


一、Hive 概述
1.1 Hive 是什么
- 由Facebook开源用于解决海量结构化日志的数据统计
- 基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并且提供类SQL的查询功能
- Hive仅仅是一个工具,本身不存储数据只提供一种管理方式,同时也不涉及分布式概念,就是个软件而已
- Hive本质就是MapReduce,将类SQL(HQL)转换成MapReduce程序
1.1.1 HQL转换MR流程
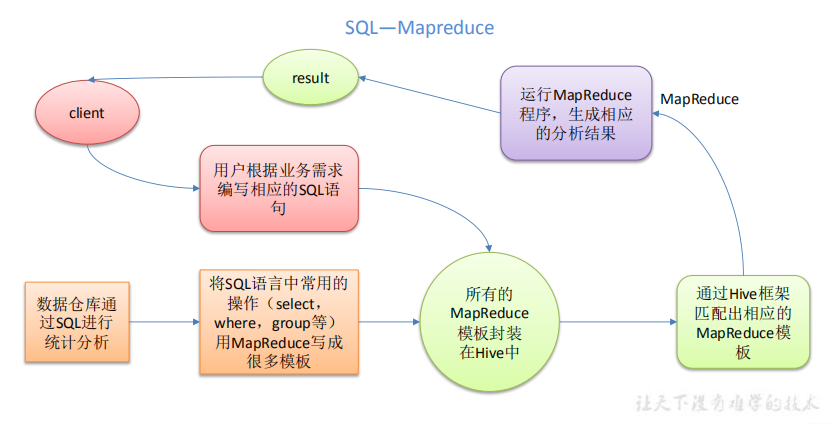
解释:
- Hive处理的数据存储在HDFS
- Hive分析数据底层默认实现是MapReduce[可以修改为spark]
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
- 执行的程序运行在yarn上
- Hive相当于Hadoop的一个客户端
- Hive不是分布式
1.2 Hive 优缺点
1.2.1 优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、易上手)
- 避免去写MR,减少开发人员学习成本
- Hive的延迟比较高(因为MR延迟高),因此Hive常用于数据分析
- Hive优势在于处理大数据(数据量少真不如MySQL等)
- Hive支持用户自定义函数,可以根据自己的去求实现自己的函数
1.2.2 缺点
- Hive的HQL表达能力有限(MR决定的)
- 迭代算法无法表达
- 不适用于数据挖掘
- Hive的效率比较低
- Hive自动生成的MR作业,通常情况不够智能
- Hive调优难(只能对资源,SQL层面调优,无法深入作业底层逻辑)
1.3 Hive 架构原理
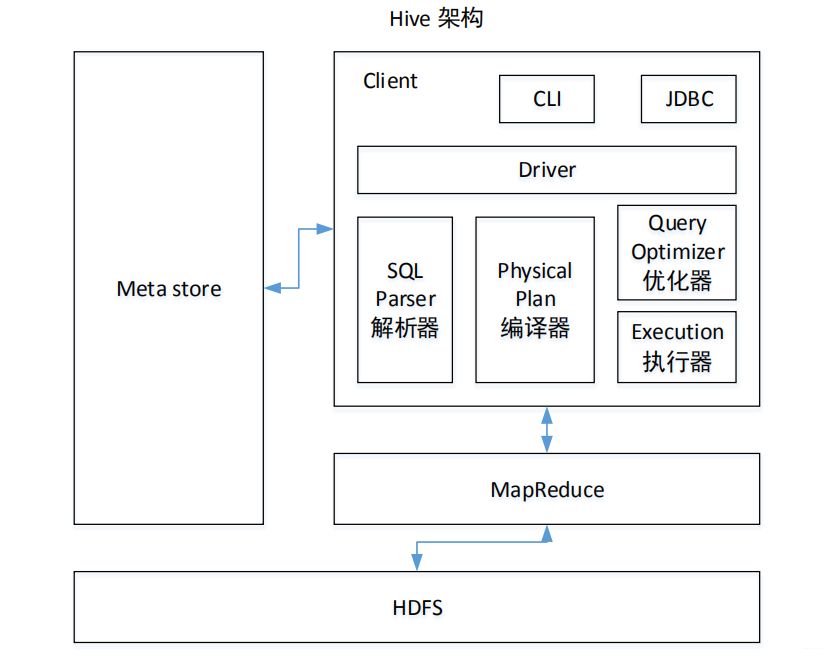
-
用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
-
元数据:Metastore
包括表名、表所属的数据库、表的拥有者、列/分区字段、表的类型、表数据所在的目录等(自带个derby数据库,推荐配置到MySQL)
-
底层存储:HDFS
使用HDFS进行存储,使用MapReduce计算
-
驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,并对语法树进行语法分析,如:SQL语法、表/字符是否存在
- 编译期(Physical Plan):将AST编译生成逻辑执行计划
- 优化器(Query Optimizer):对逻辑执行计划进行优化
- 执行器(Execution):把逻辑执行计算转换成运行的物理计划,即MR/Spark
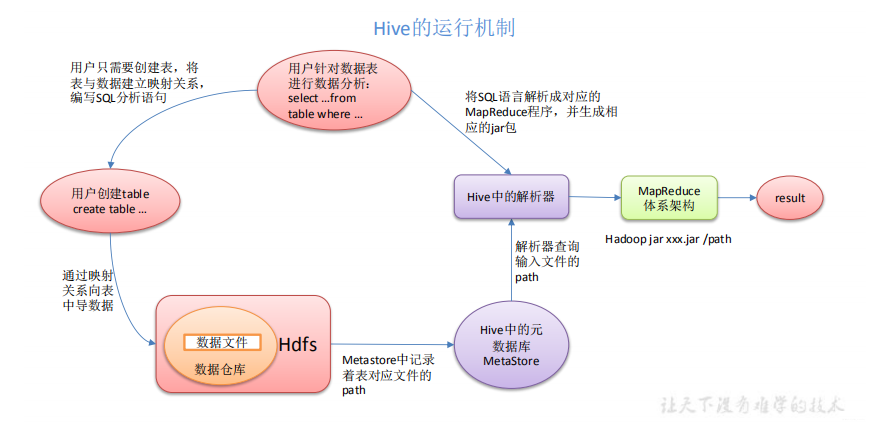
Hive通过给用户提供的一系列交互接口,接受到用户编写的SQL,使用自己的Driver结合MetaStore,将SQL指令翻译成MapReduce提交到Hadoop中执行,将执行结果输出到用户交互接口。
1.4 Hive 和传统数据库比较
Hive除了提供类似SQL语法外和传统数据库没有任何相似之处,Hive是站在数据仓库出发点而设计的。
1.4.1 数据存储位置
Hive是建立在Hadoop之上,所有的Hive数据都是存储在HDFS上;传统数据库将数据保存在本地文件系统中;因此Hive能够处理更大更多的数据
1.4.2 数据更新
Hive是针对数据仓库应用设计,因此数据一次写入多次读出,即Hive中不建议对数据进行改写操作,所有数据都是在加载的时候确定好;对于数据库通常需要进行频繁的增删查改
1.4.3 索引
Hive在加载数据过程不会对数据进行任何处理,因为数据量庞大建立索引并不划算,因此Hive访问数据中满足特定值需要暴力扫描真个数据,因此访问延迟高。由于MapReduce的引入,Hive可以并行访问数据,即便没有索引也可用于大数据量的访问;传统数据库通常针对一个或多个列建立索引,因此在访问数据是延迟低效率高,即Hive不适合实时数据分析
1.4.4 执行
Hive 的执行引擎为MR/Spark,传统数据库都有自己的执行引擎
1.4.5 可拓展性
由于Hadoop的高拓展性,因此Hive也具备很强的拓展性;传统数据库的拓展会受到一定的限制
1.4.6 数据规模
Hive可以利用MapReduce进行大规模数据的并行计算;传统数据库支持的数据规模较小
二、Hive 初步
2.1 Hive 安装
将元数据配置到MySQL中需要初始化,初始化命令(其余步骤可自行百度):
schematool -dbType mysql -initSchema
2.2 Hive 基本操作
-
启动hive
[root@master hive-3.2.1]# hive -
查看数据库
hive (hive)> show databases; OK database_name default hive Time taken: 0.02 seconds, Fetched: 2 row(s)hive自带一个default数据库,默认也是进这个数据库
-
切换数据库
hive (hive)> use hive; OK Time taken: 0.031 seconds -
创建表
hive (hive)> create table if not exists tbl_1(id int,name string); OK Time taken: 0.628 seconds和MySQL语法基本一致,只是Hive的数据类型和Java类似
-
查看表结构
hive (hive)> desc tbl_1; OK col_name data_type comment id int name string Time taken: 0.084 seconds, Fetched: 2 row(s) -------------------- 分隔符 ------------------- # 查看表的详细信息 hive (hive)> desc formatted tbl_1; OK col_name data_type comment # col_name data_type comment id int name string # Detailed Table Information Database: hive OwnerType: USER Owner: root CreateTime: Wed Aug 26 19:55:58 CST 2020 LastAccessTime: UNKNOWN Retention: 0 Location: hdfs://master:9000/user/hive/warehouse/hive.db/tbl_1 Table Type: MANAGED_TABLE Table Parameters: COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"id\":\"true\",\"name\":\"true\"}} bucketing_version 2 numFiles 0 numRows 0 rawDataSize 0 totalSize 0 transient_lastDdlTime 1598442958 # Storage Information SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.TextInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Compressed: No Num Buckets: -1 Bucket Columns: [] Sort Columns: [] Storage Desc Params: serialization.format 1 Time taken: 0.154 seconds, Fetched: 32 row(s) -
插入数据(不要用,不要用,不要用)
hive (hive)> insert into tbl_1 values(1,'zhangsan'); ... ... ... Time taken: 84.754 seconds谁用谁知道
-
查询数据
hive (hive)> select * from tbl_1; OK tbl_1.id tbl_1.name 1 zhangsan Time taken: 0.214 seconds, Fetched: 1 row(s) -
退出hive
hive (hive)> quit; -
执行hdfs shell
hive (hive)> dfs -ls /; Found 3 items drwxr-xr-x - root supergroup 0 2020-07-21 15:57 /HBase drwx-wx-wx - root supergroup 0 2020-07-21 18:27 /tmp drwxrwxrwx - root supergroup 0 2020-07-21 18:00 /user -
执行linux shell
hive (hive)> !pwd; /usr/local/soft/hive-3.2.1
2.3 Hive 常规操作
hive (hive)> insert into tbl_1 values(1,'zhangsan');
...
...
...
Time taken: 84.754 seconds
插入一条数据84秒,显然不现实...为此Hive插入数据将采用最暴力最直接的方式,只需要将数据文件放到hdfs制定的路径即可。但也不是什么数据都可以,需要在创建表时指定分隔符。
hive (hive)> create table if not exists tbl_2(id int,name string)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.118 seconds
准备数据
[root@master data]# cat student.txt
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
5 tianqi
[root@master data]# pwd
/usr/local/soft/hive-3.2.1/data
2.3.1 hive 插入数据一
加载本地数据到hive
hive (hive)> load data local inpath '/usr/local/soft/hive-3.2.1/data/student.txt' into table tbl_2;
Loading data to table hive.tbl_2
OK
Time taken: 0.311 seconds
hive (hive)> select * from tbl_2;
OK
tbl_2.id tbl_2.name
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
5 tianqi
Time taken: 0.192 seconds, Fetched: 5 row(s)
评价:方便、推荐使用
2.3.2 hive 插入数据二
hive管理的数据是放在hdfs,可以再配置文件指定存储路径,可以进入指定路径查看,也可以通过desc formatted 表名看到该表的存储路径
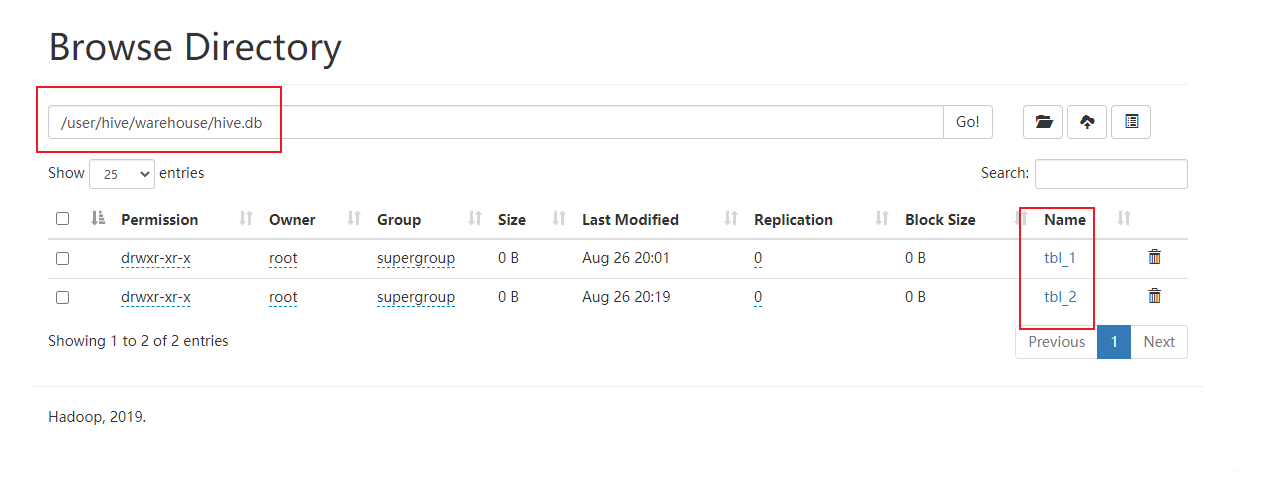
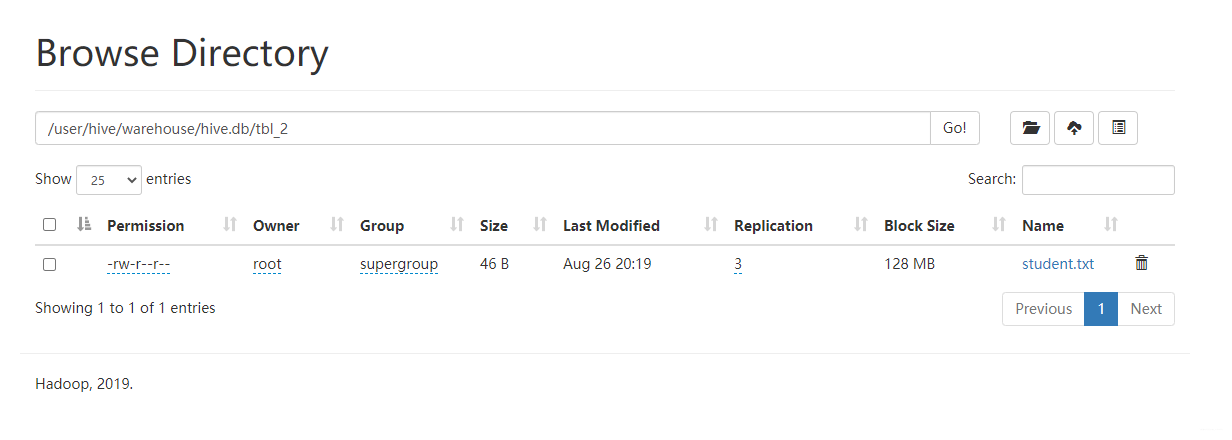
- hive在hdfs存储的根路径是在/.../warehouse/下
- 一个数据库对应一个文件夹,命名方式为数据库名.db(默认数据库除外)
- 每张表也对应一个文件夹,命名方式为表名
- 数据文件直接放在表对应的文件夹下,因此通过load方式其实底层调用的是
hadoop fs -put - 默认数据库下的表直接放在warehouse下命名方式不变
基于上述规律可以有第二种插入方式,直接通过hadoop的shell将文件put到指定的hdfs路径下即可
[root@master data]# hadoop fs -put student.txt /user/hive/warehouse/hive.db/tbl_2/student_1.txt
hive (hive)> select * from tbl_2;
OK
tbl_2.id tbl_2.name
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
5 tianqi
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
5 tianqi
Time taken: 0.396 seconds, Fetched: 10 row(s)
总结:也可以用,但是必须知道表在hdfs上的路径,所以这种方式路就走窄了呀!
看过hive数据库、表、数据在hdfs上的存储结构后,尝试再次加载一次数据,这次通过load加载hdfs上的数据
hive (hive)> load data inpath '/student.txt' into table tbl_2;
Loading data to table hive.tbl_2
OK
Time taken: 0.683 seconds
load方式加载hdfs文件不需要加local(很显然),这时候再次查看hdfs信息,此时原数据将会被删除(其实就是hadoop fs -mv)

对于多次加载相同数据文件情况,hive会将数据文件重命名后上传到hdfs指定路径,重命名格式:原文件名_copy_n.txt;和windows下同名文件处理类似。
2.4 Hive 数据类型
2.4.1 基本数据类型
| Hive数据类型 | Java数据类型 | 长度 |
|---|---|---|
| tinyint | byte | 1byte |
| smalint | short | 2byte |
| int | int | 4byte |
| bigint | long | 8byte |
| boolean | boolean | true/false |
| float | float | 单精度 |
| double | double | 双精度 |
| string | String | 字符串 |
| timestamp | ||
| bigary |
常用的基本数据类型有int、bigint、double、string且不区分大小写;boolean一般使用0/1代替以减少存储量;string使用最多,一般都是处理日志,理论上可以存储2G数据(一行)。
2.4.2 集合数据类型
| 数据类型 | 描述 | 语法实例 |
|---|---|---|
| struct | 结构体,复杂无关系数据 | struct<k1:v,k2:v> |
| map | 字典,键值对元组集合 | map<k,v> |
| array | 数组,同一类型集合 | array<v> |
struct和map区别在于map只能存储一组一组的k-v对,且一个map中的k不能相同,struct可以存储很对组相同key不同value的数据结构,即map中每组数据的key都不相同,struct中每组数据对应位置的key都是一样的;集合数据类型允许任意层次的嵌套。
2.4.3 类型转换
Hive支持类似java的数据类型转换
隐式转换
- tinyint -> smalint -> int -> bigint -> float -> double
- string类型只有是数字才可以转换
- boolean不能转换成任意类型
强制类型转换
hive (hive)> select cast('1' as int);
OK
_c0
1
Time taken: 0.937 seconds, Fetched: 1 row(s)
hive (hive)> select cast('a' as int);
OK
_c0
NULL
Time taken: 0.184 seconds, Fetched: 1 row(s)
好吧,看不出什么效果
2.4.4 测试集合数据类型
需要存储如下格式数据(json)
{
"name": "陈小春",
"friends": ["郑伊健" , "谢天华"], //列表Array
"children": { //键值Map
"jasper": 3 ,
"baby": 1 ,
}
"address": { //结构Struct
"street": "皇后大道" ,
"city": "香港"
}
}
{
"name": "刘烨",
"friends": ["章子怡" , "孙俪"],
"children": {
"诺一": 8 ,
"霓娜": 6 ,
}
"address": {
"street": "长安街" ,
"city": "北京"
}
}
将一条数据转换成一行数据,去除没必要的数据,在一条数据中,字段之间用','隔开,集合元素之间用'_'隔开,map的kv用':'隔开,因此可以转换成如下格式
陈小春,郑伊健_谢天华,jasper:3_baby:1,皇后大道_香港
刘烨,章子怡_孙俪,诺一:8_霓娜:6,长安街_北京
针对上述数据创建如下表
hive (hive)> create table tbl_3(name string,friends array<string>,childress map<string,int>,address struct<street:string,city:string>)
> row format delimited fields terminated by ','
> collection items terminated by '_'
> map keys terminated by ':';
OK
Time taken: 0.124 seconds
解释:
row format delimited fields terminated by ','设置字段分割符collection items terminated by '_'设置集合元素分割符map keys terminated by ':'设置map键值对分隔符lines terminated by '\n'设置行分隔符,默认\n
导入数据测试
hive (hive)> load data local inpath '/usr/local/soft/hive-3.2.1/data/test_collection' into table tbl_3;
Loading data to table hive.tbl_3
OK
Time taken: 0.281 seconds
hive (hive)> select * from tbl_3;
OK
tbl_3.name tbl_3.friends tbl_3.childress tbl_3.address
陈小春 ["郑伊健","谢天华"] {"jasper":3,"baby":1} {"street":"皇后大道","city":"香港"}
刘烨 ["章子怡","孙俪"] {"诺一":8,"霓娜":6} {"street":"长安街","city":"北京"}
Time taken: 0.176 seconds, Fetched: 2 row(s)
hive (hive)> select name,friends[0],childress['baby'],address.street from tbl_3;
OK
name _c1 _c2 street
陈小春 郑伊健 1 皇后大道
刘烨 章子怡 NULL 长安街
Time taken: 0.222 seconds, Fetched: 2 row(s)
三、DDL 数据定义语言
3.1 数据库操作
3.1.1 创建数据库
1.方式一
创建一个数据库,默认存储在hdfs中/user/hive/warehouse/*.db
hive (default)> create database test;
OK
Time taken: 0.827 seconds
若数据库已经存在会报Execution Error,推荐使用方法二
2.方式二
避免创建的数据库已经存在的错误,使用if not exists写法
hive (default)> create database if not exists hive;
OK
Time taken: 0.029 seconds
3.方式三
指定数据库在hdfs的存储位置
create database test location '/hive/test.db';
OK
Time taken: 0.097 seconds
3.1.2 查询数据库
1.显示数据库
显示数据库
hive (hive)> show databases;
OK
database_name
default
hive
Time taken: 0.03 seconds, Fetched: 2 row(s)
过滤显示查询的数据库
hive (hive)> show databases like 'h*';
OK
database_name
hive
Time taken: 0.022 seconds, Fetched: 1 row(s)
2.查看数据库详情
显示数据库信息
hive (hive)> desc database hive;
OK
db_name comment location owner_name owner_type parameters
hive hive test hdfs://master:9000/user/hive/warehouse/hive.db root USER
Time taken: 0.049 seconds, Fetched: 1 row(s)
显示数据库详细信息
hive (hive)> desc database extended hive;
OK
db_name comment location owner_name owner_type parameters
hive hive test hdfs://master:9000/user/hive/warehouse/hive.db root USER {creator=wj}
Time taken: 0.03 seconds, Fetched: 1 row(s)
{creator=wj}为自定义属性,可作为注释使用
3.1.3 修改数据库
已经创建的数据库其信息都是不可以修改的,包括数据库名和数据库所在的目录位置等,这里修改数据库指的是修改数据库的dbproperties的键值对
hive (test)> alter database test set dbproperties('creator'='wj');
OK
Time taken: 0.234 seconds
3.1.4 删除数据库
1.删除空数据库
hive (hive)> drop database d1;
OK
Time taken: 0.435 seconds
2.强制删除数据库
对于非空数据库,上述命令无法删除
hive (d1)> drop database d1;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database d1 is not empty. One or more tables exist.)
因此可以使用cascade进行强制删除
hive (d1)> drop database d1 cascade;
OK
Time taken: 0.231 seconds
3.2 表操作
3.2.1 创建表
标准语句
create [external] table [if not exists] table_name
[(col_name data_type [comment col_comment],...)]
[comment table_comment]
[partitioned by (col_name data_type [col_name data_type],...)]
[clustered by (col_name,col_name)]
[row format ...]
[collection items ...]
[map keys ...]
[location hdfs_path]
3.2.2 修改表
1.表的重命名
hive (hive)> alter table emp rename to tbl_emp;
OK
Time taken: 0.215 seconds
hive (hive)> show tables;
OK
tab_name
score
student
tbl_1
tbl_2
tbl_3
tbl_4
tbl_emp
Time taken: 0.025 seconds, Fetched: 7 row(s)
2.添加列
hive (hive)> alter table tbl_emp add columns(emp_id int);
OK
Time taken: 0.147 seconds
3.修改列
包括修改列名,列属性
hive (hive)> alter table tbl_emp change emp_id c_emp_id string;
OK
Time taken: 0.234 seconds
替换列
hive (hive)> alter table tbl_emp replace columns(s_id string,c_id string,c_grade string);
OK
Time taken: 0.157 seconds
3.2.3 删除表
hive (hive)> drop table tbl_emp;
OK
Time taken: 0.227 seconds
3.2.4 内/外部表
1.内部表
又称管理表(MANAGED_TABLE),因为对应的表叫外部表(EXTERNAL_TABLE)所以喜欢叫它内部表,创建表默认是内部表,删除表时元数据和hdfs内数据均会被删除
2.外部表
与内部表对立,删除外部表时仅删除元数据hdfs内的数据不会被删除,再次创建同名表数据会"恢复",即hive并非认为其完全拥有此表,创建外部表命令如下:
hive (hive)> create external table tbl_5(id int,name string);
OK
Time taken: 0.183 seconds
hive (hive)> desc formatted tbl_5;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: hive
OwnerType: USER
Owner: root
CreateTime: Thu Aug 27 19:57:54 CST 2020
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://master:9000/user/hive/warehouse/hive.db/tbl_5
Table Type: EXTERNAL_TABLE
3.内外部表转换
内部表 -> 外部表
hive (hive)> alter table tbl_4 set tblproperties('EXTERNAL'='TRUE');
OK
Time taken: 0.13 seconds
外部表 -> 内部表
hive (hive)> alter table tbl_4 set tblproperties('EXTERNAL'='FALSE');
OK
Time taken: 0.13 seconds
4.应用场景
在实际生产环境中,涉及到共享数据一定要使用外部表,防止误操作导致的数据丢失,对于个人使用,数据分析的中间表可以使用内部表,方便管理。
3.2.5 分区表
假设Hive的数仓存储了一年的数据,现在需要查找出某一天的数据,当使用where语句时,Hive会对该表(文件夹)下所有数据进行全表扫描,从而导致查询效率低;因此引入分区表概念来优化查询(有谓词下推的意思)
1.创建分区表
hive (hive)> create table tbl_6(id int,name string) partitioned by(month string) row format delimited fields terminated by '\t';
OK
Time taken: 0.106 seconds
在创建表语法后加partitioned by (col_name data_type)
2.导入数据
需要注意的是当创建的是分区表时加载数据需要添加上分区信息否则会保存(因为hive不知道要把数据put到哪个文件夹)
hive (hive)> load data local inpath '/usr/local/soft/hive-3.2.1/data/test_partition' into table tbl_6 partition(month='2020-08');
Loading data to table hive.tbl_6 partition (month='2020-08')
OK
Time taken: 0.782 seconds
hive (hive)> select * from tbl_6;
OK
tbl_6.id tbl_6.name tbl_6.month
1 tzhangsan 2020-08
2 tlisi 2020-08
3 twangwu 2020-08
Time taken: 0.141 seconds, Fetched: 3 row(s)
可以发现分区字段会自动加到表的数据中(原始数据文件不会被添加,hive自己做的处理,在读取数据的时候自动添加分区字段数据),添加多个分区后
hive (hive)> load data local inpath '/usr/local/soft/hive-3.2.1/data/test_partition' into table tbl_6 partition(month='2020-09');
Loading data to table hive.tbl_6 partition (month='2020-09')
OK
Time taken: 0.634 seconds
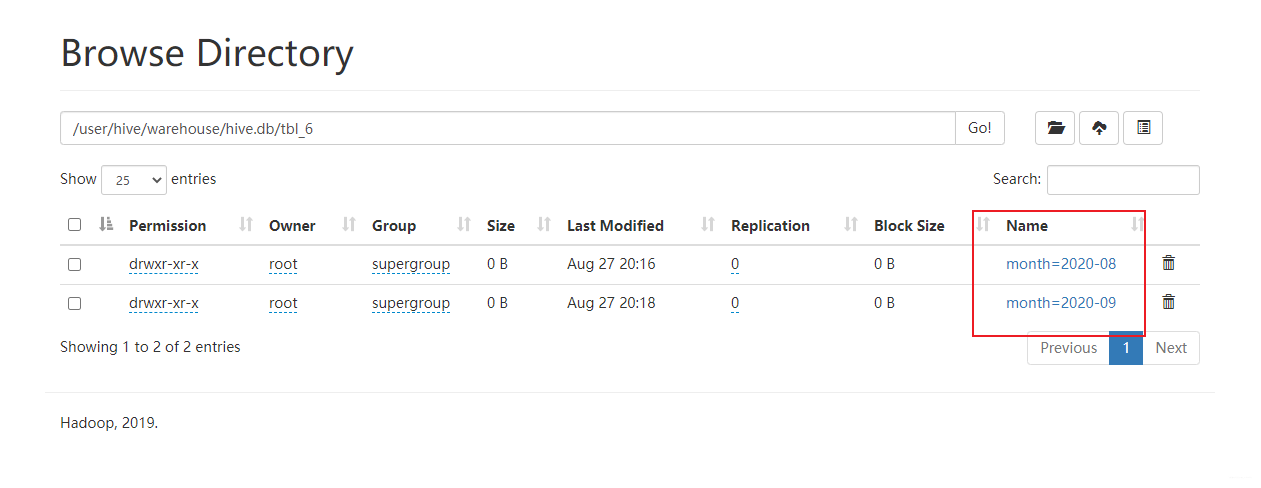
因此分区的本质就是分文件夹,文件夹以分区名命名,不同分区的数据被放在不同文件夹下,这样的好处是当执行where查询时,hive会直接去指定的分区文件夹下扫描数据,效率将大幅提高。
3.操作分区
添加分区(本质就是创建文件夹)
hive (hive)> alter table tbl_6 add partition(month='2020-10');
OK
Time taken: 0.169 seconds
删除分区(本质就是删除文件夹)
hive (hive)> alter table tbl_6 drop partition(month='2020-10');
OK
Time taken: 0.269 seconds
创建二级分区
hive (hive)> create table tbl_6(id int,name string) partitioned by(month string,day string)
row format delimited fields terminated by '\t';
OK
Time taken: 0.106 seconds
理论、操作都一样,多级分区上限没有限制(适可而止),结合上面知识,向分区表插入数据也可以直接put文件到指定路径
查看分区
hive (hive)> show partitions tbl_6;
OK
partition
month=2020-08
month=2020-09
month=2020-10
Time taken: 0.127 seconds, Fetched: 3 row(s)
四、DML 数据操作语言
4.1 数据导入
4.1.1 向表中转载数据(load)
1.标准语法
load data [local] inpath path [overwrite] into table table_name [partition(p1=v1,...)]
| args | explain |
|---|---|
| load data | 加载数据 |
| local | 加载本地文件,不加默认加载hdfs |
| inpath path | 加载数据文件的路径 |
| overwrite | 覆盖已有数据 |
| into table | 追加数据 |
| table_name | 具体的表名 |
| partition | 加载数据到指定分区 |
2.操作案例
见2.3 Hive常规操作
4.1.2 insert
insert插入分区表,真不推荐使用这个
hive (hive)> insert into tbl_6 partition(month='2020-07') values(4,'zhaoliu');
基本插入模式,根据查询的结果插入数据
hive (hive)> insert into table tbl_5 select * from tbl_1;
hive (hive)> insert overwrite table tbl_5 select * from tbl_1;
4.1.3 as select
hive (hive)> create table tbl_7 as select * from tbl_6;
4.1.4 export
只能搭配import使用,见下面的inport用法
4.2 数据导出
4.2.1 insert
hive (hive)> insert overwrite local directory '/tmp/hive' select * from tbl_6;
[root@master data]# cd /tmp/hive/
[root@master hive]# ll
总用量 4
-rw-r--r--. 1 root root 108 8月 27 20:55 000000_0
[root@master hive]# cat 000000_0
1tzhangsan2020-08
2tlisi2020-08
3twangwu2020-08
1tzhangsan2020-09
2tlisi2020-09
3twangwu2020-09
导出的数据会把导出路径下的所有文件进行覆盖,一定要写一个不存在的路径。但cat文件发现数据不友好,因此需要格式化导出数据
hive (hive)> insert overwrite local directory '/tmp/hive' row format delimited fields terminated by '\t' select * from tbl_6;
[root@master hive]# cat 000000_0
1 tzhangsan 2020-08
2 tlisi 2020-08
3 twangwu 2020-08
1 tzhangsan 2020-09
2 tlisi 2020-09
3 twangwu 2020-09
4.2.2 hive shell
不常用hive -e 'sql' > file 利用linux的重定向
4.2.3 export/import
先导出后导入
hive (hive)> export table tbl_1 to '/hive';
OK
Time taken: 0.117 seconds
hive (hive)> truncate table tbl_1;
OK
Time taken: 0.149 seconds
hive (hive)> select * from tbl_1;
OK
tbl_1.id tbl_1.name
Time taken: 0.141 seconds
hive (hive)> import table tbl_1 from '/hive';
Copying data from hdfs://master:9000/hive/data
Copying file: hdfs://master:9000/hive/data/000000_0
Loading data to table hive.tbl_1
OK
Time taken: 0.197 seconds
五、DQL 数据查询语言
5.1 本地模式
对于数据量小,学习一些操作命令可以将hive的运行模式设置成本地模式。对于小数据集可以明显的缩短时间,通过如下配置
//开启本地模式
set hive.exec.mode.local.auto=true;
//设置local mr最大输入数据量,当数据量小于这个值(默认128M)时使用local mr
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr最大输入文件数,当文件数小于这个值(默认4)时使用local mr
set hive.exec.mode.local.auto.input.files.max=10;
关闭本地模式
set hive.exec.mode.local.auto=true;
5.2 基本查询
和mysql语法一致,基本语法
select ... from table_name
5.2.1 全表和特定字段查询
1.全表查询
select * from student;
2.特定字段查询
select st_id,st_name from student;
总结:
- HQL语法不区分大小写
- HQL可以写一行也可以写多行
- 关键字不能被缩写或换行
- 字句一般分行写
- 多使用缩进提高代码可读性
5.2.2 列起别名
基本语法,as可以省略
select st_id as id,st_name name from student;
5.2.3 算术运算符
| 运算符 | 描述 |
|---|---|
| A+B | A和B相加 |
| A-B | A减去B |
| A*B | A和B相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
5.2.4 limit 语句
基本语法
select st_id,st_name from student limit 2;
5.2.5 where 语句
和mysql语法一致,基本语法
select * from student where st_age > 20;
1.比较运算符
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A!=B | 基本数据类型 | 如果A不等于B,则返回TRUE,反之返回FALSE |
| A<B | 基本数据类型 | 如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B | 基本数据类型 | 如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | 如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | 如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 等于数值1、数值2,返回TRUE |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:'x%'表示A必须以字母'x'开头,'%x'表示A必须以字母'x'结尾,而'%x%'表示A包含有字母'x',可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
2.逻辑运算符
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
5.4 分组查询
和mysql语法一致
5.4.1 group by
group by语句通常会和聚合函数(count、max、min、avg、sum)一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。同样select的字段必须出现在group by后或者聚合函数里
select st_dept,count(*) from student group by st_dept;
5.4.2 having
用法和mysql一样
having和where区别:
- where对表中的列发挥作用,having对查询结果的列发挥作用
- where后面不能接聚合函数,having后面可以接聚合函数
- having只能用在group by后面
5.5 连接查询
5.5.1 等值连接
Hive只支持等值连接,不支持非等值连接,其用法可mysql语法一致
5.5.2 总结
内连接、左连接、右连接、满连接、多表连接、笛卡尔积都和mysql语法一致
5.6 排序
hive的排序将会和mysql有很大的区别,为了更好的展现hive的排序,需要了解hive配置
hive (hive)> set mapreduce.job.reduces;
mapreduce.job.reduces=-1
设置reduce个数,默认-1会根据sql、数据量等动态规划reduce个数,通过设置大于0的数来规定reduce个数
5.6.1 全局排序
就是MapReduce的全局排序,在hive中体现为order by对应一个reduce,因为站在MapReduce角度全局排序必须输出一个文件因此必须只有一个reduce。
1.使用
select * from student order by age;
同样默认升序(asc),可以按降序排序(desc)
2.细节
当使用order by排序是会启动一个reduce,那么当手动设置reduce个数最终会启动几个reduce呢?
//设置reduce个数为3
hive (test)> set mapreduce.job.reduces=3;
hive (test)> select * from student order by age;
Query ID = root_20200829092604_3b647fd2-3d10-46ac-b498-0f34941dee6a
Total jobs = 1
Launching Job 1 out of 1
...
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
提交一个job,启动一个reduce,发现无论设置多少个reduce个数全局排序就只会启动一个redcue。
3.补充
支持别名排序
select stu_id id from student order by id;
支持多个字段排序
hive (test)> select * from student order by age,stu_id;
5.6.2 局部排序
对应MapReduce多个reduce,每个reduce局部有序,不一定保证全局有序,hive中通过sort by实现。
设置reduce个数为三
set mapreduce.job.reduces=3;
具体实现
hive (test)> select * from emp sort by deptno desc;
...
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
结果如下
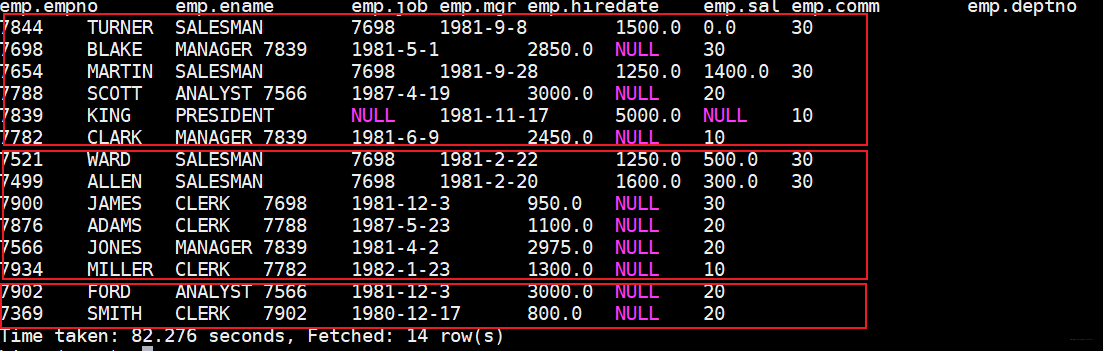
可以大致看出是分三个区(三个reduce即对应三个分区),当然可以将结果输出到文件中可以发现也是三个文件
insert overwrite local directory '/tmp/hive'
select * from emp sort by deptno desc;
但问题是在MapReduce中分区默认为HashPartitioner根据key的hash和reduce个数取余,那么hive是怎么实现分区呢?按照哪(几)个字段实现分区?从官方文档可以找到答案,按照上述没有指定分区的hql来说hive通过随机值的形式分区。

为什么?当我们没有指定字段分区时,若hive还按照字段进行分区万一导致数据倾斜问题该找谁呢?所以hive通过随机加载的形式尽可能减少数据倾斜的发生。
5.6.3 分区排序
distribute by:类似MapReduce的partition,通过指定某个字段进行分区(HashPartitioner)结合sort by从而达到分区内有序
按照部门id分区,分区内按照薪资升序排序
hive (test)> select * from emp distribute by deptno sort by sal;
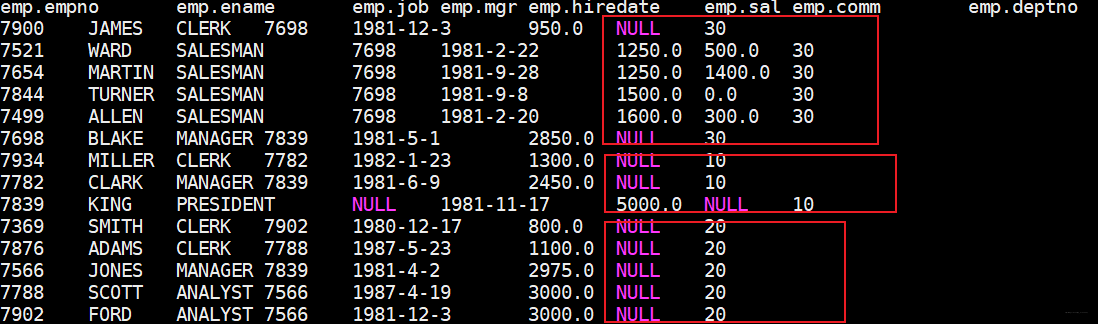
5.6.4 cluster by
当distribute by和sort by字段一致时可以使用cluster by代替,因此distribute by兼顾分区和排序两个功能,但是cluster by排序只支持降序排序,不能指定desc或asc一句话
cluster by col <=> distribute by col sort by col
那么有人就问了对一个字段分区又排序的意义可在?当我们数据有很多是,分区数少但该字段类型有很多种,因此就会有很多字段进入同一个分区,在对同一个分区按照该字段排序。
5.6.5 总结
| 语法 | 总结 |
|---|---|
| group by | 对字段进行分区,将相同字段再进行分区,后面会接聚合操作 |
| distribute by | 仅对字段进行分区 |
| order by | 全局排序,只会起一个reduce |
| sort by | 局部排序,若设置reduce个数为1则和order by一样 |
5.7 分桶表
请区别于分区表(我觉得这两张表的名字起得不太友好),学完发现分区表仅是数据分开存储,分桶表则对应MR的分区,将数据文件分开存储;注意分区表针对的是数据的存储路径,将一个个文件分文件夹存储,分桶表则是对一个个文件进行分区,一个分区对应一个文件即对一份数据文件进行了拆分。
分区提供一个数据隔离和优化查询的便利方式,但不是所有的数据集都能形成比较好的分区;分桶则是将数据集拆分成更容易管理的若干部分的另一种手段。
5.7.1 创建分桶表
create table stu_buck(id int, name string)
clustered by(id) into 4 buckets
row format delimited fields terminated by '\t';
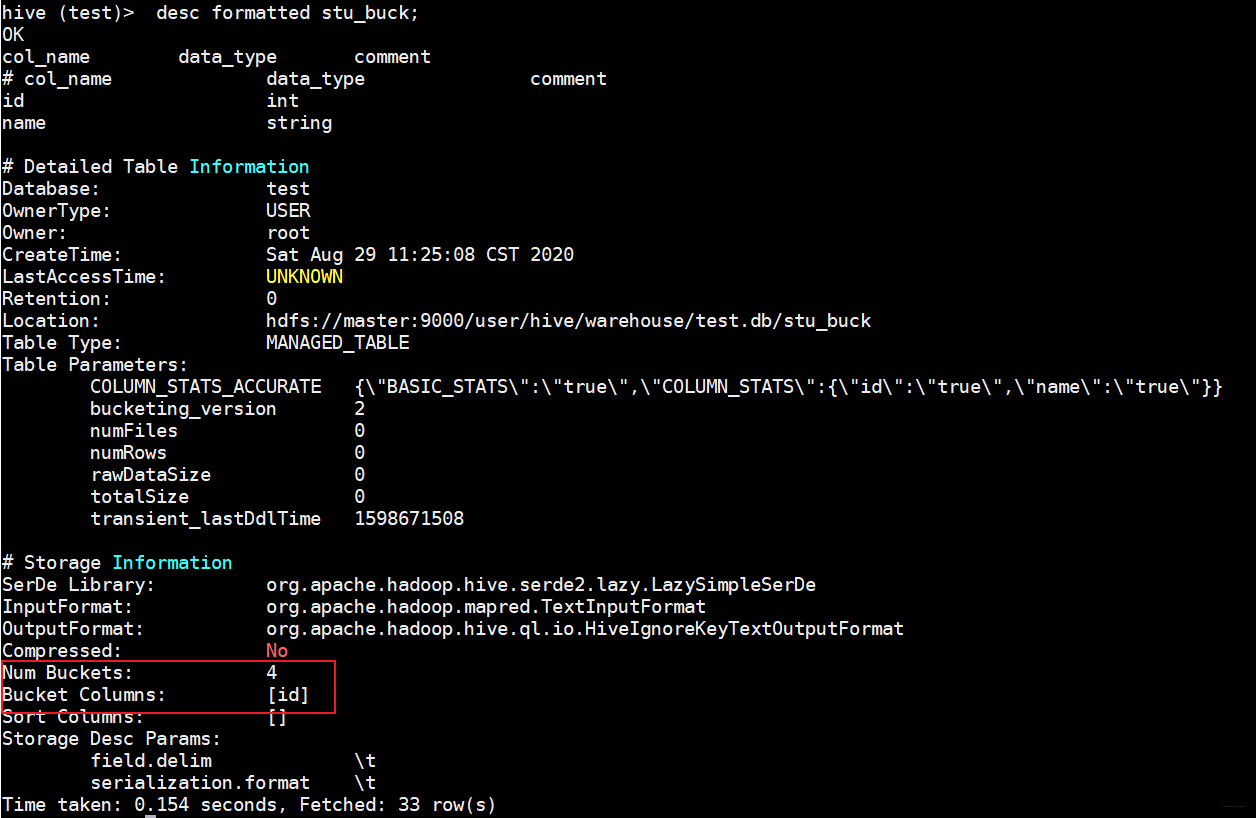
分桶表使用clustered by(注意和分区排序区分开)且字段要是表中的字段(分区字段不能是表中字段)且分4个桶
查看表结构
hive (test)> desc formatted stu_buck;
加载数据到分桶表中,加载之前要确保mapreduce.job.reduces=-1这样hive会根据分桶表中的分桶数自动创建对应数量的reduce数
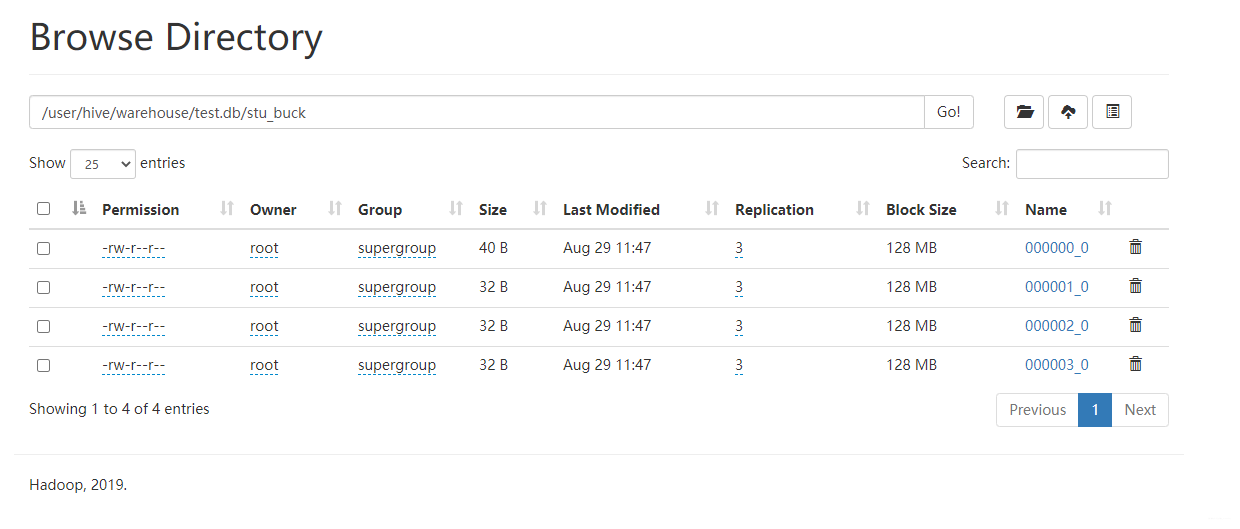
大致可以看出按照id的hash值取余
看了很多的文章发现创建分桶表步骤很多,首先开启分桶开关之类的,但发现在hive 3.1.2版本这个配置已经不存在了
hive (test)> set hive.enforce.bucketing;
hive.enforce.bucketing is undefined
通过阅读官方文档发现hive 2.x直接load数据即可,不需要通过创建中间表,再通过中间表走MR插入到分桶表的形式来加载数据了

5.7.2 分桶表应用
对于分桶表主要用于抽样查询中,在一个庞大的数据集中往往需要一个代表性查询结果而不是全部查询结果,因此hive通过抽样语句来实现抽样查询
tablesample(bucket x out of y on col)
col:为分桶字段
x:表示从哪个桶开始抽取
y:必须是分桶数的倍数或者因子,决定抽样的比例。如假设分桶数为4,当y=2时,抽取(4/2)=2个桶的数据;当y=4时,抽取(4/4)=1个桶的数据;当y=8时,抽取(4/8)=1/2个桶的数据
假设分桶数z:z/y>1,则最终取x,x+z/y+z/y*2...
tablesample(bucket 1 out of 2 on id)
即从第一个桶开始抽,抽取两个桶的数据,也就是抽取1,3两个桶中的数据
因此tablesample要求x <= y,因为抽取的最后一个为
x+(z/y-1)*y => x+z-y <= z => x <= y
若x > y会报FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
六、函数
hive的函数和mysql一样分为系统内置函数和用户自定义函数,只是自定义函数和mysql将会有巨大差别
查看系统内置函数
hive (test)> show functions;
查看内置函数用法
hive (test)> desc function upper;
查看内置函数详细用法
hive (test)> desc function extended upper;
6.1 系统内置函数
下面列举常用的内置函数,主要介绍和mysql不同的部分(带*的)[一共216个]
| function | explanation |
|---|---|
| round | 四舍五入 |
| ceil | 向上取整 |
| floor | 向下取整 |
| rand | 取0-1随机数 |
| lower | 转小写 |
| upper | 转大写 |
| length | 返回字符串长度 |
| concat | 字符串拼接 |
| concat_ws | 指定分隔符拼接 |
| collect_set | 合并字段* |
| substr | 求子串 |
| trim | 前后去空格 |
| split | 字符串分割 |
| to_date | 字符串转日期 |
| year、month... | 从日期中提取年月日 |
| from_unixtime | 时间戳转日期* |
| unix_timestamp | 日期转时间戳* |
| case...when... | 条件函数 |
| if | 判断函数 |
| count | 求个数(聚合) |
| sum | 求总和(聚合) |
| min | 求最小值(聚合) |
| max | 求最大值(聚合) |
| avg | 求平均值(聚合) |
| explode | 膨胀函数* |
| lateral view | 拓展explode* |
| over | 开窗函数 |
6.1.1 collect_set
通常搭配group by使用,将每个组的数据收集(collect)起来封装成一个集合(set)。
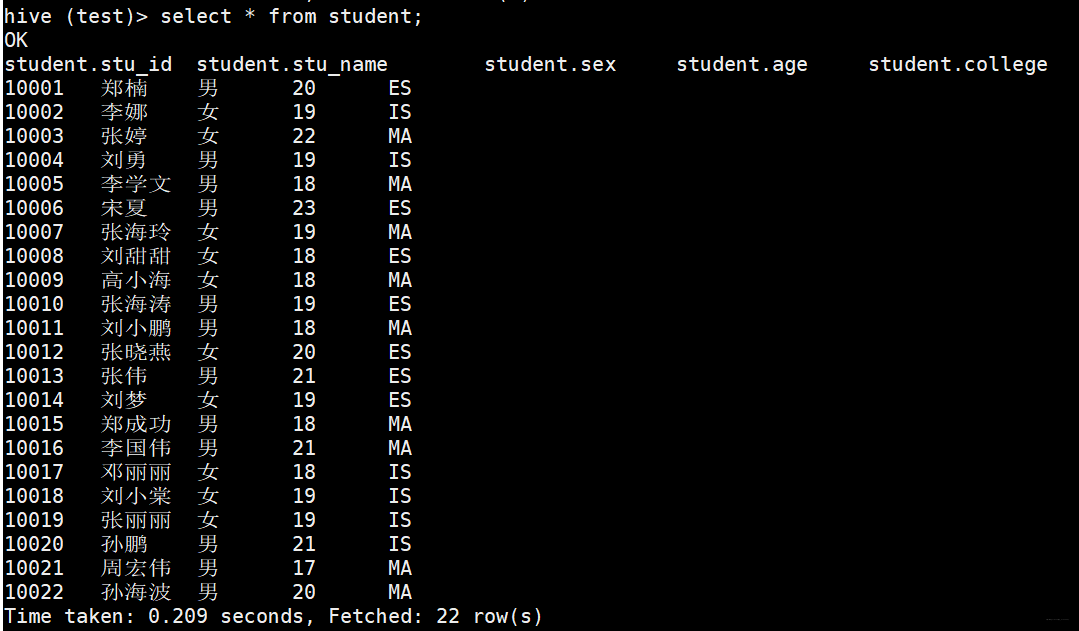
具体用法
hive (test)> select college,collect_set(stu_name) from student group by college;
...
mr
...
ES ["郑楠","宋夏","刘甜甜","张海涛","张晓燕","张伟","刘梦"]
IS ["李娜","刘勇","邓丽丽","刘小棠","张丽丽","孙鹏"]
MA ["张婷","李学文","张海玲","高小海","刘小鹏","郑成功","李国伟","周宏伟","孙海波"]
按学院分组,打印出每个学员信息和每个学院都有哪些学生,使用collect_set函数将同学院学生封装集合
6.1.2 日期相关
日期转时间戳 unix_timestamp
hive (test)> select unix_timestamp('2020-08-29 14:14:00','yyyy-MM-dd HH:mm:ss');
OK
_c0
1598710440
Time taken: 0.24 seconds, Fetched: 1 row(s)
时间戳转日期 from_unixtime
hive (test)> select from_unixtime(1598710440,'yyyy-MM-dd HH:mm:ss');
OK
_c0
2020-08-29 14:14:00
Time taken: 0.146 seconds, Fetched: 1 row(s)
6.1.3 膨胀函数
1.explode
将一行数据转换成列,在hive中只能用于array和map数据类型
用于array数据类型
hive (hive)> select * from tbl_3;
OK
tbl_3.name tbl_3.friends tbl_3.childress tbl_3.address
陈小春 ["郑伊健","谢天华"] {"jasper":3,"baby":1} {"street":"皇后大道","city":"香港"}
刘烨 ["章子怡","孙俪"] {"诺一":8,"霓娜":6} {"street":"长安街","city":"北京"}
Time taken: 0.153 seconds, Fetched: 2 row(s)
hive (hive)> select explode(friends) as friend from tbl_3;
OK
friend
郑伊健
谢天华
章子怡
孙俪
Time taken: 0.156 seconds, Fetched: 4 row(s)
用于map数据类型
hive (hive)> select explode(childress) as (name,age) from tbl_3;
OK
name age
jasper 3
baby 1
诺一 8
霓娜 6
Time taken: 0.133 seconds, Fetched: 4 row(s)
但是explode函数有很大的缺陷
- 不能关联原表的其他字段
- 不能分组、排序
- 不能进行UDTF(用户自定义表生成函数)嵌套
2.lateral view
lateral view是hive中提供给UDTF的结合,它可以解决UDTF不能添加额外select的问题,其原理是lateral view类似mysql视图,将UDTF(接收一行输入,输出多行,explode就是UDTF)结果保存为一个视图(虚拟表)并和输入行进行join来达连接其他字段的select的目的。
标准语法
lateral view udtf(expression) tableAlias as columnAlias,columnAlias...
udtf(expression):使用的UDTF函数。如explode()
tableAlias:表示虚拟表表名
columnAlias:给虚拟表取的字段名,多个字段用,隔间
解决explode()带来的不足
hive (hive)> select name, friend from tbl_3 lateral view explode(friends) tmp_tbl as friend;
OK
name friend
陈小春 郑伊健
陈小春 谢天华
刘烨 章子怡
刘烨 孙俪
Time taken: 0.086 seconds, Fetched: 4 row(s)
6.2 用户自定义函数
hive中的自定义函数根据输入输出行数分为三种:
- 用户定义函数(user-defined function)UDF
- 用户定义聚集函数(user-defined aggregate function)UDAF
- 用户定义表生成函数(user-defined table-generating)UDTF
| 函数类型 | 描述 |
|---|---|
| UDF | 一行输入一行输出,如字符串类函数 |
| UDAF | 多行输入一行输出,如聚合函数 |
| UDTF | 一行输入多行输出,如膨胀函数 |
6.2.1 UDF
1.编程步骤
- 继承
org.apache.hadoop.hive.ql.exec.UDF - 实现evaluate函数,该函数支持重载
- hive中添加jar包
- 创建函数
- 使用函数
- 删除函数
注意:UDF必须有返回值,可以返回null,但不能不返回
2.具体实现
实现length()函数功能
1)添加依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
2)创建类继承UDF
package hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
@SuppressWarnings("deprecation")
public class UDFLength extends UDF {
}
3)实现evaluate函数
package hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
@SuppressWarnings("deprecation")
public class UDFLength extends UDF {
public int evaluate(String str) {
return str.length();
}
}
4)hive中添加jar包
将程序达成jar包,放入hive/lib下,这个包下jar在hive启动时会自动加载,当然也可以手动加载jar包
hive (hive)> add jar /usr/local/soft/hive-3.2.1/lib/hadoop-1.0-SNAPSHOT.jar;
Added [/usr/local/soft/hive-3.2.1/lib/hadoop-1.0-SNAPSHOT.jar] to class path
Added resources: [/usr/local/soft/hive-3.2.1/lib/hadoop-1.0-SNAPSHOT.jar]
5)创建函数
hive中自定义函数创建时可以分为临时函数和永久函数,对于临时函数仅在当前session,当前数据库起作用。
标准语法
create [temporary] function fun_name as 'package.class';
hive (hive)> create temporary function getlength as 'hive.udf.UDFLength';
OK
Time taken: 0.047 seconds
6)使用函数
根据逻辑传入一个字符串返回一个int
hive (hive)> select *,getlength(st_name) from student;
OK
student.st_id student.st_name student.st_sex student.st_age student.st_dept _c1
10001 郑楠 男 20 ES 2
10002 李娜 女 19 IS 2
Time taken: 0.145 seconds, Fetched: 2 row(s)
hive (hive)> desc function extended getlength;
OK
tab_name
There is no documentation for function 'getlength'
Function class:hive.udf.UDFLength
Function type:TEMPORARY
Time taken: 0.017 seconds, Fetched: 3 row(s)
7)删除函数
hive (hive)> drop function if exists getlength;
OK
Time taken: 0.648 seconds
6.2.2 GenericUDF
UDF类已经过时,hive推荐使用GenericUDF,该类支持更多的数据类型且效率更高
package hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
public class GenericUDFLength extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
return null;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
return null;
}
@Override
public String getDisplayString(String[] children) {
return null;
}
}
initialize初始化,可以进行参数校验,对象实例化等等evaluate业务逻辑getDisplayString显示函数的帮助信息
那么initialize里面些什么呢?打开一个GenericUDF的实现类GenericUDFCharacterLength
@Description(name = "character_length,char_length",
value = "_FUNC_(str | binary) - Returns the number of characters in str or binary data",
extended = "Example:\n"
+ " > SELECT _FUNC_('안녕하세요') FROM src LIMIT 1;\n" + " 5")
这个函数应该是韩国人写的,我们可以看他的initialize返回的是啥
outputOI = PrimitiveObjectInspectorFactory.writableIntObjectInspector;
return outputOI;
大致明白通过PrimitiveObjectInspectorFactory里的静态变量返回该函数需要返回的值,推测他的函数应该返回int类型,因此我们也可以直接返回
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
return null;
}
这个evaluate显然是优于UDF的,可是让我们函数接受任意多任意类型的值。
package hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.IntWritable;
public class GenericUDFLength extends GenericUDF {
IntWritable result = new IntWritable();
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
return PrimitiveObjectInspectorFactory.writableIntObjectInspector;
}
@Override
public IntWritable evaluate(DeferredObject[] arguments) throws HiveException {
if (arguments.length > 1) {
System.out.println("该函数暂时不支持多个参数");
return null;
}
result.set(arguments[0].get().toString().length());
return result;
}
@Override
public String getDisplayString(String[] children) {
return "获取字符串长度";
}
}
hive (default)> create temporary function getlength as 'hive.udf.GenericUDFLength';
OK
Time taken: 0.519 seconds
hive (default)> select getlength('123');
OK
_c0
3
Time taken: 3.072 seconds, Fetched: 1 row(s)
这里有坑,避免java的强制类型转换,返回值建议返回hadoop的数据类型
6.2.2 UDAF
UDAF区别于UDF是UDAF需要接受任意多个值后再进行计算后返回,因此UDAF的结构将比UDA复杂
1.编程步骤
- 函数类继承
AbstractGenericUDAFResolver、计算类实现GenericUDAFEvaluator接口 - 实现
UDAFEvaluator接口的init、iterate、terminatePartial、merge、terminateinit初始化iterate接收传入参数,进行内部迭代terminatePartial返回iterate后的数据merge接收terminatePartial返回结果,进行merge操作terminate返回最终的结果
2.具体实现
6.2.3 UDTF
实现split函数功能
1.编程步骤
- 创建一个类继承
GenericUDTF - 实现
initialize、process、close方法
发现GenericUDTF仅需要我们重写process、close两个方法,实际操作发现会报错,为什么?从GenericUDTF源码可以看出
public StructObjectInspector initialize(StructObjectInspector argOIs)
throws UDFArgumentException {
List<? extends StructField> inputFields = argOIs.getAllStructFieldRefs();
ObjectInspector[] udtfInputOIs = new ObjectInspector[inputFields.size()];
for (int i = 0; i < inputFields.size(); i++) {
udtfInputOIs[i] = inputFields.get(i).getFieldObjectInspector();
}
return initialize(udtfInputOIs);
}
@Deprecated
public StructObjectInspector initialize(ObjectInspector[] argOIs)
throws UDFArgumentException {
throw new IllegalStateException("Should not be called directly");
}
源码直接抛出异常,因此我们必须重写initialize
2.代码实现
同理查看别人怎么实现的GenericUDTFJSONTuple
纵观它的初始化逻辑很简单,numCols为方法形参数据的长度,fieldNames保存函数返回值字段名,fieldOIs保存函数返回值类型,因此我们可以写出自己的初始化,同时实现自己的逻辑
package hive.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import java.util.ArrayList;
import java.util.List;
public class UDTFSplit extends GenericUDTF {
//保存字符串分割后的数据,用于多行输出
Text result = new Text();
public StructObjectInspector initialize(StructObjectInspector argOIs)
throws UDFArgumentException {
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldOIs = new ArrayList<>();
// 这个字段最终会显示为结果的字段名
fieldNames.add("结果");
// 申明函数返回值类型
fieldOIs.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
if (args.length != 2) {
throw new RuntimeException("参数个数不匹配");
}
//第一个参数为待分割的字符串
String[] split = args[0].toString().split(args[1].toString());
for (String value : split) {
result.set(value);
//类似context.write()
forward(result);
}
}
@Override
public void close() throws HiveException {
//可以在这里实现一些关流操作
}
}
使用
hive (default)> select udtfsplit('hello_world_hello_hive','_');
OK
结果
hello
world
hello
hive
Time taken: 2.406 seconds, Fetched: 4 row(s)
七、企业调优
说实话,关于hive调优没有几年的工作经验是写不出来的,关键面试还贼爱问这个,因此就只能背了(待总结);实际生产有的不多,为什么呢?对于一般人来说,能把需求的sql写出来就谢天谢地了还祈求什么调优啊,需求都没实现拿什么调优!!!是不是。
小手一点,跳转一下 hive 企业级调优
评论区