的目录作为 docker 的上下文目录
➜ ~ mkdir dockerfile;cd dockerfile;touch Dockerfile
Dockerfile 文件内容如下:
FROM centos:centos7
MAINTAINER wjun
# 切换工作目录
WORKDIR /opt/hdp
# 复制 hadoop java 文件
ADD hadoop-3.3.1-aarch64.tar.gz ./
ADD jdk-8u291-linux-aarch64.tar.gz ./
# 安装 ssh 服务
RUN yum install -y openssh-server openssh-clients rsync vim\
&& ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key -N "" -q \
&& ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N "" -q \
&& ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key -N "" -q \
&& groupadd hadoop \
&& useradd hdfs -g hadoop \
&& echo "root:root" | chpasswd \
&& echo "hdfs:hdfs" | chpasswd \
&& mkdir /var/run/sshd \
&& mkdir /opt/hdp/tmp \
&& chown -R hdfs:hadoop /opt/hdp \
&& mv hadoop-3.3.1 hadoop \
&& mv jdk1.8.0_291 jdk
# 暴露端口
EXPOSE 22 9870 8088 50070
# 预定持久化文件的目录
VOLUME /opt/hdp/tmp
# 运行 ssh 服务
CMD ["/usr/sbin/sshd","-D"]
同时将 hadoop-3.3.1-aarch64.tar.gz、jdk-8u291-linux-aarch64.tar.gz 复制到当前目录下,注意文件名和之后对文件的重命名,根据具体压缩包解压后名称来定。
构建镜像
docker build -t hadoop .
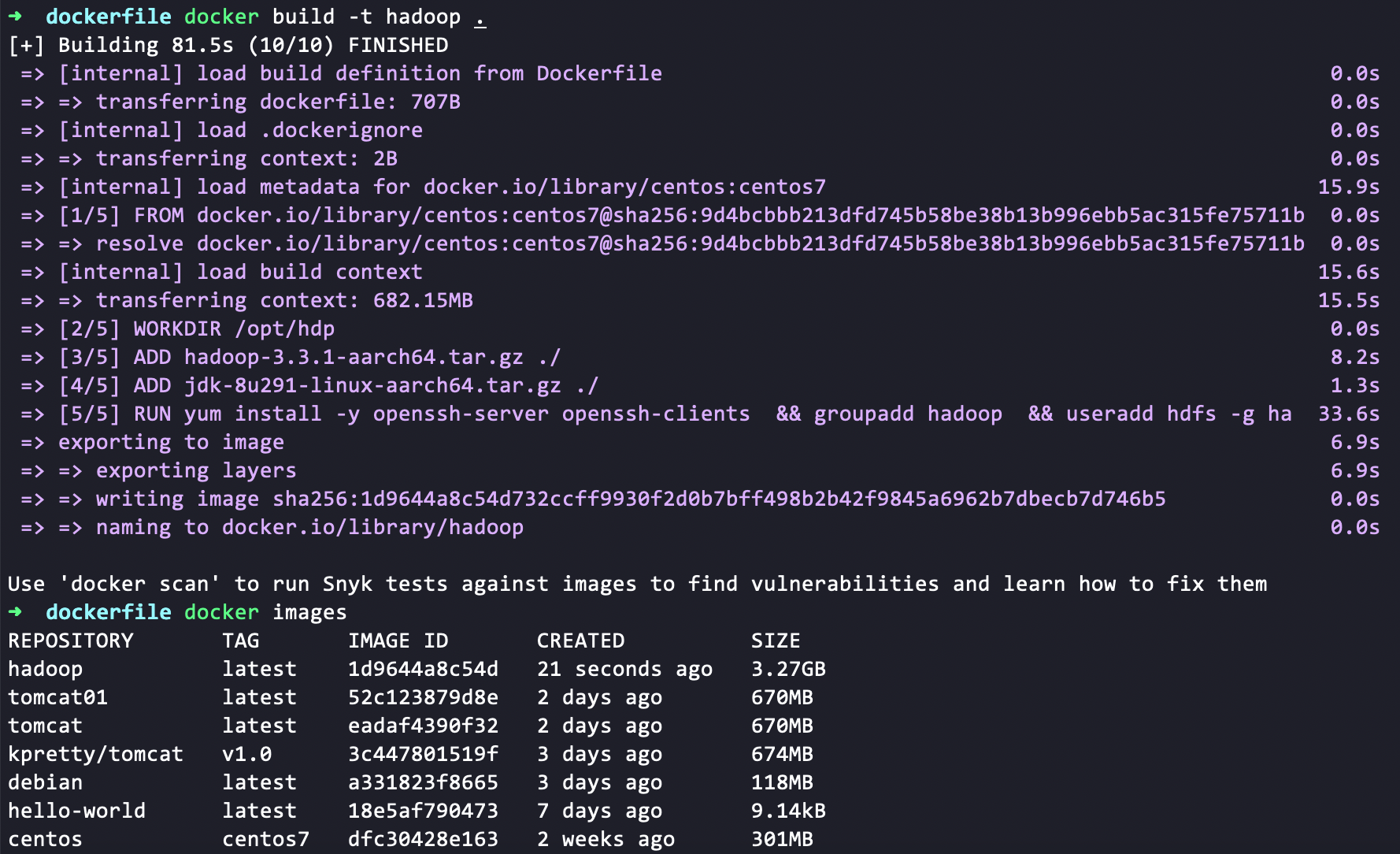
构建成功...
基于此镜像启动三个容器,通过 docker-compose 来编排,文件如下:
version: "3.0"
services:
hadoop-master:
image: hadoop:latest
ports:
- "9870:9870"
- "50070:50070"
- "8088:8088"
networks:
- docker0
volumes:
- v_master:/opt/hdp/tmp
container_name: hadoop101
hadoop-slave1:
image: hadoop:latest
networks:
- docker0
volumes:
- v_slave1:/opt/hdp/tmp
container_name: hadoop102
hadoop-slave2:
image: hadoop:latest
networks:
- docker0
volumes:
- v_slave2:/opt/hdp/tmp
container_name: hadoop103
networks:
docker0:
volumes:
v_master:
v_slave1:
v_slave2:
启动:
➜ docker-compose up
Creating network "hadoops_docker0" with the default driver
Creating volume "hadoops_v_master" with default driver
Creating volume "hadoops_v_slave1" with default driver
Creating volume "hadoops_v_slave2" with default driver
Creating hadoop101 ... done
Creating hadoop102 ... done
Creating hadoop103 ... done
Attaching to hadoop103, hadoop102, hadoop101
当前路径新开一个 session,或者上述命令后台启动 -D
➜ docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------
hadoop101 /usr/sbin/sshd -D Up 22/tcp, 0.0.0.0:50070->50070/tcp,:::50070->50070/tcp,
0.0.0.0:8088->8088/tcp,:::8088->8088/tcp,
0.0.0.0:9870->9870/tcp,:::9870->9870/tcp
hadoop102 /usr/sbin/sshd -D Up 22/tcp, 50070/tcp, 8088/tcp, 9870/tcp
hadoop103 /usr/sbin/sshd -D Up 22/tcp, 50070/tcp, 8088/tcp, 9870/tcp
尝试进入其中 hadoop101 容器内部:
docker exec -it hadoop101 bash
查看容器见是否互通
[root@975d861c5b64 hdp]# ping hadoop102
PING hadoop102 (172.18.0.3) 56(84) bytes of data.
64 bytes from hadoop102.hadoops_docker0 (172.18.0.3): icmp_seq=1 ttl=64 time=0.228 ms
64 bytes from hadoop102.hadoops_docker0 (172.18.0.3): icmp_seq=2 ttl=64 time=0.327 ms
64 bytes from hadoop102.hadoops_docker0 (172.18.0.3): icmp_seq=3 ttl=64 time=0.380 ms
^C
--- hadoop102 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2010ms
rtt min/avg/max/mdev = 0.228/0.311/0.380/0.066 ms
[root@975d861c5b64 hdp]# ping hadoop103
PING hadoop103 (172.18.0.4) 56(84) bytes of data.
64 bytes from hadoop103.hadoops_docker0 (172.18.0.4): icmp_seq=1 ttl=64 time=0.678 ms
64 bytes from hadoop103.hadoops_docker0 (172.18.0.4): icmp_seq=2 ttl=64 time=0.337 ms
64 bytes from hadoop103.hadoops_docker0 (172.18.0.4): icmp_seq=3 ttl=64 time=0.310 ms
^C
--- hadoop103 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2043ms
rtt min/avg/max/mdev = 0.310/0.441/0.678/0.169 ms
下面就是枯燥乏味的hadoop搭建环节,考虑下面的操作写到脚本里,在镜像构建过程中直接写好,理论上是可以的。
集群搭建
第一步:配置免密登录
# 先切换用户
su hdfs
# 免密登录
ssh-keygen -t rsa
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
每个容器内执行一遍即可,用户名密码在 Dockerfile 构建镜像已经指定了
第二步:编写同步脚本
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if [ $pcount == 0 ]
then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for host in hadoop101 hadoop102 hadoop103
do
echo ------------------- $host --------------
rsync -rvl $pdir/$fname $user@$host:$pdir
done
第三步:配置环境变量
export JAVA_HOME=/opt/hdp/jdk
export HADOOP_HOME=/opt/hdp/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
同步各容器
[hdfs@458dba5266b6 hdp]$ shell/xsync ~/.bash_profile
第四部:配置hadoop
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hdp/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hdfs</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hdp/tmp/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hdp/tmp/dfs/dn</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop103:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop103:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
works
hadoop101
hadoop102
hadoop103
注:涉及文件的存储路径最好不要修改,因为在 compose 中做了数据卷的挂载,将 hadoop 的数据挂载到了宿主机上做了持久化处理
同步配置文件
[hdfs@458dba5266b6 hdp]$ shell/xsync hadoop/
第五步:格式化namenode
hdfs namenode -format
第六步:启动集群
start-dfs.sh
start-yarn.sh
因为宿主机映射了 hadoop101 的 9870 和 8088 端口。所以本地访问查看
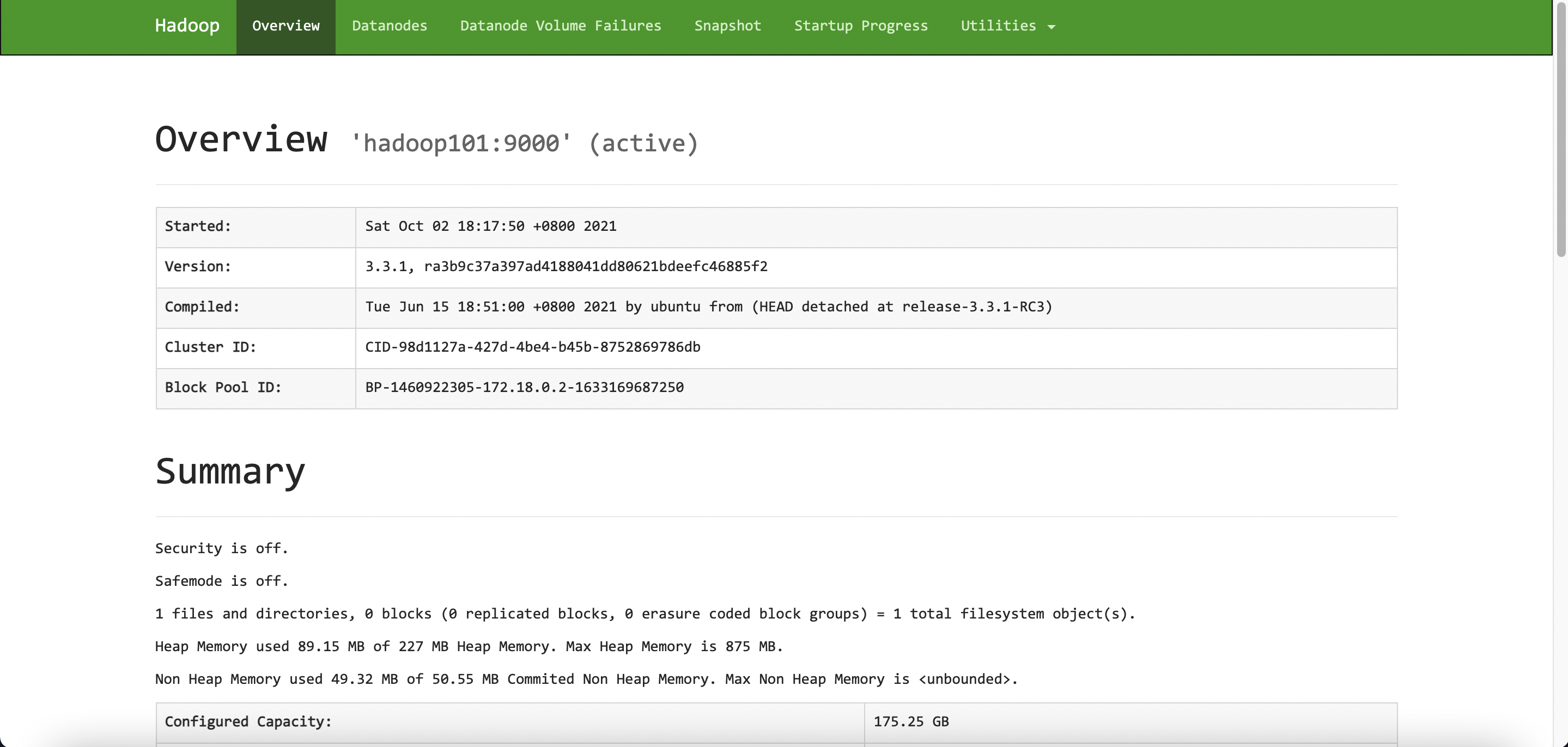
不足
虽然数据做了持久化,但是容器被删除后还需要重新配置,持久化的意义不是特别大,仅做测试使用,毕竟生产环境谁会用 docker 部署 hadoop 集群呢
评论区